“The purpose of abstraction is not to be vague, but to create a new semantic level in which one can be absolutely precise.” – Edsger Dijkstra
Two Competing Futures
The coding capabilities embedded in AI and large language models will fundamentally change what we mean by code development. The question is whether we lean toward the “glass half empty” or the “glass half full” view. The glass half empty version: we trim down and eliminate large coding teams, producing the same output with far fewer developers. The glass half full version: AI unleashes a new kind of code development. It can allow us to generate higher-value, higher-volume output where quality improvement is the main outcome. I hope for this more optimistic outcome.
In the glass-half-empty narrative, you get the same output with far fewer developers. You trim your team, cut costs, and still get the same output with fewer people. The AI does the bulk of the work, overseen by a handful of senior developers who manage the AI. The side effect is the hollowing out of the field, a reduction in the number of code developers, and cost-cutting. The output and product remain largely unchanged, and the field’s trajectory is the same as it would have been with just more efficiency. This is dismal. It is technology stagnating and damaging the future. Money is the only beneficiary.
In the other view, the picture is more complex. Success is harder and more uncertain. Expectations, duties, and tasks for code developers need to change significantly. The coding tools provide more value because each person can produce far more. The key is that people need to have greater expectations about what they produce and what they expect. The key is deep thinking. You get more code, more capability, and an accelerated trajectory for what code can produce. In this view, you supercharge the value of code development. It is a path to a better future.
“The purpose of computing is insight, not numbers.” –Richard Hamming
Change Our Thinking
“Civilization advances by extending the number of important operations which we can perform without thinking about them.” – Alfred North Whitehead
Rather than stop thinking, AI requires us to think more. We need to expect deeper and more abstract thought. This is something only people can do. What needs to change is the mentality of those managing code development. They need to break out of the straitjacket they’re in today and recognize what code development tasks have fallen by the wayside in recent years, so they can reach the full value the code should produce. This is the narrative AI needs. The other direction is a horror show for society.
This dynamic plays out across the use of AI in society. Are we using AI to get rid of work and people, or to improve the quality, improve the thinking, and improve the work that’s done? The latter is a form of abundance we should seek. It must be reflected in how society plans AI use, what it expects from it. Ultimately, it should change how we educate people and the questions and skills we teach. We need to retrain and educate most of the current white-collar workforce, too.
What’s clear is that AI overturns traditional ways of thinking, teaching, and working. We need to adapt and change to reflect what these new capabilities produce and how to improve the quality and value of what we all do. These issues are prevalent across the modern workforce. It requires a different mentality for success. Code development is the key area where we can make real progress in changing the dynamic for the better. Workers and managers have the fundamental backgrounds to achieve success. To get there, we need to understand the problems we are trying to solve and how AI can help us overcome them. Not how AI can do the same, but how it can produce better.
My View of the Current State
Let me start by sharing my experience with co-development. I worked on it on and off for nearly 40 years at two national labs. The work was always focused on features, fixing bugs, or dealing with issues. Most of the time in code development was spent writing code, getting the syntax right, optimizing, and debugging. Over the years, the deeper thinking shrank from view. The tasks became ever more banal over time. Thinking about math and physics became uncommon, replaced by computer details. As a result, our codes have stagnated. Methods, models, and algorithms have all become fixed and merely ported.
The prospect of AI changes the dynamic considerably, since the work we used to spend all our time on is now largely automated. We still have responsibilities to check what AI produces, but my experience using Claude or OpenAI code tools has been miraculous. I can execute tasks that would have taken a lot of time in a very short period, with a relatively tiny cognitive load on my part. The gift is that I can move to thinking about other, better things. I have hours and hours freed up to imagine and create. No longer am I slaved to syntax wars.
The question is: what does that free up? What new responsibilities do I have, and what can we do with this? Over time, I noticed that writing code and dealing with computer hardware took up more and more of my time. Over my career, the value of a code developer’s time has steadily decreased. This was especially true during the Exascale program. Dealing with hardware and the challenges of writing working code became more time-consuming and difficult. Work on features and improving the value and power of the code faded into the background. The focus shifted toward porting code and simply carrying along legacy code. Our dreams became smaller.
This shift paralleled a decline in the very things that give code its value: algorithms, applied math, and physics. The entire code budget went to low-value things. Code swallowed methods and algorithms. Code developers spent less and less time on those areas as computing hardware, and the lowest-level mechanics of computer science became the focus of everything. Gradually, we lost the ability to do anything new or better. Only computers got faster. What we put on those computers stalled.
Opportunity Awaits
AI offers a chance to change this dynamic and significantly improve the thinking we do in code development. This is counterintuitive. AI, rather than killing thought, allows it to flourish. The key is that the thinking for work needs to be different. This applies to other fields as well. The key is that expectations and approach need to change to reflect it. Deeper thinking, creativity, and more value in what we do should become what is expected. As a side effect, that should be reflected throughout the educational process and all the way through co-development. Rather than dragging our feet in education, there is value in fully embracing the future.
“Simplicity is a great virtue but it requires hard work to achieve it and education to appreciate it. And to make things worse: complexity sells better.”– Edsger Dijkstra
I worked in very high-end organizations. I can only imagine how much worse code development must get as you move down the food chain to lower-level organizations. If things were this bad at the National Laboratories, what is it like in the trenches of some company? We have a chance to fix this problem and start producing code with more value, ingenuity, creativity, and thought put into it. This would have a profound effect and supercharge the area where I fear the developments of the last two decades have sapped almost all of the power. To put it differently, code development is broken. AI offers us the chance to fix it.
To achieve this, we need management to recognize that the new tools can fundamentally change the trajectory of code development. It is the answer to a huge problem. If they view this mainly as a way to reduce team size or improve efficiency while still producing the same product, we will miss the opportunity. Right now, this is the narrative winning. What a waste! The value should be managed first, not the budgets.
Right now, it feels like we are on a trajectory where code development is seen as fine as-is. It is not! We do not criticize what code development has become. We should. It is a shit show. We also do not acknowledge what is missing and what we are not doing that we should be doing. Over time, code development has evolved into a low-level, low-thinking, low-planning, low-creativity environment. This is toxic, full stop. It denies everything important and good about code. Code is abstract human thinking ported to incredibly fast thinking platforms. The key is powerful abstract thought!
How to Think About AI Coding
“Computer science is no more about computers than astronomy is about telescopes.”– Edsger Dijkstra
We need to recognize that our approach to code development needs to change. It needs to reflect the power these tools provide and to unleash people to think in ways they no longer do. There is a useful analogy in the history of coding. We have a blueprint for the phase change we need to go through.
Looking back at the early days of computing (the 1940s and 1950s), computer programming involved rewiring the machine. Think of it! We started with plug boards as a coding interface. This was an advance over human-powered calculators. Then we moved to machine code and assembler, which gave us more power. Our codes and methods could be more abstract than the plug boards. When Fortran and COBOL arrived, people who were skilled in assembler saw it as Armageddon and a horrible development. The coder lost a direct connection to the machine they were so intimately connected to. What we gained was the ability to express complex ideas. Codes, algorithms, and methods bloomed. The computer was unleashed by it.
A language that doesn’t affect the way you think about programming is not worth knowing.” – Alan Perlis
The same shift is happening now with AI coding tools. We can produce code without focusing on syntax and language expression the way we used to. The thing we fail to see is what the new technology allows. Just as the new languages allowed higher-level ideas to be expressed in the past. The new coding languages ultimately influenced the algorithms and methods we could envision. We can now implement ideas that were scarcely imaginable before. This complexity and capability can fuel an explosion, but we need to trust that code developers will thinkk about even bigger ideas. We need to manage and expect more. This is the opposite of the current thought and trajectory.
Beware of bugs in the above code; I have only proved it correct, not tried it.”– Donald Knuth
This is the possibility. There are also new responsibilities, reflected mainly in the need for much more extensive and broad-based testing of the code. Since we are not writing the bottom-level code, we need many more checks to ensure that what the AI produces is understood and meets the outcomes we want. The trust prospect is essential as AI is not as trusted as compilers. Test-driven development and thinking will be essential. Testing will become an even more important part of code development. With testing we can use AI in unleashing the creative energies we have bottled up as computing hardware has become ever more complex.
“We must give the mechanical verification of programs a serious try, for it is the only credible alternative to the present practice of debugging.”– Edsger Dijkstra
Closing Thoughts
What I came to recognize by the end of my career was how badly code development was broken. It had become garbage. I saw a budget that used to pay for creative methods and algorithms that expanded the capability of codes gone. It was replaced by grueling code work focused on syntax and subtle implementation details. This was simply because computing hardware had become so unresponsive and difficult to use. The budget was completely swallowed up with this effort and the cost of porting existing codebases.
What we saw was a value of code that became fixed, with the only improvement in capability coming from the speed of the new hardware. This grim vision of the future. Not surprising that this is exactly what we see with AI and the whole data center issue. AI needs this change in approach badly.
The system needs to evolve and change so it trains the human mind in ways it alone can produce. We must understand what is unique about human thinking. How the human mind can master AI as a capable assistant and tool. Humans create new things that have never existed before, and this is humanity at its best. Code development is the obvious place to make this advance. We need leadership that sees more rather than less.
Code development reflects this human characteristic in a product. For code development to flourish, we need to expect more than just working code (correct syntax and few bugs). We need new ideas, new concepts, new algorithms, and new methods that do more and produce more than what they replace.
“There is nothing so useless as doing efficiently that which should not be done at all.” – Peter Drucker
What scares me most is the key to this transition: management.
By the time I retired and left work, the manager’s job had degraded to a massive extent. It had shifted from leadership to an endless chain of bullshit activities. The focus was on finances and battles that only gave me reasons for contempt, not respect. Managers became increasinglytechnically weak and lacked the human skills to match. They were mainly capable of handling the bullshit they were given. The management job needs to be better too.
This is part of the problem with changing code development. Managers need to think, and they need to think deeply about what they should be doing. Not simply doing the same thing more cheaply. Right now, what they are doing is generally a waste of human effort and beneath what management should do. The real 0risk is that we let managers drive this change. If they do, they will choose the glass-half-empty version of the future and look to cut costs because they have no vision of a future that could be better. They will simply fuck up this massive opportunity for a better world.
“The miracle of the appropriateness of the language of mathematics for the formulation of the laws of physics is a wonderful gift which we neither understand nor deserve.” — Eugene Wigner
I’ll start with a bit of subtext, both a boast and a complaint. All my degrees are in engineering, specifically nuclear engineering. I worked at Los Alamos for 20 years, ending up in the infamous X Division, also known as Applied Theoretical Physics. Working there gives you an honorary standing as a weapons physicist, and it becomes part of your identity. As such there is a heavy emphasis on the primacy of physical theory. By the same token math gets somewhat diminished in the Los Alamos pantheon. What is most important is recognizing when math supports the physics, impact is massive. One of the biggest problems for Los Alamos is ignoring math that matters. In its place they emphasize tradition.
One thing I’ve always appreciated is applied math. One of the greatest compliments I’ve ever received came from a coworker at Lawrence Livermore, who assumed I had degrees in applied math rather than engineering because of my knowledge of and taste for the subject. The fact that I could pass myself off as a mathematician to someone holding a Berkeley PhD in the field has always been a source of pride. I truly value applied math, which is why I see the tragedy in what has happened to it and in how it is not being used to solve society’s most difficult problems.
“Computers are useless. They can only give you answers.” — Pablo Picasso
The SIAM Journal on Numerical Analysis is emblematic of many of these issues. I was at work one day lamenting the demise of this journal. I may not have realized it at the time, but someone in the audience was an associate editor. I said something to the effect of, “That journal used to be good, and now it sucks.” I still stand by that. The utility of the journal has been replaced by academic purity, and that is extremely bad for applied mathematics. It has contributed to the field’s declining impact on the technical world.
To the point: this journal used to provide clear, evidence-based proofs, with numerical evidence that supported what could be observed in the real world. That was the essence of verification. When the journal published papers that offered practical demonstrations of the math, it made an impact. Now it has neither. It reflects an almost suicidal approach to managing a field: numerical analysis without numerical results. It can certainly be done, but it is certainly not advisable.
What has changed is that you are now left with a theorem and a proof, with any demonstration reduced to an exercise for the reader, or simply a matter of trusting the mathematics. For me, seeing that the math has real-world impact is what encourages me to engage with it: to read it, digest it, and understand it. It also gives me confidence that the mathematics is correct. This is a deeply disturbing shift in the field. It is as if they have mindfully chosen to be irrelevant.
We have seen applied math’s impact wane across broader technical fields. The example from this journal is more an indictment of the gatekeepers who have steered it toward uselessness. This is a self-inflicted injury, where academic purity has replaced the focus on being useful and impactful. I find this development truly sad and in need of deep repair. I stopped reading the journal closely. I began treating each article with suspicion: I would read the abstract, look for results, and move on if it wasn’t compelling. If I didn’t find results, it generally wasn’t worth my time.
“The purpose of computing is insight, not numbers.” — Richard Hamming
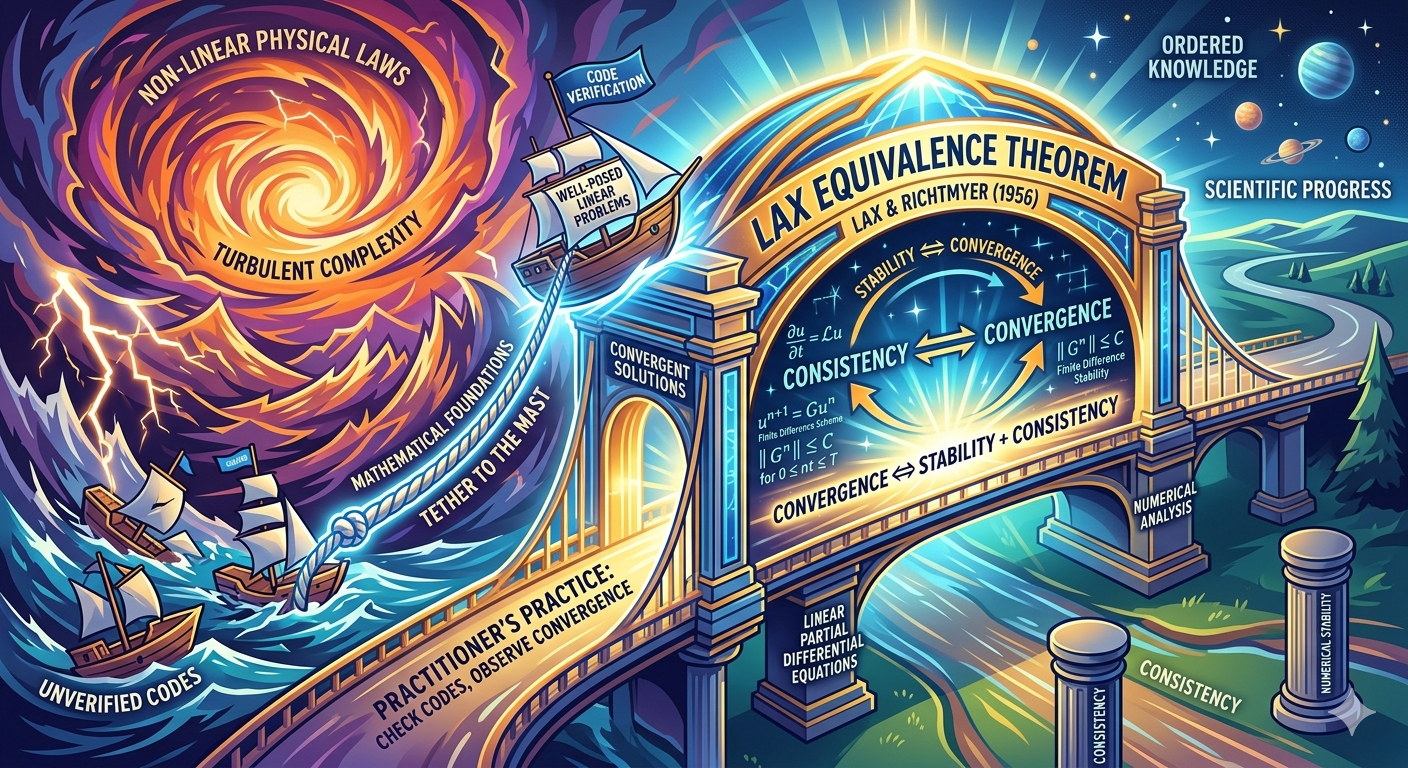
I give a talk on shock physics verification and on how many mathematical results bear directly on what you actually see. I’ve spent a significant part of my career doing verification work for various shockwave solutions. What people often don’t recognize is that there are a number ofreasonably rigorous results in shock physics. Much of this is built on foundational theory. The Lax-Wendroff theorem states that putting a solution in conservation form ensures you obtain a weak solution to the hyperbolic conservation law. The catch is that a weak solution is not unique, and it can be physically incorrect, which is why an entropy condition is needed. This can come from upwinding, Riemann solvers, or artificial viscosity. Further work by Peter Lax, with Ami Harten and James Hyman, built on this. Accuracy of the solution is a key part of verification, and for shocks a few foundational works tell us what to expect.
One is my work with Jeff Banks and Tariq Aslam on the behavior of linear waves. Those waves converge at a sublinear rate, and they typically meet the pacing accuracy requirement under mesh refinement. This builds on work by Majda and Osher, who showed that you get first-order accuracy for results emanating from any discontinuity. This applies to the Riemann problem, except for the linearly discontinuous wave, where my results with Jeff and Tariq apply. Finally, there is a result by LeFloch and Hou on what happens when you do not use conservation: the result will be wrong, and the error will be proportional to entropy production. The caveat is that entropy production is itself necessary to get a physically correct solution. This is quite a bind.
What has always astounded me is how little these results are known and used at the national laboratories where I worked. Indeed, the ignorance of this body of work, set against my own knowledge of it, played a critical role in the unethical behavior that led me to retire rather than continue working in a place where ignorance is celebrated.
What I’ve observed is that these mathematical results consistently match what we see in practice. Even though the equations are nonlinear and the methods are numerical, the connection between the mathematical theory and the observed results is clear and repeatable.
“Young man, in mathematics you don’t understand things. You just get used to them.” – John Von Neumann
This gets at one of my conundrums. The national labs I worked at tend to ignore these results and even treat them with considerable animosity. The ignorance is especially profound when it comes to computing, which is reflected in how heavily they emphasize high-performance computing. In my opinion, that approach leads to enormous wasted effort relative to investment in methods and mathematics.
One of the ironies is that the people doing verification work often remain ignorant of the math that underpins what they should expect, and as a result they lose focus. This shows up most clearly where the solutions are discontinuous, even when exact solutions are available. The fact that a method does not deliver the expected order of accuracy at a discontinuity does not mean you can stop measuring its accuracy and convergence rate, especially since those circumstances are usually much closer to what you see when the method and code are applied to real problems.
This is captured by the relative lack of emphasis on the Lax equivalence theorem. Strictly speaking, it applies narrowly, and generally to equations and methods not in use today. Still, it captures the exact requirements we apply uniformly in verification work. Why do we expect precisely what the theorem spells out in cases where it does not formally apply? And why do we dismiss it when we are not rigorously applying it? It is exactly what we expect, and exactly what we demand from our methods. We define methods that fail to meet these expectations as incorrect or full of bugs.
The big message is that some degree of rigor is lacking everywhere, and yet we still take a leap of faith forward. People generally recognize that rigor and precision are lacking in physics, particularly in important areas. The same is true for mathematics.
Verification and validation are where these gaps can be exposed and addressed. By comparing actual results to mathematical derivations, we can demonstrate the level of rigor in the mathematics. Similarly, validation can reveal the precision of the physics. Solving the equations brings these two together into a unified exercise. To understand where rigor is lacking and where work is needed, we must separate which part of the problem lies in mathematics and which lies in physics. From my experience, both areas carry significant burdens that our current science programs do not adequately address.
“As far as the laws of mathematics refer to reality, they are not certain; and as far as they are certain, they do not refer to reality.” — Albert Einstein
The Navier-Stokes equations are amazing and largely predictive, but they are imperfect. They break down in situations like turbulence. These are the places where both physics and math fall short, and real classical science is needed to fill in the gaps. I will express clear doubts that AI is a significant path forward here. I’ve written about the problems with the incompressibility usually invoked for turbulence. By all accounts it removes the discontinuous behavior the observations point to. It removes thermodynamics. Turbulence is one of the most universal means for assuring the second law in our universe.
“(turbulence is ) the most important unsolved problem of classical physics.” – Richard Feynmann
Let me strike another blow against the incompressible Navier-Stokes equation’s ability to explain turbulence. This is, of course, the Clay Millennium Prize problem. Notable mathematicians, including Terence Tao, have brought their considerable talents and intellect to the task of showing that these equations produce a singularity. That singularity is necessary to explain the observations we have regarding turbulence. This points toward the problem being posedimproperly in the first place.
The fact that it has not yielded to this assault is quite telling. Turbulence is such a universal phenomenon that I would submit that such singularities must be simple and common. They would naturally arise in the solutions. That they are so unyielding to analysis suggests that the equations themselves are the problem. The key point is that imposing incompressibility on these equations makes them unphysical. It blocks one from finding a reasonable solution that explains the phenomena. That’s what needs to be removed from the equation set. The problems with incompressibility from a physical perspective are mirrored by the mathematical challenges it creates. The incompressibility constraint makes the equations elliptic. That ellipticity is exactly what makes them so difficult. Removing it would yield conditions for a solution and the discontinuous behavior needed for the math to match physical reality.
The incompressibility constraint is the source of the mathematical difficulty. It is also the source of the physical difficulty. It renders the equation to have an elliptic character, which is contemptible both on physical grounds as well as mathematical grounds. It’s condemned from both sides. Removing it would allow the solution to include the discontinuities physical theory demands. To me, it’s obvious That it is the thing that is needed. Yet we persist in beating our heads against the proverbial wall.
“Far better an approximate answer to the right question, which is often vague, than an exact answer to the wrong question, which can always be made precise.”– John Tukey
Solid mechanics equations work well when things are well behaved, but they fail when you have fracture and spall. We need to be mindful of where the mathematics breaks down, which often happens at discontinuities. The dynamics of shocks and turbulence share significant dynamical similarity, and this might yield a path to progress. The places where the continuum breakdown are the miscrostructural details. The basic equations average over these and the small scale structure has a macroscopic impact. Models bootstrap this influence, but the models are ad hoc and unconvincing. The mysteries of physics and mathematics run through discontinuous phenomena. These are weak solutions, and much is already known about them.
One key lesson I took from my time at Los Alamos and Sandia was the importance of being a first mover in a field. This is reflected in the continued commitment to numerical methods based on von Neumann’s original vision, as refined by Richtmyer’s work on artificial viscosity. There are two elements to this, both worth criticizing in depth. The first criticism is the devotion to the Lagrangian frame of reference. It becomes increasingly absurd as virtually every physical system evolves over time. Effects we commonly attribute to turbulence and instabilities eventually undermine the Lagrangian description. They render it useless. The Lagrangian description is rooted in classical physics. The imperfections become exposed as the physics grows more complex.
Physicists are still eager to think in this Lagrangian frame because it is the core academic lineage. The numerical side of things may be even worse. We continue to use methods that have been shown to have critical flaws, as Peter Lax so keenly and ably demonstrated. Most acutely, this shows up in the failure to solve the equations in conservation form. The Lax-Wendroff theorem makes is crystal clear. I remain somewhat flummoxed by the lack of recognition of this critical flaw and the continued adherence to solving these equations in non-conservative form. The lack of progress due to this intransigence is perplexing. The right response would be to acknowledge and react to the mathematics..
The key to advancing science is recognizing the primacy of observation and theory. New technologies like computing and artificial intelligence do not displace these fundamentals. They augment them. The path forward is to make the best of this augmentation while preserving and supporting the basics. Instead we have allowed the basic to wither away.
What we have lost sight of is the importance of the fundamentals. The core aspects of understanding the universe, rooted in theoretical models. We should always remind ourselves There mathematics and its partnership with physics gains value. This partnership reaches its zenith in the practice of numerical methods for these models. The full power of AI will be most fully realized by pairing it with applied mathematics to a much greater degree than we do today.
In the future, we will see that diminishing applied mathematics in the face of these new technologies has been a serious mistake. That mistake is setting progress back. Continued emphasis on math is the way forward.
There are other places where things break down as well, such as black holes, where the continuum equations and relativity break down. Are these reallyjust discontinuities, or does physics take over? At large and small scales, the separation disappears, and one intrudes into the other. All of these gaps are the places where we need to work. Over the past several decades we have stepped away from attack on those challenges. Instead looking toward silver bullets of exascale computing or AI. Both means are useful, but do not veer toward explanation.
AI can fill the gaps statistically and projecting observations into modeling that can mimic. The thing it does not do is explain and understand the gaps. This is useful, but not an endpoint. The same holds for computing. It has utility and provides a temporary relief, but not the science. The ultimate goal of science is to explain the Universe. The place to do this is constructive physics models. These are mathematical in nature. This is where applied math is essential. It provides rigor and deep structural knowledge of the equations paired with physics. Together this provides a springboard for computing to work. This includes AI, which operates in the gaps physics and math leaves behind. The smaller the gaps, the better the understanding. This path is what we should pursue.
References
Lax, Peter D., and Robert D. Richtmyer. 1956. “Survey of the Stability of Linear Finite Difference Equations.” Communications on Pure and Applied Mathematics 9 (2): 267–293. https://doi.org/10.1002/cpa.3160090206.
Lax, Peter D., and Burton Wendroff. 1960. “Systems of Conservation Laws.” Communications on Pure and Applied Mathematics 13 (2): 217–237. https://doi.org/10.1002/cpa.3160130205.
Majda, Andrew, and Stanley Osher. 1977. “Propagation of Error into Regions of Smoothness for Accurate Difference Approximations to Hyperbolic Equations.” Communications on Pure and Applied Mathematics 30 (6): 671–705. https://doi.org/10.1002/cpa.3160300602.
Harten, Amiram, James M. Hyman, and Peter D. Lax. 1976. “On Finite-Difference Approximations and Entropy Conditions for Shocks.” Communications on Pure and Applied Mathematics 29 (3): 297–322. https://doi.org/10.1002/cpa.3160290305.
Hou, Thomas Y., and Philippe G. LeFloch. 1994. “Why Nonconservative Schemes Converge to Wrong Solutions: Error Analysis.” Mathematics of Computation 62 (206): 497–530. https://doi.org/10.1090/S0025-5718-1994-1201068-0.
Banks, J. W., T. Aslam, and W. J. Rider. 2008. “On Sub-linear Convergence for Linearly Degenerate Waves in Capturing Schemes.” Journal of Computational Physics 227 (14): 6985–7002. https://doi.org/10.1016/j.jcp.2008.04.002.
“You could leave life right now. Let that determine what you do and say and think.” – Marcus Aurelius
The last month has been a tsunami of thought-provoking events for me. The most obvious is the death of my father, my last parent. His decline had prepared me for the psychological impact, or so I thought, but it still surprised me. Mortality is a hard concept to wrap my head around. It keeps intruding into my thoughts, conscious and subconscious, with startling regularity. There is much to consider and take forward into my remaining life.
Thoughts about the meaning and value of life are profound, and they lead naturally to questions about work. I have been thinking deeply about work since retiring earlier this year, weighing what it means for me. All of this feels important to write about, even if it is uncomfortable for most people. If you are not up for it, stop reading here. I think it is something we all need to confront. head on
With mortality comes what I believe is the foolhardy belief in an afterlife. I find myself envying those who have faith and take comfort in it, even though I do not believe it exists. I wrestle with this almost daily, trying to work out what a more reasonable version of an afterlife might look like if one did exist. What kind of supreme being would be consistent with it. It all feels like comforting lies we tell ourselves to keep away from the abyss.
That abyss is why I titled this essay “Chasing Greatness.”
“It is not that we have a short time to live, but that we waste a great deal of it.” — Seneca
Around the time my dad passed away, a group of giants in computational science and CFD also died. Phil Roe, Cleve Moler, and Tony Jemeson were all about my dad’s age. Each of them achieved greatness in their careers, which is why we remember their names. I still remember giving a talk at the JRV Symposium in 2013 to honor Tony, Phil, and Bram Van Leer. I was added to the program at the end, after the presentations. I spoke right after Bram. It was an honor, but it also felt, in some ways, exceedingly uncomfortable. To some extent, Bram’s talk shocked the audience.
In retrospect, I look back at that almost wistfully, but also with caution. Bram announced that this would be his final talk. He was going blind due to the effects of his time in a Japanese concentration camp as an infant during World War II. By the time my dad died, he was blind. I suffer from the same disease he did, so I am not completely sure I will not experience blindness myself. My feelings about it go beyond simple empathy for what it does to these men, both of whom I care about in different ways. It is very personal and real to me, and frankly, a prospect that scares me deeply. Honestly, I realize now that any ambition I might have had for fame is foolish, and my time has passed. Any fame on my part was always a long shot. It is for anyone.
I don’t need to sell the fact that my father’s death was existential in profound ways. What I do need to say is that my retirement felt like a kind of death and a reminder of mortality. What comes after retirement in one’s Life? The answer, of course, is your own death. One of the most striking things about my retirement is that it felt more like a divorce than a departure from work. I still have passion, love, and even a sense of responsibility for what I do. I hope it’s obvious to my readers that I still care, have fresh ideas, and want to contribute. My retirement was more of a feeling that I needed to leave an organization and institution whose values were at odds with my fundamental values. Its morals and ethics were incompatible with my own. If I had continued, I would only feel pain and struggle, with no chance of success. I saw my managers with contempt, with all respect drained away.
“Not to live as if you had endless years ahead of you. Death overshadows you. While you’re alive and able – be good.” – Marcus Aurelius
In short, I was wasting my time continuing to work with these people. I had already realized how precious that time was, and they were not worth it. I needed to leave. I still think there is much to do, and we live in both an exciting and perilous time. The future is taking shape before us, but its fate is still unknown. We need people of genius and creative power to shape it into something we can look to with hope and the promise of positive progress. I had come to the conclusion that progress at Sandia was impossible, and it was pointless to continue tilting at that windmill. My voice, my talents, and my time were all misspent there, and each of those things would only do less with more time.
The quest for immortality is driven in part by the desire to achieve greatness in life. This is to become someone who shapes history and writes their name indelibly into the record of mankind. The desire is fleeting, but it is common. In a world of billions of people, trying to achieve greatness is utterly foolhardy. As a life objective, it is not a sign of success, but a “stretch goal.”
There is also the question of what defines “great,” which I will get to, and the role luck plays in achieving it. In a sense, I spent a great deal of my personal luck early, by getting my first professional job at Los Alamos. Los Alamos would turn out to be as close to greatness as I would ever get. I met and worked with many people there, some of whom were great, a few of them even uppercase-G Great. I am grateful for that. My own chance at greatness was probably gone from the very beginning. I am simply not lucky or talented enough.
Before I turn to the definitions of greatness and what it takes to achieve it, I want to acknowledge what I deliberately chose when I gave up any of my own pursuit of it. When I left Los Alamos in 2007, I chose a better life for the people I cherish most, and the chance to meet my responsibilities as a man, a father, and a husband. If greatness had still been my goal, I would have stayed. I would have left Sandia in 2013, around the time I turned 50, when it became clear that Sandia was not a place where anything of true value would be achieved. I made the choice for my loved ones again and again. It was simply the wrong place for me.
Greatness comes in many forms, and it is usually a mix of talent and luck. You can be great in a good way by making humanity’s future better. The examples are everywhere: Nobel laureates, inspiring leaders, writers, artists. I was particularly struck by the vision of Antoni Gaudí highlighted during the Pope’s recent visit to Spain. Gaudí’s motivations mean little to me, but his art is inspired, unique, and incredible. Visiting the Sagrada Familia was a highlight of my return to Spain last year. It was the most wonderful birthday present to share with my wife.
At Los Alamos I met a couple of Nobel laureates. I had the briefest interaction with Hans Bethe, who is surely the greatest person I have ever met in person. I also had a mostly funny exchange with Murray Gell-Mann. Arriving at work before dawn one morning, I noticed an older gentleman having trouble getting into the Theoretical Division building, so I offered to help. He handed me his badge, and when I read the name I knew he was trying to get into the right place. I badged him in, he went inside, and that was that. A humorous way to brush up against greatness in science.
More meaningfully, I connected with people who would be seen as great by most standards, if in a slightly narrower way. Frank Harlow was foremost among them. He was one of the true pioneers of CFD and someone I could count as a friend while. Frank had the virtue of entering the field early, and he used his considerable talent and artistry to create new methods. Methods still in broad use today. Methods that are the foundation of the field of CFD. He built on John von Neumann’s work, armed with the knowledge that simulating fluids was a concept that could work. It was just a matter of working out the details. Frank may be the greatest person I have ever counted as a friend.
I met many of the other greats of CFD through Los Alamos. Bram van Leer was a friend’s advisor, and I got to meet and interact with him on a few occasions. I truly enjoyed it included that JRV symposium. Also at JRV I asked Bram about the history of CFD. He had a talk called the History of CFD Part 2. I asked about Part 1. Bram quipped to me, “that’s something for you to do.” Indeed I have done this. I also co-authored some work that included Jay Boris. Both men were key figures in my essay about limiters. At conferences I had the chance to meet Sergei Godunov as well, though language and demeanor kept that meeting about as deep as the one with Bethe.
The contrast between the two laboratories in this framing is striking. Los Alamos pursues the idea of greatness, largely because of its legacy. With so many great scientists present during the Manhattan Project, it was almost inevitable that Los Alamos would become a mecca for greatness. It makes celebrating it part of its core identity. Sandia, on the other hand, is a place of teamwork and the overall effort. Greatness is submerged there. If anything, Los Alamos tries too hard at greatness and Sandia not hard enough. Neither lab has it right.
The ability to pursue greatness is, moreover, as much a matter of luck as anything else. It includes having the talent and being in the right time and place to apply it to something new and different. The opportunity for greatness usually arises when a field is being born, not after it has reached maturity.
Greatness can also come from being terrible. Hitler is great in a horrible way. He destroyed lives and killed millions, and he stands as one of the worst people in history. Jeffrey Dahmer is great in the horror, violence, and perverse deaths he inflicted on his victims. He still lives in our imagination as a great in the most awful way.
The theme of “making America great again” is true in this sense. The President is famous and memorable. In all likelyhood he will be rememberd albeit for negative reasons. He is talented in the ways of manufacturing fame. In all likelyhood he is leading the United States into a precipitous decline. Is it good to be remembered for being horrible? He will achieve greatness. People in the future will know his name. Like Lincoln and Washington, he will be remembered, but for completely different reasons.
Alexander the Great and his mule driver both died, and the same thing happened to both.” — Marcus Aurelius
It begs the question of what leads to a good life? The obvious answers run along the axes of happiness and meaning. Greatness as a concept attaches itself to meaning, not necessarily to happiness. In fact, greatness and the meaning in a life can be at odds with happiness.
When I think about myself, I choose happiness. I am a pretty happy person. I have a life full of friends, love, and meaning, and I have a great deal of respect from the people who matter to me, which means a lot. I strive to be better, but I do not let any quest for greatness undermine all those other things. Some of the great people I named above were surely happy as well. Not all of them. For some, the quest for greatness undermined their happiness. For most of them, I never knew them well enough to sort it out.
The idea of greatness and fame is all around us. I was reminded of it again by the new Marc Maron film, In Memoriam, in which a man with a terminal diagnosis becomes fixated on appearing in the Oscars In Memoriam montage. The detail that stays with me is how much fame you would actually need to be remembered ten, twenty, fifty, or several hundred years after you are gone. The amount is, frankly, ridiculous. Go far enough into the future and no one will remember or appreciate that you existed at all. All the knowledge, memory, and importance of you happen in the here and now. What happens now is what really matters. Fame is fleeting.
“Time is the great equalizer; it will claim us all.” – Shelley, Ozymandias
Knowing this is both terrifying and freeing. The terror comes from realizing that mortality is unavoidable, which means what you do with your life right now is all that really matters, and that pursuing any kind of legacy starts to feel foolish and wasteful. The freedom comes from the same fact. If the legacy is an illusion, you are released to live for the present instead of for a monument no one will visit. I try to be a good person, especially to the people I love, and to meet my responsibilities. I also try to enjoy and appreciate what I have right now.
Be not afraid of greatness: some are born great, some achieve greatness, and some have greatness thrust upon ’em.” — Shakespeare
If you want proof of how short a human life is, count how many people from five hundred years ago are still remembered. The number is very small, and those who made the list relied on luck as much as on talent. Names like William Shakespeare and Christopher Columbus come easily to mind, and that ease is exactly the point. It shows how much fame and greatness it takes to reach that kind of immortality, and how few ever do.
“To be remembered is sweet; to be forgotten is fate’s decree.” – Shelley, Ozymandias.
Children are another route people hope to take, and I am here to burst that bubble too. When I think about my own family, I know only three of my great-grandparents, and even then I know little more than their names. I know the great-grandmother from whom my middle name, Jackson, is taken, and I know of two others who emigrated from Norway and homesteaded in the western United States. That is all. Nothing further, and that thin thread of memory reaches back at most a hundred and fifty years. If I cannot hold on to my own great-grandparents, I should not expect my great-grandchildren to hold on to me.
“So many who were remembered already forgotten, and those who remembered them long gone.” – Marcus Aurelius
The deeper truth is that chasing greatness or fame head-on is usually the worst way to find it. The fame worth having tends to arrive sideways. You pour your passion and talent into making something, and then luck decides the rest: the timing, and whether the world happens to be ready for what you made. That part is not up to you. It belongs to the world and to the long odds of fame and fortune. For every famous name, there are people of greater talent who gave everything and got nothing, working in obscurity until the end. And there are lesser talents who rose simply because the draw fell their way.
“The struggle itself toward the heights is enough to fill a man’s heart. One must imagine Sisyphus happy.” — Albert Camus, The Myth of Sisyphus
“If you’ve got the truth you can demonstrate it. Talking doesn’t prove it.” ― Robert A. Heinlein,
The interview
Watching President Trump on NBC’s “Meet the Press” on June 7, I was struck by what happened. It was the perfect epitome of modern leadership. Who needs facts when you have power? Your authority is all you need. Every time Kristen Welker asked for evidence, only authority was asserted. She was supposed to wilt in the face of his authority. Failing to do so only invited rage. This exchange that ended the interview is a near-perfect specimen of proof by authority.
Here it is worth quoting at length.
Pressed on the $1.8 billion “anti-weaponization” fund and his claim that January 6 defendants were victims of “dirty cops,” Trump asserted that FBI agents had ushered rioters into the Capitol:
WELKER: There’s no evidence of that, sir. There’s no evidence of that.
TRUMP: You had a bunch of dirty cops, and frankly, what they did was weaponization of our government.
WELKER: But sir, there’s no evidence of that. More than a thousand people pleaded guilty to crimes —
TRUMP: …Try looking at the tapes one time.
WELKER: Just to be very clear, there’s no evidence of what you’re saying…
TRUMP: There’s a lot of evidence… There’s tremendous evidence. There’s nothing but evidence.
WELKER: Well, it’s not been presented in a court of law.
TRUMP: The election was rigged. It was a dirty election… And it’s happening again right now in California.
WELKER: Do you have evidence to support that?
TRUMP: All I have to do is look. All I have to do is look.
WELKER: But that’s not evidence.
“All I have to do is look” is the entire epistemology of proof by authority compressed into seven words. The claim is true because the authority perceives it to be true; demonstration is beneath him. When the demand for evidence persisted, the response was not evidence but dominance:
TRUMP: They’re crooked just like you’re crooked, your press is crooked. And Meet the Press is crooked.
WELKER: To be fair, I’m not crooked. But let’s continue.
TRUMP: Really? Well, you play right into their hands then… You’re either crooked or you’re stupid.
Moments later, he tore off his microphone, declared, “You’re a one-sided crooked network. Sorry. Let’s call it quits because I’ve had enough,” and walked out. Asked for any evidence eight separate times, the President of the United States produced none. He produced insults, an assertion that looking is the same as proving, and finally a tantrum. The proof is non-existent. What exists is the power, and the power is the only authority that matters..
The same disease, closer to home
One of the great commandments of science is, ‘Mistrust arguments from authority.’ Too many such arguments have proved too painfully wrong. Authorities must prove their contentions like everybody else.” — Carl Sagan
Few leaders or experts can match Trump’s manic devotion to lying. The underlying mechanism is one I watched daily at work, and it helped push me to retire. The leadership I knew were “experts” in science. Some, even with actual accomplishments to point to used their position to dominate. They insisted their views be accepted even when wrong and refuted by evidence. They ignored evidence. When evidence was asked of them, they responded with power. Not really different from the way Trump responded to Welker. Just less colorful and childish. Who needs evidence when you’re in charge?
Most of the time the leaders are not promoting self-serving conspiracy theories as Trump does. I will touch on self-serving promotion of falsehoods below. They are telling us they are doing a great job and everything is going great, when this is not true. They are promoting their own success while suppressing any talk to the contrary. Most leaders will point to selective evidence to support their view. “The stock market is at an all time high.” Meanwhile any evidence to the contrary is ignored. At work this looked like only mentioning positive things while avoiding problems. This is not leadership. This is marketing. It almost always tips over into bullshit.
Many people submit to this even when what they see directly contradicts the claim. I saw it every day. The constant stream of bullshit, lies, and false claims promoted by leadership wears resistance out. Even when backed by no evidence and, often, no relevant expertise, This was corrosive to any responsilbe conduct. Being the one who said “there’s no evidence of that, sir” carried the same cost it carried for Welker. I was called out. Made an example of and singled out for punishment.. It is better for your career to support the lie. Accept the bullshit as the truth. Consequences of this are sure to be terrible.
Experts do it too
“Science is the belief in the ignorance of experts.” — Richard Feynman
Acknowledged leaders in many technical fields practice a politer version of the same disease. I wrote recently about direct numerical simulation (DNS). In DNS, you almost never see evidence that a result is, in fact, a valid direct numerical simulation. Error analyses are almost never presented. When they are, the discussion concerns statistical convergence, almost never numerical convergence. You see a flow solution and a description of the method, but no estimate of the actual numerical error. The result is a worse facade: DNS presented as an exact solution. A perfectly good and detailed replacement for actual experiments. “All I have to do is look” (at the pretty turbulent flow field) is the implicit argument. It is no better coming from a chaired professor than from the President.
Any expert worth their salt should have evidence at their fingertips. Command of a field should include command of the evidence supporting your claims. Consider a maxim everyone accepts in principle: errors should be estimated. Every experimental standard says measurement and statistical uncertainties must be reported. In practice they rarely are. The standard is honored in name only, proof by authority with a peer-reviewed veneer.
The deeper problem for these leaders and experts is that evidence works against them. Often they cannot provide it because they do not have it; when they do have it, it undermines the claim. Politicians whose policies fail market a success that does not exist rather than change course. Experts who built reputations on their life’s work cannot admit the problems that remain, so they present that work as the final answer. The result is the same in both cases: declining legitimacy, suppressed progress, and eventual failure. Turbulence modeling and DNS are a clear example: decades of little real progress, while the experts promote their success and starve the work that could deliver actual breakthroughs.
Why now?
“In God we trust; all others must bring data.” — attributed to W. Edwards Deming
Why has this become so prevalent? I have theories rather than an answer. Part of it is the collapse of trust in experts. People increasingly see them as full of shit, and the experts’ own behavior keeps supplying the evidence (the one kind of evidence they reliably produce). Part of it is that the internet’s “do your own research” reflex goes unanswered by the gatekeepers. That reflex cuts both ways: it is healthy when it holds gatekeepers accountable. It is toxic when the gatekeepers are themselves the problem, because real standards are also what weed out the charlatans.
The current administration is the limiting case. It is an organization in which genuine expertise is an impediment to advancement, staffed top to bottom by charlatans, liars, or both. Where this kind of leadership takes hold, reality eventually collects its debt. It eventually collects that devt from society at large, savagely.
The Bottom Line
“The fundamental cause of the trouble is that in the modern world the stupid are cocksure while the intelligent are full of doubt.” — Bertrand Russell
Trump’s behavior is over the top and a hyperbolic manifestation of poor leadership. That is precisely the lesson: Trump-style leadership, while awful, is not an anomaly. It is not isolated. It reflects deeper societal problems. Leadership across our institutions is unfit for success, and it will produce decline in everything we allow it to touch.
When a simple request for evidence is met with fury, the weakness of this leadership is laid bare. That reaction is exactly why science isin decline: evidence yields clear conclusions. When those conclusions contradict what leaders want to project, the evidence is dismissed. Many leaders in our technical and scientific institutions push back against V&V for the same reason, the evidence it produces undermines the message they are selling.
The deeper problem is that a significant number of people will believe whatever a leader says, even when the evidence contradicts it. They do not need evidence, and they do not demand it. I saw this at Sandia, where most people accepted what leadership told them and ignored what they could see with their own eyes. Even when their lived experience opposed the leader, belief was granted. As I discovered, these leaders will not accept any resistance.
Trump is the hyperbolic version of the same story. Occam’s razor, applied to the record, points to a habitual liar, prone to outbursts and capable of criminal or criminal-adjacent conduct. He has a long history as a grifter, and a civil jury finding of sexual abuse. His followers ignore all of it and believe him on the strength of his business image and his position. The presidency compounds the effect, since people tend to take a president’s words at face value. The pattern repeats across society with business leaders like Elon Musk being a prime example. Their position is the only proof some people demand. We will get the outcomes we deserve.
The path to better leadership is to celebrate success while acknowledging and attacking problems. Problems are not solved by being ignored; they are solved by being confronted. This is the path we are failing to choose. Leaders who celebrate success and sidestep problems do not make the problems disappear. The problems remain, and they compound. Today’s leaders believe they can defer the hard problems to someone else. That is cowardice, and it is a road to ruin.
Transcript excerpts from NBC News, “Meet the Press,” June 7, 2026.
“What can be asserted without evidence can also be dismissed without evidence.” — Christopher Hitchens
“The real purpose of the scientific method is to make sure nature hasn’t misled you into thinking you know something you actually don’t know.” ― Robert M. Pirsig
My thoughts on how machine learning (ML) fits into science are shaped by the question of how simulation fits into science. In the past, I have made my views on that clear. Modeling and simulation does not change science in any fundamental way. It is just a tool to do science better. ML or AI are the same. Useful tools for better science, but science is unchanged.
The scientific method remains solid. This is a core message: science is unchanged. You just have new tools to conduct it. These new tools offer new, potentially better ways to do the same work. They offer new avenues for engaging and improving parts of it. You still have theory and observation as the base of science. Now one has more effective and more broadly applicable computational tools to navigate that space. These new tools can apply to vast datasets produced by observations or simulations. They offer new perspectives or uses of data that could improve science.
As I have said before, the key to navigating this properly is the habits and practices of verification and validation. I have argued that verification and validation are the scientific method structured for modeling and simulation. For ML and AI the same maxims apply here. For ML and AI, the details need to be sorted out differently. These techniques carry a different set of key technical practices and issues, and V&V should be adjustedaccordingly. Most notably the role of theory and mathematics is fundamentally different. The math for ML-AI is vastly different and less rigorous than modeling and simulation. That is the topic I will take up in the following post in an expanded form.
A good starting point is the subject of my last post: Direct Numerical Simulation (DNS). DNS is often promoted as the gold standard of modeling and simulation. It is supposedly so good that it can replace experimental data, which would be amazing if we could actually do it. Current practice is not up to this end. The same issue is doubly true for ML-AI. Without a great deal of improvement and better quality these won’t be silver bullets.
The history of science, like the history of all human ideas, is a history of irresponsible dreams, of obstinacy, and of error. But science is one of the very few human activities — perhaps the only one — in which errors are systematically criticized and fairly often, in time, corrected. This is why we can say that, in science, we often learn from our mistakes, and why we can speak clearly and sensibly about making progress there.” ― Karl R. Popper
That means DNS should face a very high bar for success. As I wrote, the work usually does not clear that bar. A big part of clearing the bar is entering into the sudy with doubt and uncertainty. There is typically very little analysis of whether the model equations are appropriate. Next, on whether the simulations are numerically accurate. Error analysis is at the heart of science, and that heart is largely neglected in DNS practice. ML and AI are the next fields to commit these same sins. Science is largely the study of error. Without it, the claims of science are weak.
One key question about these new tools is whether they replace parts of science that already work. Experimental and observational science remain essential to everything. They connect to objective reality. This should remain central to everything. The theory of physics, and the use of mathematics to model it, is another area where science works well. We should recognize the shortcomings in both and shore them up with new techniques. Nothing points to discarding either. As a new numerical method, or instrument improves science, AI and ML can be the same. A better tool for engaging with the same science.
AI and machine learning rely on data, which can come from observations, experiments, or simulations. it is often available in vast quantities. More with each passing year. The lack of any characterization of error and uncertainty in these data sources is one of my most consistent complaints about current practice. In almost every example I have seen, error and uncertainty are ignored rather than treated as part of training or of using these tools for science. This should be completely unacceptable, yet I see little progress toward addressing the flaw. Moreover, we should know whether the processing or use of the data expands or contracts the errors.
“Essentially, all models are wrong, but some are useful.” – George Box
One thing that is consistently missing is a commitment to evidence. This holds even for experimental data. Error is often absent or buried from the view of the consumer. This is odd as error estimation in measurement or phenomenology is well defined and expected. The standard is simply not exercised. In computation, the practice is much worse. I pointed this out for DNS, but the same is true across the field. When this happens the implicit effect is to substitute a value of zero for a true analysis. Notably, the lack of analysis and disclosure means the smallest value is used. This is intrinsically dangerous.
One area where I focus a lot of energy is the quality of shock tube solutions. These solutions are exact and come with a precise error estimate. Yet the accepted practice across the community is to not display those errors. We are offered purely qualitative results. There is little reflection on this. It is simply what I call “Hello World” for the field. It is really a quiet sad state of affairs. The result is an unconscious stagnation, where we show qualitative results, give a thumbs up or thumbs down, and move on. No evidence is provided about the error or efficiency of the methods. It is common in other parts of computational science. We see the same trend in machine learning and AI.
“Science, my boy, is made up of mistakes, but they are mistakes which it is useful to make, because they lead little by little to the truth.” ― Jules Verne
Over my career, I watched the rise of V&V, driven by the promise of doing high-consequence work with the quality and evidence that supported its use. This spirit rose and fell in less than a decade. After that, I saw roughly a 20-year pullback, as the evidence was deemed too expensive, too difficult, and insufficiently positive to power the marketing our programs needed. Evidence and doubt are essential for science. They are anathema to marketing. Our institutions are mostly marketing with very little science.
That period coincided with V&V providing genuine assessments of techniques and science. Such assessments often highlight problems and areas for further work. This powers the advance of science. It is not the success message our programs seem to require in today’s untrusting environment. As a result, V&V has largely become a way to launder results and supply the positive messaging that supports funding. This is the only thing our management and institutions seem to care about today.
AL and ML are now being added to this toxic mixture. AI and machine learning need the spirit of quality and assessment far more than modeling and simulation do, even more than DNS does. Without it, the likely outcome is an endless parade of hallucinations and bullshit. These will be presented as silver bullets for every kind of problem, while amounting to nothing more than illusions of progress. For applications and decisions of high consequence this is a disaster waiting to unfold.
Right now, everyone is lined up at the trough of money around AI and ML. They are just wanting to feed. Very little proof is needed, and even less is desired. I fear this lack of appetite for V&V is a tell about how little faith people actually have in the work, and an implicit understanding that the evidence will not be positive. Not wanting V&V, or evidence of the error structure in science, is a clear sign that, deep down, people know they are engaged in bullshit. They know that at some level V&V will expose them as liars. They are offering the illusion of precision without being willing to put up the evidence that would demonstrate it.
“The first principle is that you must not fool yourself, and you are the easiest person to fool.” – Richard Feynman
So what should ML and AI do for science, and what should they not?
The way to decide is clear: look at these new tools through the lens of the structure of science. The structure that is invariant to the tools used.
We start with experimental and observational science, then move to theory, which is often mediated through modeling and simulation. ML offers fantastic ways to augment experimental and observational science by analyzing data. This is especially available in vast quantities gathered in new ways. This path also points toward how ML can affect theory. Most notably whether there are trends or aspects of the data that currently resist structured explanation. ML offers new ways to represent and navigage poorly understood aspects of vast datasets.
The same pattern holds for modeling. There are aspects of our world that our existing models do not capture, and these gaps in current theory are exactly where the new tools can reside. In the best case, these ML results will themselves be replaced by structural understanding as much as possible. If a standard structured theory is available, ML is surplus to requirements. That is the frontier we should push on. In the end, if we gain understanding through modeling, the need forML decreases. We will always have areas we do not understand, or that are not amenable to the modeling tools we currently have,. In that sense ML can augment our understanding.
The more controversial point is where these tools have no business playing at all. I have seen plenty of papers aimed at the well-structured, well-posed mathematical parts of a system that ML is trying to replace. That strikes me as utterly ludicrous. If something is well understood, well posed, and well constructed mathematically, ML has no business operating there. It should operate where our theory and methods fail, not where they succeed.
Conservation laws are essential, but they are not always precise, and this matters for machine learning. Conservation of mass, for example, is sacrosanct. As soon as you move to the momentum or energy equations, constitutive modeling starts to play a key role. This is where ML can start to engage, That is especially true in multi-phase flow, where constitutive modeling is woven into nearly every part of the methodology. Parallels exist across different modeling problems.
ML fits into the gaps around constitutive modeling and its variations. Another such area is the setting of initial and boundary conditions for calculations. Our current methods do not fully capture these impacts. Where there are substantial sub-grid effects below the macro scale, ML and AI can help fill those gaps and improve the performance of the methods we use today. The key is to recognize where tools have the potential to address poor aspects. It is also essential to avoid displacing places where the methodology is not improved by these new technologies. Right now, this discernment is lacking.
“The purpose of computing is insight, not numbers.” – R. W. Hamming
“Your life is not a simulation; it’s the real game. Play wisely.”― Richelle E. Goodrich
Direct numerical simulation (DNS) is one of the most powerful uses of our vast computing power. With that power comes great responsibility. That responsibility is currently not being met by the vast majority of practitioners. The common issue is a lack of attention to accuracy. This is basic quality control.Some of what gets called direct numerical simulation is nothing more than marketing for the extremely expensive, powerful computers. Marketing because we spend so much time and money on them.
Numerical simulation in general is not practiced with the care its promise deserves. That promise is access to vast quantities of precise data that rival experiments in their power to unveil the mysteries of the universe. Much of the problem comes down to verification and validation. These activities are essential for ensuring the quality of computations. As a rule, DNS does not lend itself to high-quality verification and validation (V&V). Instead, they rely on rules of thumb and expansive claims about accuracy. Many of the people who consume DNS results treat a DNS as equivalent to a declaration that the results are exact. This is a patently absurd notion that should be rejected reflexively.
I have written about this before, and I will reiterate some of the main points here. Over the past ten years, I have encountered these practices more frequently, engaged with some of the most prominent practitioners, and gained perspective. It is also worth mapping perspectives on DNS onto the claims now being made about AI. As it turns out, the two subjects are closely connected. The hubris and the sweeping claims surrounding DNS feel like a reflection of the hubris and the sweeping claims about AI.
“The simulation had now become indistinguishable from real life.”― Ernest Cline
Questions about the legitimacy and accuracy of DNS are best framed in two ways. First, whether the physical laws being solved to high accuracy actually describe the physical phenomena of interest. Next, does the accuracy of the numerical treatment meet requirements? Second, the numerical treatment itself. Numerical solutions to the equations of physics, typically partial differential equations, are intrinsically approximate, and those approximations carry errors. In general, both the physical model and the numerical method are assumed to be highly accurate. It is damning that the errors associated with them are rarely, if ever, estimated and reported as part of a DNS study.
A good place to start is the most common and well-known version of DNS: Navier–Stokes fluid turbulence. This is the practice that made DNS famous, and it is often the most well-developed approach. As a result, it also exhibits almost all of the common pathologies. Both the good practices and the pathological ones deserve discussion, because the latter probably require more care than they are usually given. The habits of research communities often run counter to better practice, and they can encourage some of the more egregious examples of overreach and missing quality control.
“The Navier-Stokes equation probably contains all of turbulence.” – Uriel Frisch
This form of DNS begins with the widely accepted contention that the incompressible Navier–Stokes equations contain all of turbulence. Uriel Frisch states this explicitly in his book Turbulence. I think the claim deserves more scrutiny than it gets. For one thing, all of these physical laws are to some degree approximations of continuum behavior, behavior that is itself non-continuum in nature. The deeper problem is that incompressible flows do not exist in nature. There is no such thing as an incompressible flow. This is easy to see: an incompressible flow implies an infinite sound speed, or, as a friend from Los Alamos used to quip, superluminal sound waves (sound traveling faster than light). What incompressibility really does is eject thermodynamics from the system of equations in any meaningful sense. Given that fluid turbulence remains a mystery, throwing thermodynamics out of the equations seems more than a little foolish.
“The law that entropy always increases holds, I think, the supreme position among the laws of Nature. If someone points out to you that your pet theory of the universe is in disagreement with Maxwell’s equations – then so much the worse for Maxwell’s equations. If it is found to be contradicted by observation – well, these experimentalists do bungle things sometimes. But if your theory is found to be against the Second Law of Thermodynamics I can give you no hope; there is nothing for it to collapse in deepest humiliation.” ― Arthur Eddington
The folly runs deeper when you consider some of the best-known facts about turbulence. The first is the broad acceptance that turbulence has, in some form, a singularity associated with it. Proving the existence or non-existence of that singularity, whether smooth solutions exist for all time, is the essence of one of the Clay Millennium Prize problems. The singularity is seen most clearly in the famous Kolmogorov four-fifths law, which shows that as viscosity goes to zero, dissipation approaches a finite value. The compressibility that has been ejected from the equations is precisely a mechanism by which a singularity would naturally form; this is the same way one forms in standard compressible flow.
It would be a genuine irony if it turned out that turbulence has little or nothing to do with the incompressible flow equations. This would then mean that the Clay prize itself is meaningless. The solution would simply be an oddity of higher mathematics. The non-solution to the problem is probably telling us something! It would then be nothing more than the study of a challenging and oddly difficult class of equations that were believed to have physical significance, but in reality had little, other than as a useful approximation for a broad class of flows that does not include turbulence.
One key feature of compressible flows is the presence of a clear, phenomenological structure that leads to the formation of the singularities the four-fifths law points to. The same structure and dynamics appear in shock wave formation and propagation. The dissipation, or entropy creation, rates are functionally similar, being cubic in the difference in longitudinal velocity. The main difference is that compressible flow has a theory that only works in one dimension, whereas turbulence is a three-dimensional theory. What you have in turbulence is a field looking futilely at a horrendous physical system, incompressible Navier–Stokes, while pushing aside an obvious solution to the problem, compressible Navier–Stokes.
What we have is the pursuit of an essential physical theory using a system of equations that combines hyperbolic, parabolic, and elliptic forms, and that refuses to yield to the most powerful mathematical analyses available to mankind. We still do not have any constructive proof of a singularity. By removing the unphysical aspect of this system, the divergence-free velocity, we get singularities forming naturally. This is a well-posed system that matches the kinds of singularities and rate-of-production behavior we expect from theory and experiment. Frankly, it boggles my mind that we continue to pursue this theory down the incompressible rat hole.
Incompressibility removes sound waves from the equations, and it also removes thermodynamics. The key point is that sound waves are the precise physical mechanism in compressible flow that produces singularities. That is the other essential nonlinearity that the incompressible flow equations make completely degenerate. Frankly, it is no wonder we have failed to make real progress in nearly a century. This is the first and perhaps most important objection to current DNS practice.
The second concerns the numerical methods and the integration of the equations. The prevailing standards rest on rules of thumb established in the foundational channel-flow simulations of the early-to-mid 1980s, with resolution set relative to the Kolmogorov length. These give rough accuracy bounds; a stated error on the order of five percent is commonly used to set resolution. This is best defined in Moin and Mahesh’s review paper of 1998. It deserves more scrutiny. The current rules of thumb produce flows that look reasonably well resolved, but there is no well-established sense of the error. Usually, there is no real knowledge of the numerical errors incurred in integrating a DNS. To put it bluntly, error bars do not exist for these calculations. Where error bars do appear, they almost always reflect the statistical convergence of computed quantities, not the numerical error of the solution.
“This defines the minimum scale, the size of the smallest feature in the flow.” – Henshaw, Kreiss & Reyna
The Kolmogorov length is an energy-norm scale that marks where dissipation occurs in a turbulent flow (L2 norm). To say the least, it yields a fairly optimistic view of how computational effort scales with Reynolds number. Others have taken even more pessimistic views, most notably Kreiss, who worked from an L∞-norm length scale. The question is what is the necessary scale to resolve? That estimate puts detailed simulation of turbulence completely out of reach for any meaningful Reynolds number. This may well be the right view, if singularities are the heart of turbulence and the proper focus of any DNS. If turbulent flows are weak solutions perhaps a L1 norm view would be appropriate. My fear is that it is true: that the resolution of singularities in turbulent flow is exactly the secret we are missing, and the breakthrough we so badly want.
Now consider the cultural side of DNS practice. The published literature, and the credit for contributing to our knowledge of turbulence, is driven by computing DNS at the highest Reynolds number possible. That pursuit leads to corner-cutting and less care, which works directly against the questions raised above and against the error estimation and quality assurance the field so badly needs.
The field needs high quality because DNS is so often used to replace or augment experimental data. When computation stands in for experiment, it should be held to the same standards as experiment, the same rigorous procedures. Actually arguably to higher standards, since this is a man-made source of data. In almost every respect the opposite is true. DNS is simply assumed to be like experimental data, only more copious and easier to obtain, at least once you have the high-performance computing needed to produce it.
The same trends appear in other fields that use “first-principles” calculations to do DNS. In molecular dynamics, for example, potentials are used to describe the behavior of molecules. These potentials are highly accurate, but still approximate and imperfect, compact descriptions of the physical behavior rather than the behavior itself. The same mindset prevails: the prize goes to the biggest, most expansive, largest-scale simulation one can achieve. All of it works against the pursuit of quality. V&V is largely absent and surplus to requirements.
“It takes less time to do a thing right than to explain why you did it wrong.”― Longfellow
Finally, you reach the ragged edge of what gets called DNS. These are the simulations that are largely marketing exercises on the part of institutions looking to promote themselves. Here a DNS is simply a very large-scale calculation.
I have seen a great deal of this at the national labs, where you will find a code solving the Euler equations together with some other combination of physics to produce a very expensive, very detailed model of some system. It gets promoted as a DNS purely on the strength of the computing resources consumed. The calculation is enormous, and it is called a DNS by virtue of being massive.
This is not to say such exercises are useless. Calling them DNS does a disservice to every other DNS, and lends them an air of legitimacy and truth they have not earned. They are best understood as exploratory attempts to explain complex phenomena, a worthwhile and valuable use of computing, but not direct numerical simulation. What they really are is marketing, for the very expensive computers and the very expensive programs these laboratories are engaged in. That institutions get away with it calls into question the nature of peer review and the quality of the broader scientific enterprise they are part of.
All of this brings us full circle, back to ideas related to AI. The current push for computing at a massive scale is focused on AI, and you have the same claims that massive quantities of data and computing lead to some sort of magical access to the truth. Fortunately, we have already seen through this, in the much-noted discussion of how often large language models hallucinate and tell falsehoods. That is largely a positive thing to consider going forward. We see the problem; now we need to solve it.
A deeper issue to consider is whether the hallucinations we see in AI are also present in DNS. Do DNS results hallucinate as well, and if so, how do we find them? In both cases, identifying and eliminating these hallucinations is a key technological advance worth pursuing. Given the economic, political, and national security consequences of AI, that pursuit moves over into something much closer to a life-and-death struggle.
There is a clear path forward for both DNS and AI. This is V&V and lots of it. The approach to making progress is straightforward, even if the work is detailed, technically demanding, and requires handling uncertainty and the fidelity of calculations. That is why we fund research in the first place, right?
In both areas, the first priority should be genuine measurement and testing of accuracy, with a clear understanding of the error uncertainty and the computational cost. This applies whether we are dealing with DNS of turbulence or a LLM. Developing this accuracy is essential, because it is not simple to measure and has multiple layers.
“A brand that feels human earns something no algorithm can replicate: trust” ― Warren Kornblum
Efficiency is the second key factor. In other words, how much computing cost is needed to achieve a certain level of accuracy? To know the efficiency, knowledge of accuracy is essential. In the AI case, for example, the cost per token has become a problem. The recent approach to tokenmaxxing has led some companies to withdraw support for AI and reassess its utility and value. This is positive, if we focus on improving efficiency and avoid trying to solve problems by throwing more and more computing power at them. How efficiently and effectively we use the computing power we have matters greatly, and this has been a problem across computational science.
“There is nothing so useless as doing efficiently that which should not be done at all.” ― Peter F. Drucker
Ignorance of accuracy and efficiency has led to stagnation in methods and methodology. This comes with an attitude that says, “Methods are done, there is nothing to do here.” Nothing could be further from the truth. This stagnation is antithetical to progress. We see it in the quest for high-resolution methods, where an obsession formal high-order accuracy has killed the ability to develop more efficient, more effective methods. There we never measure accuracy on practical problems. In either case, the joint focus should be on the accuracy and fidelity achieved on practical, real-world problems, using idealized problems only to guide us. Only using idealized problems where accuracy there can be directly tied to accuracy in the real world.
Brute-force computing is an amazing thing to have. What has become clear is the vast cost of that computing. It is becoming a huge technical and political issue. We should feel duty-bound to use it as effectively and efficiently as possible. This pursuit of efficiency should be a unifying principle across the world of computational science, driving important, real-world impacts.
We should also recognize that the pathologies of high-performance computing that have consumed computational science for the past decade or more are now being inherited by AI. The whole notion of data centers is the sharp end of the spear here. The AI world needs to be more mindful about using that computing power efficiently and effectively. The unfortunate thing is that there is an obsession with raw computing power, without regard for the efficiency or the accuracy that results from its use. This has been a plague on the field, and it needs a correction sooner rather than later.
“People don’t buy what you do; they buy why you do it. And what you do simply proves what you believe”― Simon Sinek
References
Bethe, H. A. “The Theory of Shock Waves for an Arbitrary Equation of State.” Office of Scientific Research and Development, Report No. 545, 1942.
Frisch, Uriel. Turbulence: The Legacy of A. N. Kolmogorov. Cambridge: Cambridge University Press, 1995.
Henshaw, William D., Heinz-Otto Kreiss, and Luis G. Reyna. “Smallest Scale Estimates for the Navier–Stokes Equations for Incompressible Fluids.” Archive for Rational Mechanics and Analysis 112, no. 1 (1990): 21–44.
Kolmogorov, Andrey Nikolaevich. “The Local Structure of Turbulence in Incompressible Viscous Fluid for Very Large Reynolds Numbers.” Comptes Rendus (Doklady) de l’Académie des Sciences de l’URSS 30 (1941): 301–305.
Menikoff, Ralph, and Bradley J. Plohr. “The Riemann Problem for Fluid Flow of Real Materials.” Reviews of Modern Physics 61, no. 1 (1989): 75–130.
Moin, Parviz, and Krishnan Mahesh. “Direct Numerical Simulation: A Tool in Turbulence Research.” Annual Review of Fluid Mechanics 30 (1998): 539–578.
“The scientific paper in its orthodox form does embody a totally mistaken conception, even a travesty, of the nature of scientific thought.” – Peter Medawar
A limiter is an intervention that steps into a numerical method, examines the data, and prevents the method from doing something unphysical, bad, or dangerous. The determination is based on focusing on the monotonicity of data to produce “safe” solutions. The first limiters were ad hoc, but they gained rigor over time. This is clearest with the TVD theory by Harten. A limiter acts when the solution the method would otherwise choose is going to cause harm, i.e., oscillations. In that moment it adaptively selects a less accurate method in exchange for a safe, robust solution.
Limiters are a major change in how numerics work. We had always solved nonlinear equations, but with limiters, we suddenly had nonlinear methods, and those methods were powerful. Before limiters, you had a choice between two poor options: accurate solutions that oscillated, or crude ways of imposing a physical principle. One such crude tool is artificial viscosity. Another is the safety of low-order dissipative methods like upwinding. Limiters are tightly tied to the entropy conditions that accompany both. An entropy condition is simply a way to select the physically realizable solution and separate it from the unphysical one. Artificial viscosity can achieve this as well. The power of a limiter is that it applies dissipation only where dissipation is necessary, and “limits” it everywhere else.
I asked five different AI engines, Claude, ChatGPT, Gemini, Llama, and Grok, about the history of limiters. The quality varied, but the answers were remarkably consistent. They were also consistently wrong: each returned the same incorrect, flattened version of reality, repeated five times over. That uniform wrongness is what makes this essay necessary. I have noticed an interesting side effect with AI. When I ask a question and the response is badly wrong, I feel like I should write a blog post about it. The information feels like it should be added to the corpus of knowledge. Right now, the corpus is missing key parts of this topic.
“No scientific discovery is named after its original discoverer.” – Stephen M. Stigler
What really stands out to me is what I should make of the other questions I ask these models. Especially the ones of equal or greater complexity than this one. If I already know the models are unreliable on expert nuance, how unreliable are they on everything else? How fast does reliability fall off as a topic becomes more complex? The decline seems significant. It is a thought, and a question, that frankly has been haunting me of late, and it is a warning that should be heededbroadly across most serious work. It also seems to reflect on the validity of the broader success claimed for “foundation” models.
When I queried these models, what I mostly learned was how wide and how deep the gaps in their knowledge are. They get the basic sketch right. The details, the truth of what actually happened, are missing. All they can hand back is what was processed through the published literature. This is a problem I have come to appreciate over a career: mathematicians, scientists generally, and engineers are terrible historians. The real story is not in the regular literature. Most people never see the details, so the details never get written down.
That is exactly why this is worth doing. I want the history of how things actually happened, as opposed to how they were later cleaned up. The real story has a great deal to teach us. We should know the truth about important discoveries like limiters. In learning how they were really made, we learn how discovery itself works: what the recurring patterns are, and how a rough, half-formed idea turns into state-of-the-art technology. How ideas are exchanged and bred for new ideas. That path is never as clean or as simple as the textbooks make it look. To sanitize it this soon after it happened is a real loss.
What I want to do here is put back the personal touches and the subtle narratives that get sanded off. The formal literature has little tolerance for these essential details, so we are left with a sanitized, formalized history that loses much of its humanity. These stories matter. A great deal has already been lost in the feedback loop between AI and Wikipedia: the depth and genuine understanding that come only from deeper research, and from having lived through some of it. This happens over and over in science, and limiters are another example.
“Everything of importance has been said before by somebody who did not discover it.” – Alfred North Whitehead
Now, back to the story of limiters.
The history of limiters is one of the most important developments in numerical methods. They were built specifically for hyperbolic PDEs, equations that are central to a vast range of applications. The methods we built to solve those equations are a large part of what sets modern computational technology apart. The limiter story is, at its core, the victory of constraints over simplicity. It is also a case of the same idea appearing independently and simultaneously. The conditions were right for inventing them. Both qualities make it worth understanding in depth.
If we step back to 1970, several things are happening at once. The previous twenty-five years had produced a set of competing methods for solving hyperbolic PDEs, and all of them were bad in some way. You had either oscillatory methods with ad hoc stabilization, or dissipative methods with terrible accuracy. Godunov had proved a barrier theorem that seemed to sentence us to one or the other unacceptable option: it stated that non-oscillatory linear methods are necessarily first-order accurate.At the same time, computing power was beginning to grow and to expand beyond the government and defense labs, and computational science was moving from a niche pursuit toward the center of science. As more varied people waded into computational science, ideas flowed. Things that had been accepted needed to be improved.
In this moment, two men set out to overcome the prohibition of Godunov’s theorem. One, Jay Boris, was at the Naval Research Laboratory in the United States. The other, Bram van Leer, was a student in the Netherlands studying astrophysics. At the time they did not know each other, yet they would devise strikingly similar ways of solving the same problem. It is clear that Boris knew of Godunov’s theorem at least in part, and that van Leer knew it as well. Boris understood its limitations. Van Leer did as well and also looked to modernize Godunov’s method.
It is also worth noting what else Boris was working on at the time: the technique that has become known as the Boris fix for Alfvén waves. In magnetics, one recurring difficulty is the appearance of extremely fast Alfvén waves as their speed approaches the speed of light, which severely constrains the time-step size in some MHD codes. Boris devised a method that artificially changes the speed of light to allow more efficient computation. Some of the basic concepts behind that fix are suspiciouslysimilar to what you get with limiters.
In the Netherlands, Bram Van Leer was trying to figure out how to combine the high accuracy of a method like Lax-Wendroff’s with the guaranteed monotonicity of Godunov. I remember being at a conference in 2004 and asking Bram how he discovered limiters. He told me that he could just see that it could be done. He could overlay the solutions from the two methods and see that there was a way to blend them. He just needed to find the recipe. The key was that he knew it could be done. The key was the inspiration. After that it was just a matter of details.
This recipe was what he discovered over the course of a series of papers and has come to be known as limiters. The most common of these are the Van Leer limiters, along with a host of numerical methods for the advection equation and ultimately a higher-order extension of the Godunov method for the Euler equations. His limiters were similar to what Boris created but different in approach. The success of Van Leer’s methodology is attributable to two things: his knowledge, inspiration, and brilliance, and some fortuitous circumstances. I’ll get into this later, but Bram had help in extending his methods to a broader community. He also made better choices for outlets.
The target audience for Van Leer’s work was astrophysics and aerodynamics. Both were essential to the success of the methodology, particularly aerodynamics, where the mathematical theories of Lax and the influence of the Courant Institute were substantial. Astrophysics was important for personal connections and for tying into the national laboratories. Jay Boris worked within the plasma physics community, which was not as fertile a place for expanding his ideas to a broader set of humans. To some extent, this is simply the luck of the draw.
What both men created would become known as limiters, and it produced the Limiter War. They waged pitched battles over credit for years, and the fact is that they both deserve it. They both did the work, and the invention was nearly simultaneous because the conditions were right. Those conditions were the ones laid out at the start of the 1970s: the expansion of computational science and the powerful computing that let it be pursued. What is less well known is that there were two further inventions of limiters, again independent, in nearly the same period.
“In science the credit goes to the man who convinces the world, not to the man to whom the idea first occurs.” – Francis Darwin
The first came from an aerodynamics engineer named Vladimir Kolgan, who worked in the Soviet Union. He developed a numerical scheme that looks very much like what we would today call a second-order ENO scheme. It used a limiter that returns the slope with the smallest magnitude. Kolgan was also producing what we would now call the first high-order Godunov method. He took the scheme Godunov introduced in the very paper that contained the barrier theorem and extended it to second order. The development and popularization of the high-order Godunov method is most often credited to Bram van Leer as one of his chief contributions, yet Kolgan got there first.
“Kolgan succumbed to lung cancer in 1978, at the age of 37; at that time the final papers by Boris’ group and by Van Leer had yet to appear.”– Bram van Leer,
Kolgan’s limiter function is quite similar to the minmod function, which is now used ubiquitously in the design of limiters. Jay Boris invented minmod, and it was so well designed that it has been reused over and over across the field. For the uninitiated, minmod is short for “minimum modulus.” It returns the argument with the smallest magnitude, provided all the arguments share the same sign. If they differ in sign, it returns zero.
The fourth inventor of limiters is Ami Harten, a student of Peter Lax. Harten developed a class of methods known as the artificial compression method. It looks at the magnitude of gradients and removes dissipation from low-order methods such as first-order schemes. The effect is to blend a second-order method with a first-order one, removing the dissipation inherent in the first-order method. Harten is best known for his papers on TVD methods, a mathematically rigorous version of high-order methods. TVD was a formalization of van Leer’s ideas, and it supplied a host of theoretical properties. It rests on four very simple linear test equations, and it carries significant limitations on the achievable order of accuracy. Nonetheless, it provided a mathematical rigor that powered the acceptance of limiters broadly.
“Discovery consists of seeing what everybody has seen and thinking what nobody has thought.” – Albert Szent-Györgyi,
As I argued in the case of the Lax equivalence theorem, the limited but rigorous theory behind TVD methods provides a firm foundation for them. The theory is narrow, but it is exactly that rigor that drives acceptance, development, and the eventual expansion of the methods to a broad range of applications. Peter Lax put much of this into order in his less well-known work on high-resolution methods, where he described how combining accuracy with nonlinear limiters yields what we now call high-resolution methods. That is the most accurate single description of the broad class of methods discussed here.
These applications are strongest in aerodynamics, but they also include a major shift in how the nuclear weapons labs chose to solve their problems. That leads to a couple of closing threads to pull.
In the late 1970s, van Leer was visited by a young scientist from Lawrence Livermore who was on sabbatical. His name was Paul Woodward. A genuine synthesis of ideas followed. Van Leer’s 1979 paper on the MUSCL method was substantially influenced by Woodward’s visit. It included a version of Godunov’s method that used a number of implementations and tricks common in the Lawrence Livermore codes, among them building an Eulerian method through a Lagrangian remap, along with the time-integration ideas Woodward had promoted.
Woodward, in turn, took van Leer’s ideas and worked them into a fine art. In collaboration with Phil Colella, he developed the piecewise parabolic method (PPM), in a sense an extension of van Leer’s Scheme V from his 1979 paper. PPM removed some of the extra variables that earlier scheme required and reconstructed them from finite-volume values. To this day, PPM remains one of the most powerful methods for solving hyperbolic PDEs.
The methods adopted most directly by the weapons labs were the ones van Leer championed, and they took hold most completely in numerical advection and remap algorithms. Van Leer’s high-order methods with limiters for the advection equation revolutionized remap and changed the codes forever. Over the span of a few years every code that did advection or remap adopted Van Leer’s ideas. His methods were so much better that adoption was immediate.
They also had an enormous impact on astrophysics, enabling a phase change in the calculations that could be attempted. This was seen most acutely in accretion disks, which cannot form naturally if you simulate with first-order methods. You need the combination of accuracy with mononticity to compute the phenomena. Once limiters were introduced, you could suddenly compute them. The degree of improvement in capability was quantum in nature.
The explanation is relatively simple. A first-order method effectively adds a linear viscosity, and at almost any reasonable resolution the flow you compute is effectively laminar. You never get the transition to high-Reynolds-number flow, to turbulence, or to other fine structures. With limiters, you remove this laminarization and recover a second-order flow that can behave like a true high-Reynolds-number turbulent flow. This effect is something Len Margolin and I wrote about in one of our more cited papers.
“We present a rationale for the success of nonoscillatory finite volume difference schemes in modelling turbulent flows without need of subgrid scale models … certain truncation terms … have physical justification, representing the modifications to the governing equations that arise when one considers the motion of finite volumes of fluid over finite intervals of time.” – Len G. Margolin and William J. Rider,
The way I explain it is this: you need a second-order solver to get these structures, but you also need to keep that solver well behaved. Limiters are the means to do both, and that is why they produced a phase transition in the kinds of methods we use to solve hyperbolic PDEs. Now today there are a host of limiters and related methods available. For the most part, all of them are capable of doing amazing things compared to classical methods. We await the next revolution in methods. What this might be is a subject of debate. Many feel like the field is fully cooked. Nothing more is needed to improve. To me this is a patently absurd point-of-view.
“A new scientific truth does not triumph by convincing its opponents and making them see the light, but rather because its opponents eventually die, and a new generation grows up that is familiar with it.” – Max Planck
References
Boris, Jay P. “A fluid transport algorithm that works(Development of explicit, Eulerian finite-difference algorithm for solving continuity equation).” (1971).
Boris, Jay P. A physically motivated solution of the Alfvén problem. No. NRLMR2167. 1970.
Boris, Jay P., and David L. Book. “Flux-Corrected Transport. I. SHASTA, A Fluid Transport Algorithm That Works.” Journal of Computational Physics 11, no. 1 (1973): 38–69.
Boris, Jay P., and David L. Book. “Flux-Corrected Transport. III. Minimal-Error FCT Algorithms.” Journal of Computational Physics 20, no. 4 (1976): 397–431.
Colella, Phillip, and Paul R. Woodward. “The Piecewise Parabolic Method (PPM) for Gas-Dynamical Simulations.” Journal of Computational Physics 54, no. 1 (1984): 174–201.
Godunov, Sergei K. “A Difference Scheme for Numerical Computation of Discontinuous Solutions of the Equations of Fluid Dynamics.” Matematicheskii Sbornik 47 (89), no. 3 (1959): 271–306.
Harten, Ami. “The Artificial Compression Method for Computation of Shocks and Contact Discontinuities. I. Single Conservation Laws.” Communications on Pure and Applied Mathematics 30, no. 5 (1977): 611–638.
Harten, Ami. “High Resolution Schemes for Hyperbolic Conservation Laws.” Journal of Computational Physics 49, no. 3 (1983): 357–393.
Kolgan, Vladimir P. “Application of the Principle of Minimizing the Derivative to the Construction of Finite-Difference Schemes for Computing Discontinuous Solutions of Gas Dynamics.” Uchenye Zapiski TsAGI 3, no. 6 (1972): 68–77. Translated and reprinted in Journal of Computational Physics 230, no. 7 (2011): 2384–2390.
Lax, Peter D. “Weak Solutions of Nonlinear Hyperbolic Equations and Their Numerical Computation.” Communications on Pure and Applied Mathematics 7, no. 1 (1954): 159–193.
Lax, Peter D., and Burton Wendroff. “Systems of Conservation Laws.” Communications on Pure and Applied Mathematics 13, no. 2 (1960): 217–237.
Lax, Peter D. “Accuracy and resolution in the computation of solutions of linear and nonlinear equations.” In Recent advances in numerical analysis, pp. 107-117. Academic Press, 1978.
Margolin, Len G., and William J. Rider. “A Rationale for Implicit Turbulence Modelling.” International Journal for Numerical Methods in Fluids 39, no. 9 (2002): 821–841.
Van Leer, Bram. “Towards the Ultimate Conservative Difference Scheme. I. The Quest of Monotonicity.” In Proceedings of the Third International Conference on Numerical Methods in Fluid Mechanics, edited by Henri Cabannes and Roger Temam, 163–168. Lecture Notes in Physics 18. Berlin: Springer-Verlag, 1973.
Van Leer, Bram. “Towards the Ultimate Conservative Difference Scheme. II. Monotonicity and Conservation Combined in a Second-Order Scheme.” Journal of Computational Physics 14, no. 4 (1974): 361–370.
Van Leer, Bram. “Towards the Ultimate Conservative Difference Scheme. IV. A New Approach to Numerical Convection.” Journal of Computational Physics 23, no. 3 (1977): 276–299.
Van Leer, Bram. “Towards the Ultimate Conservative Difference Scheme. V. A Second-Order Sequel to Godunov’s Method.” Journal of Computational Physics 32, no. 1 (1979): 101–136.
Van Leer, Bram. “Upwind and High-Resolution Methods for Compressible Flow: From Donor Cell to Residual-Distribution Schemes.” Communications in Computational Physics 1, no. 2 (2006): 192–206.
Van Leer, Bram. “A Historical Oversight: Vladimir P. Kolgan and His High-Resolution Scheme.” Journal of Computational Physics 230, no. 7 (2011): 2378–2383.
Woodward, Paul, and Phillip Colella. “The Numerical Simulation of Two-Dimensional Fluid Flow with Strong Shocks.” Journal of Computational Physics 54, no. 1 (1984): 115–173.
Woodward, Paul R. “Trade-offs in designing explicit hydrodynamical schemes for vector computers.” In Parallel computations, pp. 153-171. Academic Press, 1982.
Woodward, Paul R. “Piecewise-parabolic methods for astrophysical fluid dynamics.” In Astrophysical Radiation Hydrodynamics, pp. 245-326. Dordrecht: Springer Netherlands, 1986.
“For his groundbreaking contributions to the theory and application of partial differential equations and to the computation of their solutions.” — Citation for the 2005 Abel Prize awarded to Peter D. Lax.
This post focuses on one of Peter Lax’s pivotal contributions. Lax was one of the greatest mathematicians of the 20th century, and his work shaped many fields. None, more deeply than computational science. Winner of the Abel Prize in 2005. He died about a year ago at 99.
His career was shaped by the defining event of that century. He emigrated from Hungary with his family in late 1941. He was drafted into the U.S. Army at 18, and was assigned in 1945–46 to the Manhattan Project at Los Alamos. He was a brilliant high school graduate, but known to top scientists already. He returned to Los Alamos with a PhD as a staff member in 1949-50 and spent most summers there through the 1960s. There he witnessed the beginnings of computational science, and its power. Then he contributed to it mightily.
For my interests, Lax’s contributions sit primarily in hyperbolic conservation laws, where he developed much of the essential theory. These underpin both the mathematical and the numerical solution of these equations. My focus here is the equivalence theorem (Lax and Richtmyer 1956). It is sometimes called the Fundamental Theorem of Numerical Analysis (by Gil Strang). It states that for a well-posed linear initial-value problem, a consistent finite-difference method is convergent if and only if it is stable. The theorem applies rigorously to linear PDEs. This linearity restriction has long been used as the excuse for not placing it in a more central role in the practice and justification of code verification. I believe that excuse is wrong-headed and short-sighted, and I will make the case in what follows.
I write this with two things in mind. The first is the beauty and importance of mathematical foundations. This has utility in giving us confidence in what we do as computational scientists. The second is the recognition that the physical laws to which we apply mathematics are themselves only approximate too. Mathematics is the way we drag the physical world into order so that it can be understood and, with luck, mastered. We keep in mind that mathematical descriptions always fall short of the real thing. This falling-short does not diminish their importance. They are precisely what we lash ourselves to: the proverbial mast in the storm. Diminishing the power of this theorem only lessons our ability to withstand the waves.
“It was the experience of being part of a scientific team — not just of mathematicians, but people with different outlooks — with the aim being not a theorem, but a product. One cannot learn that from books, one must be a participant… It was there — that was in the 1950s — that I became imbued with the utter importance of computing for science and mathematics.” — Peter D. Lax
The Case for the Theorem
I believestrongly that Lax equivalence theorem is the foundation of verification. I will make the case for why. I will start by why the standard objection to it misses the point.
If one consults the canonical V&V references, Roache (1998), or Oberkampf and Roy (2010) you find a curiously dismissive attitude toward the theorem. The reason is always the same: strictly and rigorously, it applies only to linear partial differential equations. We all know that almost everything interesting in science is governed by nonlinear equations. In both books the theorem is mentioned exactly once, and in both it is dismissed almost as fast as it is raised.
I think that is short-sighted.
The theorem captures is the essence of what we ask of any computation: more computational effort will produce a more accuracy. It ties together the two properties that make this possible. These are consistency and numerical stability. It states that, for a well-posed linear problem, the two together are equivalent to convergence. That is the whole game. We design consistency and stability into a method. This carries the expectation of convergence. Verification is the discipline of checking whether the method actually delivers what the theory promises.
“Physics is like sex: sure, it may give some practical results, but that’s not why we do it.”― Richard P. Feynman
Yes, the rigorous statement is restricted to linear equations. But the objection loses the forest for the trees. Most of the nonlinear equations we actually care about are contractive. A contractive equation is close to a linear one in terms of what we expect from it. This is what is witnessed in our daily work. The genuine danger the linear caveat points at is real. Nonlinear equations can produce ill-behaved structures and solutions that do not converge the way linear ones do. Even linear equations do as witnessed by the fractional convergence of linear advection. That danger is the exception we should watch for, not the rule that should make us throw the framework away. The theorem tells us what to do. It defines the practice we must embrace.
The forest is this: Lax’s theorem expresses a fundamental, almost axiomatic belief about computing. It encapsulates precisely why verification is worth doing at all. The theorem is useful ammunition in a practice that is resisted commonly.
“The mathematical formulation of the physicist’s often crude experience leads in an uncanny number of cases to an amazingly accurate description of a large class of phenomena.” — Eugene P. Wigner
A Practitioner’s View
“There are many hypotheses in science that are wrong. That’s perfectly alright; it’s the aperture to finding out what’s right. Science is a self-correcting process. To be accepted, new ideas must survive the most rigorous standards of evidence and scrutiny.” ― Carl Sagan
Let me put it personally. Over a career spent designing methods, the two conditions I come back to every time are consistency, and stability. Consistency is where accuracy lives and gets defined. Stability is essential and must always be checked at design. The accuracy or stability of a technique matters more than the technique itself. I check the code, I look at how it converges on simplie problems. Then I go to more real problems. With observed convergence I confirm that the overall recipe I designed is a good. Evidence that I actually implemented what I intended to design. I have done this many times, and every single time, the result still lines up with the conditions of the equivalence theorem. It is disturbing to me that the community does not more widely recognize this simple pair of conditions as the foundational contribution it is. It is the cornerstone of the practice of the computational scientist.
There is more foundation to build here, not less. Extending it to specific classes of nonlinear equations would be valuable work. The Lax–Wendroff theorem already shows part of the way. For a consistent, conservative scheme, a convergent solution is guaranteed. A weak solution of the conservation law if you have conservation form. This has a technicality that you still need an entropy condition to pick out the physically correct weak solution.
So does the equivalence theorem hold for nonlinear equations all the time? No. Does it hold most of the time? Empirically, yes. There is the heart of my complaint: why reject something that holds most of the time? We should of course be careful, precisely because we cannot claim it always holds. Rejecting it outright is short-sighted. This is especially true given the power of the underlying concept. It has driven the growth of computational power in the decades since the Second World War. Its precepts hold for the vast majority of important work. When it does not hold, we have a crisis.
I would rather be tethered to something that does not rigorously apply than to nothing at all. This theorem supplies most of the practice we rely on during verification. That alone is reason to embrace it. Pure mathematics may not regard it as ironclad for the nonlinear problems we actually run. That is an important caveat to make clear. Still it contains very nearly the entirety of our well-founded beliefs about what these computations are doing, and it holds up empirically. That is exactly what makes it the right thing to stand on.
“I heartily recommend that all young mathematicians try their skill in some branch of applied mathematics. It is a gold mine of deep problems whose solutions await conceptual as well as technical breakthroughs.” — Peter D. Lax
References
Lax, P. D., and R. D. Richtmyer (1956). “Survey of the Stability of Linear Finite Difference Equations.” Communications on Pure and Applied Mathematics 9 (2): 267–293. DOI: 10.1002/cpa.3160090206.
Oberkampf, W. L., and C. J. Roy (2010). Verification and Validation in Scientific Computing. Cambridge University Press, Cambridge. ISBN 978-0-521-11360-1.
Roache, P. J. (1998). Verification and Validation in Computational Science and Engineering. Hermosa Publishers, Albuquerque, NM. ISBN 978-0-913478-08-0.
I’ve taken a brief hiatus from posting, and I wanted to share why.
About three weeks ago, my father passed away after a long and extremely painful illness. It caused him a lot of pain, and it was also very hard on his loved ones. Last week, my brother visited me, and we spent a lot of time getting my dad’s affairs in order. We lost my mom six years ago, so we had to handle, for the final time, the remains of my parents, along with a lot of other business.
We have possessions to sort through, a few things to keep, an estate sale, and ultimately the sale of the family home. All of this has been going on, and as you might expect, it has gotten in the way of writing.
I’ve drafted a couple of other posts, and I’ll start working on them in the next couple of days. I hope to be back to my normal pace of writing things that are hopefully interesting and thought-provoking for all of you.
“AI won’t replace humans, but those who use AI will replace those who don’t.” – Garry Kasparov
One of the most important questions that needs to be answered today is: How do you use AI? How do you use it properly and effectively to do your work, help run your life, and ultimately make things better? It has an amazing capacity to do this, but only if it’s used well. AI is also potentially completely and utterly destructive. It is destructive if it merely replaces the thinking person with unthinking AI slop. The direction today is moving towards destructive, and change is needed for it to be good for society.
As I wrapped up my professional life, AI suddenly landed on my radar in 2022. I immediately saw it as something huge and amazing, a moment that had happened a few times before. It felt bigger than either the advent of the Google search algorithm or the smartphone. AI is a massively transformative technology. We need to tackle the task of making the transformation positive.
“Abundance … is the state in which there is enough of what we need to create lives better than what we have had.” –Ezra Klein and Derek Thompson
My concern right now is that the oligarchs and their endless greed and appetite for money will just look for more. Look at how social media played out. In addition, we have government incompetence and plain mental laziness. Corporate interests are simply poisoning our national “strategy.” Mostly, we don’t have a strategy other than buying a shitload of computers (data centers). Alongside this is destroying scientific research. The result is we are going to completely botch the rollout of AI and fail to take advantage of what it can truly do.
The bottom line is that dealing with AI properly is twofold:
There’s a technique and a mindset one needs to adopt. This mindset is verification and validation of AI’s work.
The goals for our organizations and institutions need to adapt to get the most out of them. AI can allow people to work more and better, not simply eliminate people.
This is a mentality of abundance, not scarcity. Right now, both of those things are decidedly not in place. The correct mindset for engaging with AI is the scientific method. In practice, that means using verification and validation. These are mindsets and techniques that help unleash AI safely and productively.
The core mindset is that AI should augment people, not replace them. It should help each person do more and better work, whether at work or at home. A foundational principle is to improve human life. Clearly, this idict is absent today as a backlash is growing day by day. Right now, no one (corporately or institutionally) is actively engaged in this mindset. If we do not change, AI could ultimately doom itself as a technology. The United States will lose its edge in the battle for dominance through the backlash. To succeed with AI, we need to adopt an abundance mindset rather than a scarcity mindset.
“The confidence people have in their beliefs is not a measure of the quality of evidence but of the coherence of the story.” – Daniel Kahneman
I’ll start with a non-technical example. My wife and I recently bought a tin raven sculpture for our front yard. We love ravens in the mountains here in New Mexico and wanted to display this. I found the perfect pedestal: a rock in our front yard where the raven could stand and be visible from the driveway, the street, and my kitchen window. The problem was that the raven kept blowing over in the wind. So I asked ChatGPT, “How can I secure the bird to the rock so this doesn’t happen all the time?” It suggested buying clear epoxy. It seemed a reasonable logical solution. To validate that approach, we checked at the store where we normally shop and found a product that matched the recommendation.
The validation was straightforward: the product was available. Moreover, the solution seemed like it would work both short-term and long-term. So far, it has been a great solution we hadn’t thought of initially. We shall see how it weathers through our seasons and persists.
This example illustrates a basic methodology in simple form. It also shows the danger of AI. The danger is that AI becomes like social media: it sells you a specific product (a brand), lets you click to buy it on Amazon, and has it delivered. One could easily see that happening, and it would start a downward spiral for AI as a tool to transform society. It would be monetized just like social media and become an engine of greed. It would sell us crap and rapidly become enshitified like all those companies.
I’ve argued that V&V is the scientific method. I think the terms in V&V are especially useful for constructively engaging AI. The first piece is verification. It can apply to confidence that a tool is theoretically correct. For modeling and simulation, the definition is straightforward. For AI, the definition is slightly different: it’s about whether the tool can provide basic information reliably and correctly.
“Progress is more about implementation than it is about invention.” –Ezra Klein and Derek Thompson
When I start querying a large language model on a topic, I always begin by asking axiomatic questions to determine whether the basic information is present in the LLM’s responses. More importantly, are there gaps or mistakes in that knowledge that need to be accounted for before I try to probe into the unknown? This is a verification exercise and a way for me to gain confidence. Conversely, I might find that the LLM is faulty. I can proceed through other avenues. Through verification, I can find if the LLM is well-suited for the pursuit of the question that I am thinking about. This is the initial step.
The real work comes in validating the LLM’s responses to deeper, more unknown questions. A key is to approach this with a healthy dose of doubt and take everything the LLM produces with a grain of salt. Addressing and calming these doubts is V&V thinking. One way to validate the results is to research the LLM’s responses and check whether they are factually correct. Another approach is to test the results in the field and see whether they hold up. We did this with the tin raven.
If you are writing code or running a literature search for your work, you should also validate. See that the references the LLM finds are actually real. Once you have validated the results, you can use them with confidence. You get an acceleration of your work, but you still have to do the legwork to confirm whether it is correct. One can do far more validation by using multiple LLMs to flag variations in response.
There are a few ways to query an LLM to help you assess the reliability of its responses:
Ask the LLM to provide references and links so you can track where the information came from and evaluate whether it is reliable.
Ask the LLM to provide multiple responses to the same question. Make the LLM score each result to get a sense of its relative confidence. This can help you probe the broader uncertainty in the results. For higher-stakes questions, draw more samples and pay attention to where the score drops off. You can see if LLM is providing responses it believes are less likely. Validation would examine the veracity of its assessment.
This uncertainty needs to be probed and validated. I have seen cases where the lower-probability response was actually the better one. This rightly calls its results into question.
This gets at the power of AI, which is very good at breadth and at incorporating a broad spectrum of views. That breadth is also the danger, since there is no truth embedded. One needs to be mindful of the breadth it is producing. It is dangerous. Some of the responses LLMs provide are garbage (hallucinations or bullshit).
Humans provide depth. Humans provide thought and checking. The combination is powerful. If you take the breadth and consider it carefully, the LLM results can broaden your perspectives. This can, in turn, encourage deeper thought. That deep thought needs to be encouraged across the board.
This gets to the worry I would have when the leadership at work engages with using AI. When I was working, the push to use AI was superficial and clumsy. I’ve heard from friends at several institutions that the leadership’s approach to AI has been mindless cheerleading. For example, getting people to use it without any sense of responsibility or technique. For example, they might say, “Let AI write your performance review or performance plan.” No effort was put into showing how to engage with it properly. The entire engagement lacked any skill or depth.
“We have a startling abundance of the goods that fill a house and a shortage of what’s needed to build a good life.”–Ezra Klein and Derek Thompson
This kind of mindless work calls into question the performance review itself. It is not befitting leadership and malpractice. Leadership should encourage people to think and do the hard work of using AI properly. Use AI to augment their work (not replace it). The goal should be to make work better, deeper, and of higher quality. Ultimately, the aim is to use it as a tool to encourage broader, more open-minded thinking. That thinking needs to be applied in a verified and validated way so it can be used for things that matter. Given the mission of these institutions, any other approach is reprehensible.
Let’s get to the real enemy of success and AI: a short-term view of what constitutes success. For corporations, that means money. For institutions, it means money too, and increasingly so. Success means taking the long-term view of success. Using AI properly is a long journey. It requires deep engagement with the development of detailed processes analogous to V&V used in modeling and simulation. We all need to put in the work.
“The ability to discipline yourself to delay gratification in the short term in order to enjoy greater rewards in the long term, is the indispensable prerequisite for success.” — Brian Tracy
If you adopt a scarcity mindset, you use AI to replace workers and reduce the workforce size. You invite the backlash we are starting to see. In the short term, this works like a charm. We have institutions and corporations that show no fealty to the nation as a whole and will eagerly make decisions that are negative for society. We’ve seen this with social media, and if we see it with AI, the damage will be profound. The opportunity cost is even higher. AI could do miraculous things. That opportunity is being squandered.
This dynamic between humans and AI plays out most profoundly in education. If we adopt a scarcity mindset and fail to adapt, AI could completely upend our current educational system. We can choose to make it better or worse. Right now, we are moving towards worse by resisting this technology. Our educational system already needs an overhaul. Do we grab the opportunity to improve it, and train the next generation with this technology? It could be a catalyst for a positive transformation.
My attitude is that we should assume every student is using AI and design a system that is impervious to cheating. That assumption is the key. The essence is teaching students how to use AI properly. It is what I described above. They need to have the necessary techniques, knowledge, and drive to augment and accelerate learning. These lessons can be meaningful with or without AI. The hard part is putting some burden on the teachers. Education cannot be static or underestimate this technology. The value of a liberal arts education will suddenly skyrocket. The skills and knowledge are going to be in greater demand. True human individuality and authenticity are also needed to stand out with AI. AI flattens and makes work anonymous. In the future, the touch of inspiration from an individual will be a hunger.
“The first lesson of economics is scarcity: There is never enough of anything to satisfy all those who want it. The first lesson of politics is to disregard the first lesson of economics.” – Thomas Sowell
My stance is this: if you submit work that is essentially regurgitated AI “slop,” you get no credit. That is a zero, a foundation. If you produce something wonderful and good without AI, more power to you. The question is, if you are using AI, are you producing a better product? Have you done the due diligence and the work required to make something better than you could produce on your own? We should adopt disclosure about AI use across the board. We should always talk about how AI was used in the production of the work, and we should do this at work and at school, every time.
For example, I use Claude to edit and do a comprehension and grammar pass on my writing. I also use Claude to generate potential social media posts for each blog post. I do this as a matter of course as part of my education on LLMs. I make sure the writing itself is all from me.
Ultimately, this attitude should apply in education, in work, and in life. Placing the scientific method and verification/validation at the center of how our new world works is long overdue. The quest to use AI productively in society can power this shift. It would change AI from a force of unbridled destruction into one of creation and quality.
The abundance mindset, which says we keep all the people but make them produce more over the long run, is the path to wealth and success for society as a whole. It requires patience, investment, and a strategy that our current leadership seems incapable of producing. Ultimately, this is our greatest battle: getting our leadership to choose a long-term path to success over short-term profit-taking. The signs today do not look good, since short-term profit and wealth are dominating everything, whether public or private.
“We had better be quite sure that the purpose put into the machine is the purpose which we really desire.” – Norbert Wiener