
We all die. The goal isn’t to live forever, the goal is to create something that will.
― Chuck Palahniuk
When we achieve a modicum of success professionally it usually stems from a large  degree of expertise or achievement in a fairly narrow realm. At the same time this expertise or achievement has a price; it was gained through a great degree of focus, luck and specialization. Over time this causes a lack of perspective for the importance of your profession in the broader world. It is often difficult to understand why others can’t see the intrinsic value in what you’re doing. There is a good reason for this, you have probably lost the reason why what you do is valuable.
degree of expertise or achievement in a fairly narrow realm. At the same time this expertise or achievement has a price; it was gained through a great degree of focus, luck and specialization. Over time this causes a lack of perspective for the importance of your profession in the broader world. It is often difficult to understand why others can’t see the intrinsic value in what you’re doing. There is a good reason for this, you have probably lost the reason why what you do is valuable.
Ultimately, the value of an activity is measured in terms of its impact in the broader world. Often times these days economic activity is used to imply value fairly directly. This isn’t perfect by any means, but useful nonetheless. For some areas of necessary achievement this can be a jarring realization, but a vital one. Many monumental achievements actually have distinctly little value in reality, or the value comes far after the discovery. In many cases the discoverer lacks the perspective or skill to translate the work into practical value. Some of these are necessary to achieve things of greater value. Achieving the necessary balance in these cases is quite difficult, and rarely, if ever achieved.
 It’s always important to keep the most important things in mind, and along with quality, the value of the work is always a top priority. In thinking about computing, the place where the computers change how reality is engaged is where value resides. Computer’s original uses were confined to business, science and engineering. Historically, computers were mostly the purview of the business operations such as accounting, payroll and personnel management. They were important, but not very important. People could easily go through life without ever encountering a computer and their impact was indirect.
It’s always important to keep the most important things in mind, and along with quality, the value of the work is always a top priority. In thinking about computing, the place where the computers change how reality is engaged is where value resides. Computer’s original uses were confined to business, science and engineering. Historically, computers were mostly the purview of the business operations such as accounting, payroll and personnel management. They were important, but not very important. People could easily go through life without ever encountering a computer and their impact was indirect.
 As computing was democratized via the personal computer, the decentralization of access to computer power allowed it to grow to an unprecedented scale, but an even greater transformation laid ahead. Even this change made an enormous impact because people almost invariably had direct contact with computers. The functions that were once centralized were at the fingertips of the masses. At the same time the scope of computer’s impact on people’s lives began to grow. More and more of people’s daily activities were being modified by what computing did. This coincided with the reign of Moore’s law and its massive growth in the power and/or the decrease in the cost of computing capability. Now computing has become the most dominant force in the World’s economy.
As computing was democratized via the personal computer, the decentralization of access to computer power allowed it to grow to an unprecedented scale, but an even greater transformation laid ahead. Even this change made an enormous impact because people almost invariably had direct contact with computers. The functions that were once centralized were at the fingertips of the masses. At the same time the scope of computer’s impact on people’s lives began to grow. More and more of people’s daily activities were being modified by what computing did. This coincided with the reign of Moore’s law and its massive growth in the power and/or the decrease in the cost of computing capability. Now computing has become the most dominant force in the World’s economy.
Why? It wasn’t Moore’s law although it helped. The reason was simply that computing began to matter to everyone in a deep, visceral way.
Nothing is more damaging to a new truth than an old error.
— Johann Wolfgang von Goethe
 The combination of the Internet with telecommunications and super-portable personal computers allowed computing to obtain massive value in people’s lives. The combination of ubiquity and applicability to the day-to-day life made computing’s valuable. The value came from defining a set of applications that impact people’s lives directly and always within arm’s reach. Once these computers became the principle vehicle of communication and the way to get directions, find a place to eat, catch up with old friends, and answer almost any question at will, the money started flow. The key to the explosion of value wasn’t the way the applications were written, or coded or run on computers, it was their impact on our lives. The way the applications work, their implementation in computer code, or the computers themselves just needed to be adequate. Their characteristics had very little to do with the success.
The combination of the Internet with telecommunications and super-portable personal computers allowed computing to obtain massive value in people’s lives. The combination of ubiquity and applicability to the day-to-day life made computing’s valuable. The value came from defining a set of applications that impact people’s lives directly and always within arm’s reach. Once these computers became the principle vehicle of communication and the way to get directions, find a place to eat, catch up with old friends, and answer almost any question at will, the money started flow. The key to the explosion of value wasn’t the way the applications were written, or coded or run on computers, it was their impact on our lives. The way the applications work, their implementation in computer code, or the computers themselves just needed to be adequate. Their characteristics had very little to do with the success.
It doesn’t matter how beautiful your theory is, it doesn’t matter how smart you are. If it doesn’t agree with experiment, it’s wrong.
― Richard P. Feynman
 Scientific computing is no different; the true value lies in its impact on reality. How can it impact our lives, the products we have or the decisions we make. The impact of climate modeling is found in its influence on policy, politics and various economic factors. Computational fluid dynamics can impact a wide range of products through better engineering. Other computer simulation and modeling disciplines can impact the military choices, or provide decision makers with ideas about consequences for actions. In every case the ability of these things to influence reality is predicated on a model of reality. If the model is flawed, the advice is flawed. If the model is good, the advice is good. No amount of algorithmic efficiency, software professionalism or raw computer power can save a bad model from itself. When a model is good the solution algorithms and methods found in computer code, and running on computers enable its outcomes. Each of these activities needs to be competently and professionally executed. Each of these activities adds value, but without the path to reality and utility its value is at risk.
Scientific computing is no different; the true value lies in its impact on reality. How can it impact our lives, the products we have or the decisions we make. The impact of climate modeling is found in its influence on policy, politics and various economic factors. Computational fluid dynamics can impact a wide range of products through better engineering. Other computer simulation and modeling disciplines can impact the military choices, or provide decision makers with ideas about consequences for actions. In every case the ability of these things to influence reality is predicated on a model of reality. If the model is flawed, the advice is flawed. If the model is good, the advice is good. No amount of algorithmic efficiency, software professionalism or raw computer power can save a bad model from itself. When a model is good the solution algorithms and methods found in computer code, and running on computers enable its outcomes. Each of these activities needs to be competently and professionally executed. Each of these activities adds value, but without the path to reality and utility its value is at risk.
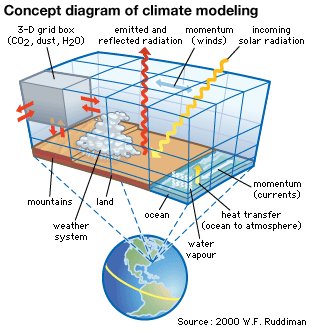 Despite this bulletproof assertion about the core of value in scientific computing, the amount of effort focusing on improving modeling is scant. Our current scientific computing program is predicated on the proposition that the modeling is good enough already. It is not. If the scientific process were working, our models would be improving from feedback. Instead they are stagnant and the entire enterprise is focused almost exclusively on computer hardware. The false proposition is that the computers simply need to get faster and the reality will yield to modeling and simulation.
Despite this bulletproof assertion about the core of value in scientific computing, the amount of effort focusing on improving modeling is scant. Our current scientific computing program is predicated on the proposition that the modeling is good enough already. It is not. If the scientific process were working, our models would be improving from feedback. Instead they are stagnant and the entire enterprise is focused almost exclusively on computer hardware. The false proposition is that the computers simply need to get faster and the reality will yield to modeling and simulation.
So we have a national program that is focused on the least valuable thing in the process, and ignores the most valuable piece. What is the likely outcome? Failure, or worse than that abject failure. The most stunning thing about the entire program is the focus is absolutely orthogonal to the value of the activities. Software is the next largest focus after hardware. Methods and algorithms are the next highest focus. If one breaks out this area of work into its two pieces, the new-breakthroughs or the computational implementation work, the trend continues. The less valuable implementation work has the lion’s share of the focus, while the groundbreaking type of algorithmic work is virtually absent. Finally, modeling is nearly a complete absentee. No wonder the application case for exascale computing is so pathetically lacking
or worse than that abject failure. The most stunning thing about the entire program is the focus is absolutely orthogonal to the value of the activities. Software is the next largest focus after hardware. Methods and algorithms are the next highest focus. If one breaks out this area of work into its two pieces, the new-breakthroughs or the computational implementation work, the trend continues. The less valuable implementation work has the lion’s share of the focus, while the groundbreaking type of algorithmic work is virtually absent. Finally, modeling is nearly a complete absentee. No wonder the application case for exascale computing is so pathetically lacking
It is sometimes an appropriate response to reality to go insane.
― Philip K. Dick
 Alas, we are going down this road whether it is a good idea or not. Ultimately this is a complete failure of the scientific leadership of our nation. No one has taken the time or effort to think this shit through. As a result the program will not be worth a shit. You’ve been warned.
Alas, we are going down this road whether it is a good idea or not. Ultimately this is a complete failure of the scientific leadership of our nation. No one has taken the time or effort to think this shit through. As a result the program will not be worth a shit. You’ve been warned.
The difference between genius and stupidity is; genius has its limits.
― Alexandre Dumas-fils
 I don’t think software gets the support or respect it deserves particularly in scientific computing. It is simply too important to treat it the way we do. It should be regarded as an essential professional contribution and supported as such. Software shouldn’t be a one-time investment either; it requires upkeep and constant rebuilding to be healthy. Too often we pay for the first version of the code then do everything else on the cheap. The code decays and ultimately is overcome by technical debt. The final danger with code is the loss of the knowledge basis for the code itself. Too much scientific software is “magic” code that no one understands. If no one understands the code, the code is probably dangerous to use.
I don’t think software gets the support or respect it deserves particularly in scientific computing. It is simply too important to treat it the way we do. It should be regarded as an essential professional contribution and supported as such. Software shouldn’t be a one-time investment either; it requires upkeep and constant rebuilding to be healthy. Too often we pay for the first version of the code then do everything else on the cheap. The code decays and ultimately is overcome by technical debt. The final danger with code is the loss of the knowledge basis for the code itself. Too much scientific software is “magic” code that no one understands. If no one understands the code, the code is probably dangerous to use. computing. The connection to work of importance and value is essential to understand, and the lack of such understanding explains why our current trajectory is so problematic. Just to reiterate, the value of computing, or scientific computing is found in the real world. The real world is studied through the use of models in scientific computing that are most often differential equations. Using algorithms or methods we then solve these models. These models as interpreted by their solution methods or algorithms are expressed in computer code, which in turn runs on a computer.
computing. The connection to work of importance and value is essential to understand, and the lack of such understanding explains why our current trajectory is so problematic. Just to reiterate, the value of computing, or scientific computing is found in the real world. The real world is studied through the use of models in scientific computing that are most often differential equations. Using algorithms or methods we then solve these models. These models as interpreted by their solution methods or algorithms are expressed in computer code, which in turn runs on a computer.
 More importantly software often outlives the people responsible for the intellectual capital represented in it. A real danger is the loss of expertise in what the software is actually doing. There is a specific and real danger in using software that isn’t understood. Many times the software is used as a library and not explicitly understood by the user. The software is treated as a storehouse of ideas, but if those ideas are not fully understood there is danger. It is important that the ideas in software be alive and fully comprehended.
More importantly software often outlives the people responsible for the intellectual capital represented in it. A real danger is the loss of expertise in what the software is actually doing. There is a specific and real danger in using software that isn’t understood. Many times the software is used as a library and not explicitly understood by the user. The software is treated as a storehouse of ideas, but if those ideas are not fully understood there is danger. It is important that the ideas in software be alive and fully comprehended. 







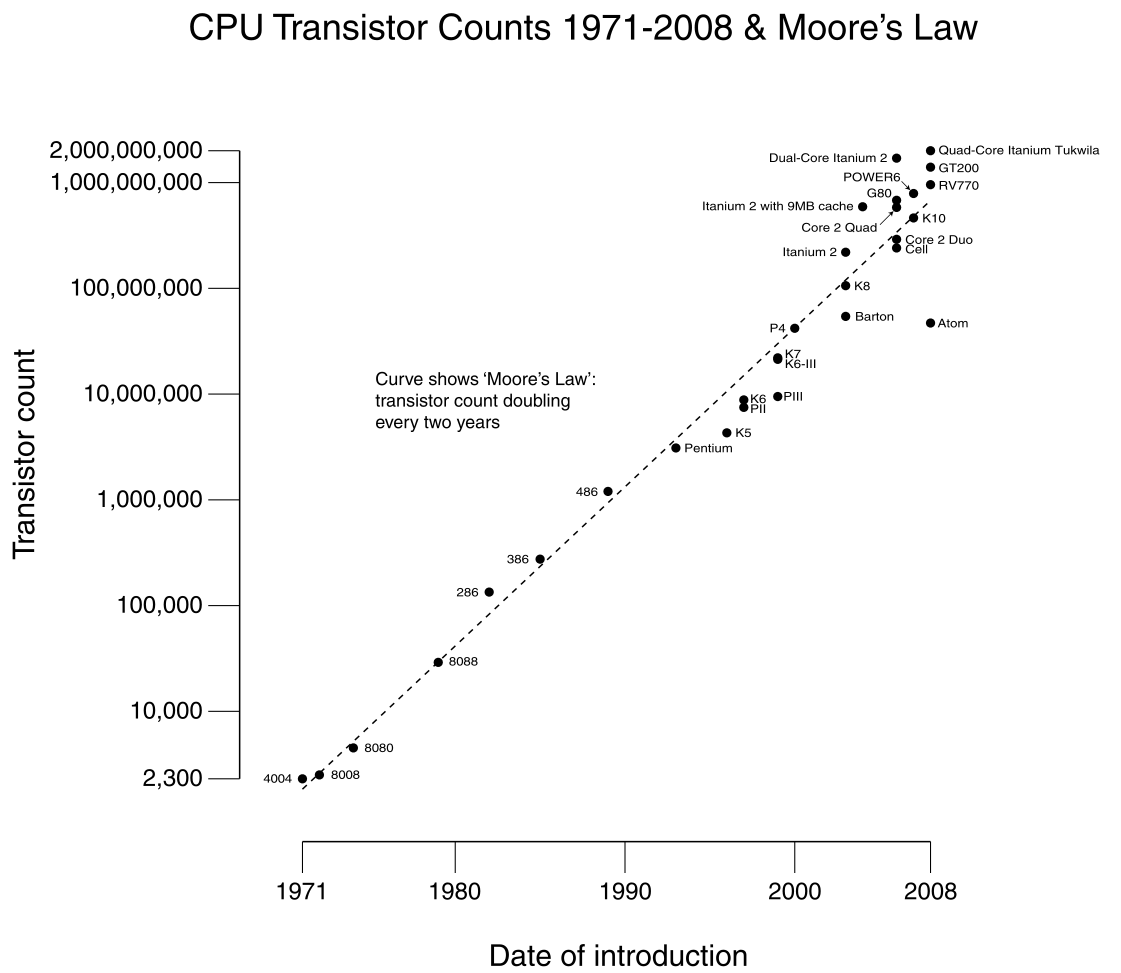
 In watching the ongoing discussions regarding the National Exascale initiative many observations can be made. I happen to think the program is woefully out of balance, and focused on the wrong side of the value proposition for computing. In a nutshell it is stuck in the past.
In watching the ongoing discussions regarding the National Exascale initiative many observations can be made. I happen to think the program is woefully out of balance, and focused on the wrong side of the value proposition for computing. In a nutshell it is stuck in the past. to hardware. As the software gets closer to the application, the focus starts to drift. As the application gets closer and modeling is approached, the focus is non-existent. It is simply assumed that the modeling just needs a really huge computer and the waters will magically part and the path the promised land of predictive simulation will just appear. Science doesn’t work this way, or more correctly well functioning science doesn’t work like this. Science works with a push-pull relationship between theory, experiment and tools. Sometimes theory is pushing experiments to catch up. Sometimes tools are finding new things for theory to answer. Computing is such a tool, but it isn’t be allowed to push theory, or more properly theory should be changing to accommodate what the tools show us.
to hardware. As the software gets closer to the application, the focus starts to drift. As the application gets closer and modeling is approached, the focus is non-existent. It is simply assumed that the modeling just needs a really huge computer and the waters will magically part and the path the promised land of predictive simulation will just appear. Science doesn’t work this way, or more correctly well functioning science doesn’t work like this. Science works with a push-pull relationship between theory, experiment and tools. Sometimes theory is pushing experiments to catch up. Sometimes tools are finding new things for theory to answer. Computing is such a tool, but it isn’t be allowed to push theory, or more properly theory should be changing to accommodate what the tools show us.
 The question is whether there is some way to learn from everyone else. How can this centralized supercomputing be broken down in a way to help the productivity of the scientist. One of the things that happened when mainframes went away was an explosion of productivity. The centralized computing is quite unproductive and constrained. Computing today is the opposite, unconstrained and completely productive. It is completely integrated into the very fabric of our lives. Work and play are integrated too. Everything happens all the time at the same time. Instead of maintaining the old-fashioned model we should be looking into harvesting the best of modern computing to overthrow the old model.
The question is whether there is some way to learn from everyone else. How can this centralized supercomputing be broken down in a way to help the productivity of the scientist. One of the things that happened when mainframes went away was an explosion of productivity. The centralized computing is quite unproductive and constrained. Computing today is the opposite, unconstrained and completely productive. It is completely integrated into the very fabric of our lives. Work and play are integrated too. Everything happens all the time at the same time. Instead of maintaining the old-fashioned model we should be looking into harvesting the best of modern computing to overthrow the old model.
 drowning in data whether we are talking about the Internet in general, the coming “Internet of things” or the scientific use of computing. The future is going to be much worse and we are already overwhelmed. If we try to deal with every single detail, we are destined to fail.
drowning in data whether we are talking about the Internet in general, the coming “Internet of things” or the scientific use of computing. The future is going to be much worse and we are already overwhelmed. If we try to deal with every single detail, we are destined to fail.
 in all the noise and represent this importance compactly and optimally. This class of ideas will be important in managing the Tsunami of data that awaits us.
in all the noise and represent this importance compactly and optimally. This class of ideas will be important in managing the Tsunami of data that awaits us.
 be solved by exotic methods and algorithms. Ultimately, these methods and algorithms must be expressed as computer code before the computers can be turned loose on their approximate solution. These models are relics. The whole enterprise of describing the real world through these models arose from the efforts of intellectual giants starting with Newton and continuing with Leibnitz, Euler, and a host of brilliant 17th, 18th and 19th Century scientists. Eventually, if not almost immediately, models became virtually impossible to solve via available (analytical) methods except for a
be solved by exotic methods and algorithms. Ultimately, these methods and algorithms must be expressed as computer code before the computers can be turned loose on their approximate solution. These models are relics. The whole enterprise of describing the real world through these models arose from the efforts of intellectual giants starting with Newton and continuing with Leibnitz, Euler, and a host of brilliant 17th, 18th and 19th Century scientists. Eventually, if not almost immediately, models became virtually impossible to solve via available (analytical) methods except for a handful of special cases.
handful of special cases. When computing came into use in the middle of the 20th Century some of these limitations could be lifted. As computing matured fewer and fewer limitations remained, and the models of the past 300 years became accessible to solution albeit through approximate means. The success has been stunning as the combination of intellectual labor on methods and algorithms along with computer code, and massive gains in hardware capability have transformed our view of these models. Along the way new phenomena have been recognized including dynamical systems or chaos opening doors to understanding the World. Despite the progress I believe we have much more to achieve.
When computing came into use in the middle of the 20th Century some of these limitations could be lifted. As computing matured fewer and fewer limitations remained, and the models of the past 300 years became accessible to solution albeit through approximate means. The success has been stunning as the combination of intellectual labor on methods and algorithms along with computer code, and massive gains in hardware capability have transformed our view of these models. Along the way new phenomena have been recognized including dynamical systems or chaos opening doors to understanding the World. Despite the progress I believe we have much more to achieve. Today we are largely holding to the models of reality developed prior to the advent of computing as a means of solution. The availability of solution has not yielded the balanced examination of the models themselves. These models are
Today we are largely holding to the models of reality developed prior to the advent of computing as a means of solution. The availability of solution has not yielded the balanced examination of the models themselves. These models are effectively. This gets to the core of studying uncertainty in physical systems. We need to overhaul our approach of reality to really come to grips with this. Computers, code and algorithms are probably at or beyond the point where this can be tackled.
effectively. This gets to the core of studying uncertainty in physical systems. We need to overhaul our approach of reality to really come to grips with this. Computers, code and algorithms are probably at or beyond the point where this can be tackled. Here is the problem. Despite the need for this sort of modeling, the efforts in computing are focused at the opposite end of the spectrum. Current funding and focus is aimed at the computing hardware, and code with little effort being applied to algorithms, methods and models. The entire enterprise needs a serious injection of intellectual energy in the proper side of the value proposition.
Here is the problem. Despite the need for this sort of modeling, the efforts in computing are focused at the opposite end of the spectrum. Current funding and focus is aimed at the computing hardware, and code with little effort being applied to algorithms, methods and models. The entire enterprise needs a serious injection of intellectual energy in the proper side of the value proposition.