The reasonable man adapts himself to the world: the unreasonable one persists in trying to adapt the world to himself. Therefore all progress depends on the unreasonable man.
― George Bernard Shaw
 We appear to be living in a golden age of progress. I’ve come increasingly to the view that this is false. We are living in an age that is enjoying the fruits of a golden age and following the inertia of a scientific golden age. The forces powering the “progress” we enjoy are not being returned to our future generations. So, what are we going to do when we run out of the gains made by our fore bearers?
We appear to be living in a golden age of progress. I’ve come increasingly to the view that this is false. We are living in an age that is enjoying the fruits of a golden age and following the inertia of a scientific golden age. The forces powering the “progress” we enjoy are not being returned to our future generations. So, what are we going to do when we run out of the gains made by our fore bearers?
 Progress is a tremendous bounty to all. We can all benefit from wealth, longer and healthier lives, greater knowledge and general well-being. The forces arrayed against progress are small-minded and petty. For some reason the small-minded and petty interests have swamped forces for good and beneficial efforts. Another way of saying this is the forces of the status quo are working to keep change from happening. The status quo forces are powerful and well-served by keeping things as they are. Income inequality and conservatism are closely related because progress and change favors those who benefit from change. The people at the top favor keeping things just as they are.
Progress is a tremendous bounty to all. We can all benefit from wealth, longer and healthier lives, greater knowledge and general well-being. The forces arrayed against progress are small-minded and petty. For some reason the small-minded and petty interests have swamped forces for good and beneficial efforts. Another way of saying this is the forces of the status quo are working to keep change from happening. The status quo forces are powerful and well-served by keeping things as they are. Income inequality and conservatism are closely related because progress and change favors those who benefit from change. The people at the top favor keeping things just as they are.
Those who do not move, do not notice their chains.
― Rosa Luxemburg
 Most of the technology that powers today’s world was actually developed a long time ago. Today the technology is simply being brought to “market”. Technology at a commercial level has a very long lead-time. The breakthroughs in science that surrounded the effort fighting the Cold War provide the basis of most of our modern society. Cell phones, computers, cars, planes, etc. are all associated with the science done decades ago. The road to commercial success is long and today’s economic supremacy is based on yesterday’s investments.
Most of the technology that powers today’s world was actually developed a long time ago. Today the technology is simply being brought to “market”. Technology at a commercial level has a very long lead-time. The breakthroughs in science that surrounded the effort fighting the Cold War provide the basis of most of our modern society. Cell phones, computers, cars, planes, etc. are all associated with the science done decades ago. The road to commercial success is long and today’s economic supremacy is based on yesterday’s investments.
Without deviation from the norm, progress is not possible.
― Frank Zappa
Since the amount of long-term investment today is virtually zero, we can expect virtually zero return down the road. We aren’t effectively putting resources into basic or applied research much as we aren’t keeping up with roads and bridges. Our low-risk approach to everything is sapping the vitality from research. We compound this by failing to keep our 20th Century infrastructure healthy, and completely failing to provide a 21st Century one (just look at our pathetic internet speeds). Even where we spend lots on money on things like science little investment is happening because of the dysfunctional system. One of the big things hurting any march toward progress is the inability to take risks. Because failure is so heavily penalized, people won’t take the risks necessary for success. If you can’t fail, you can’t succeed either. It is an utterly viscous cycle that highlights the nearly complete lack of leadership. The lack of action by National leadership is simply destroying the quality of our future.
Restlessness is discontent — and discontent is the first necessity of progress. Show me a thoroughly satisfied man — and I will show you a failure.
― Thomas A. Edison
Take high performance computing as an example. In many respects the breakthroughs in algorithms have been as important as the computers themselves. Lack of risk taking has highlighted the computers as the source of progress because of Moore’s law. Algorithmic work is more speculative and hence risky. Payoffs are huge, but infrequent and thus risky. Effort might be expended that yields nothing at all. There shouldn’t be anything wrong with that! Because they are risky they are not favored.
We can only see a short distance ahead, but we can see
plenty there that needs to be done.
― Alan Turing
A secondary impact of the focus on computers is that the newer computing approaches are really hard to use. It is a very hard problem to simply get the old algorithmic approaches to work at all. With so much effort going into implementation as well as being siphoned from new algorithmic research, the end product is stagnation. Numerical linear algebra is a good example of this terrible cycle in action. The last real algorithm breakthrough is multigrid about 30 years ago. Since then work has focused on making the algorithms work on massively parallel computers.
Progress always involves risk; you can’t steal second base and keep your foot on first
― F.W. Dupee
The net result is lack of progress. Our leaders are seemingly oblivious to the depth of the problem. They are too caugh t up in trying to justify the funding for the path they are already taking. The damage done to long-term progress is accumulating with each passing year. Our leadership will not put significant resources into things that pay off far into the future (what good will that do them?). We have missed a number of potentially massive breakthroughs chasing progress from computers alone. The lack of perspective and balance in the course for progress shows a stunning lack of knowledge for the history of computing. The entire strategy is remarkably bankrupt philosophically. It is playing to the lowest intellectual denominator. An analogy that does the strategy too much justice would compare this to rating cars solely on the basis of horsepower.
t up in trying to justify the funding for the path they are already taking. The damage done to long-term progress is accumulating with each passing year. Our leadership will not put significant resources into things that pay off far into the future (what good will that do them?). We have missed a number of potentially massive breakthroughs chasing progress from computers alone. The lack of perspective and balance in the course for progress shows a stunning lack of knowledge for the history of computing. The entire strategy is remarkably bankrupt philosophically. It is playing to the lowest intellectual denominator. An analogy that does the strategy too much justice would compare this to rating cars solely on the basis of horsepower.
A person who makes few mistakes makes little progress.
― Bryant McGill
 The end product of our current strategy will ultimately starve the World of an avenue for progress. Our children will be those most acutely impacted by our mistakes. Of course we could chart another path that balanced computing emphasis with algorithms, methods and models. Improvements in our grasp of physics and engineering should probably be in the driver’s seat. This would require a significant shift in the focus, but the benefits would be profound.
The end product of our current strategy will ultimately starve the World of an avenue for progress. Our children will be those most acutely impacted by our mistakes. Of course we could chart another path that balanced computing emphasis with algorithms, methods and models. Improvements in our grasp of physics and engineering should probably be in the driver’s seat. This would require a significant shift in the focus, but the benefits would be profound.
One of the most moral acts is to create a space in which life can move forward.
― Robert M. Pirsig
What we lack is the concept of stewardship to combine with leadership. Our leaders are stewards of the future, or they should be. Instead they focus almost exclusively on the present with the future left to fend for itself.
Human progress is neither automatic nor inevitable… Every step toward the goal of justice requires sacrifice, suffering, and struggle; the tireless exertions and passionate concern of dedicated individuals.
― Martin Luther King Jr.
 ncertainty quantification is a hot topic. It is growing in importance and practice, but people should be realistic about it. It is always incomplete. We hope that we have captured the major forms of uncertainty, but the truth is that our assumptions about simulation blind us to some degree. This is the impact of “unknown knowns” the assumptions we make without knowing we are making them. In most cases our uncertainty estimates are held hostage to the tools at our disposal. One way of thinking about this looks at codes as the tools, but the issue is far deeper actually being the basic foundation we base of modeling of reality upon.
ncertainty quantification is a hot topic. It is growing in importance and practice, but people should be realistic about it. It is always incomplete. We hope that we have captured the major forms of uncertainty, but the truth is that our assumptions about simulation blind us to some degree. This is the impact of “unknown knowns” the assumptions we make without knowing we are making them. In most cases our uncertainty estimates are held hostage to the tools at our disposal. One way of thinking about this looks at codes as the tools, but the issue is far deeper actually being the basic foundation we base of modeling of reality upon. One of the really uplifting trends in computational simulations is the focus on uncertainty estimation as part of the solution. This work is serving the demands of decision makers who increasingly depend on simulation. The practice allows simulations to come with a multi-faceted “error” bar. Just like the simulations themselves the uncertainty is going to be imperfect, and typically far more imperfect than the simulations themselves. It is important to recognize the nature of imperfection and incompleteness inherent in uncertainty quantification. The uncertainty itself comes from a number of sources, some interchangeable.
One of the really uplifting trends in computational simulations is the focus on uncertainty estimation as part of the solution. This work is serving the demands of decision makers who increasingly depend on simulation. The practice allows simulations to come with a multi-faceted “error” bar. Just like the simulations themselves the uncertainty is going to be imperfect, and typically far more imperfect than the simulations themselves. It is important to recognize the nature of imperfection and incompleteness inherent in uncertainty quantification. The uncertainty itself comes from a number of sources, some interchangeable. Aleatory: This is uncertainty due to the variability of phenomena. This is the weather. The archetype of variability is turbulence, but also think about the detailed composition of every single device. They are all different in some small degree never mind their history after being built. To some extent aleatory uncertainty is associated with a breakdown of continuum hypothesis and is distinctly scale dependent. As things are simulated at smaller scales different assumptions must be made. Systems will vary at a range of length and time scales, and as scales come into focus their variation must be simulated. One might argue that this is epistemic, in that if we could measure things precisely enough then it could be precisely simulated (given the right equations, constitutive equation and boundary conditions). This point of view is rational and constructive only to a small degree. For many systems of interest chaos reigns and measurements will never be precise enough to matter. By and large this form of uncertainty is simply ignored because simulations can’t provide information.
Aleatory: This is uncertainty due to the variability of phenomena. This is the weather. The archetype of variability is turbulence, but also think about the detailed composition of every single device. They are all different in some small degree never mind their history after being built. To some extent aleatory uncertainty is associated with a breakdown of continuum hypothesis and is distinctly scale dependent. As things are simulated at smaller scales different assumptions must be made. Systems will vary at a range of length and time scales, and as scales come into focus their variation must be simulated. One might argue that this is epistemic, in that if we could measure things precisely enough then it could be precisely simulated (given the right equations, constitutive equation and boundary conditions). This point of view is rational and constructive only to a small degree. For many systems of interest chaos reigns and measurements will never be precise enough to matter. By and large this form of uncertainty is simply ignored because simulations can’t provide information. bar. Too often these errors are ignored, wrongly assumed to be small, or incorrectly estimated. There is no excuse for this today.
bar. Too often these errors are ignored, wrongly assumed to be small, or incorrectly estimated. There is no excuse for this today. A large part of the reason for failing to address these matters is the implicit, but slavish devotion to determinism. Simulations are almost always viewed as the solution to a deterministic problem. This means there is AN answer. Answers are almost never sought in the sense of a probability distribution. Even probabilistic methods like Monte Carlo are trying to approach the deterministic solution. Reality is almost never AN answer and almost always a distribution. What we end up solving is the mean expected response of a system to the average circumstance. What is actually observed is a distribution of responses to a distribution of circumstances. Often the real question to answer in any study (with or without simulation) is what’s the worse that can reasonably happen? A level of confidence that says 95% or 99% of the responses will be less than some bad level usually defines the desired result. This sort of question is best thought of as aleatory, and our current simulation capability doesn’t begin to address it.
A large part of the reason for failing to address these matters is the implicit, but slavish devotion to determinism. Simulations are almost always viewed as the solution to a deterministic problem. This means there is AN answer. Answers are almost never sought in the sense of a probability distribution. Even probabilistic methods like Monte Carlo are trying to approach the deterministic solution. Reality is almost never AN answer and almost always a distribution. What we end up solving is the mean expected response of a system to the average circumstance. What is actually observed is a distribution of responses to a distribution of circumstances. Often the real question to answer in any study (with or without simulation) is what’s the worse that can reasonably happen? A level of confidence that says 95% or 99% of the responses will be less than some bad level usually defines the desired result. This sort of question is best thought of as aleatory, and our current simulation capability doesn’t begin to address it. gical if the conditions being modeled are known with exceeding precision. The problem is that such precision is virtually impossible for any circumstance. This is the core of the problem with simulating the aleatory uncertainty that so frequently remains untreated. It is almost completely ignored by a host of fundamental assumption in modeling that is inherited by simulations. These assumptions are holding back real progress in a host of fields of major importance.
gical if the conditions being modeled are known with exceeding precision. The problem is that such precision is virtually impossible for any circumstance. This is the core of the problem with simulating the aleatory uncertainty that so frequently remains untreated. It is almost completely ignored by a host of fundamental assumption in modeling that is inherited by simulations. These assumptions are holding back real progress in a host of fields of major importance. methods are understood only superficially, and this results in a superficial uncertainty estimate. Often the black box thinking extends to the tool used to get uncertainty too. We then get the result from a superposition of two black boxes. Not a lot light bets shed on reality in the process. Numerical errors are ignored, or simply misdiagnosed. Black box users often simply do a mesh sensitivity study, and assume that small changes under mesh variation are indicative of convergence and small errors. They may or may not be such evidence. Without doing a more formal analysis this sort of conclusion is not justified. If code and problem is not converging, the small changes may be indicative of very large numerical errors or even divergence and a complete lack of control.
methods are understood only superficially, and this results in a superficial uncertainty estimate. Often the black box thinking extends to the tool used to get uncertainty too. We then get the result from a superposition of two black boxes. Not a lot light bets shed on reality in the process. Numerical errors are ignored, or simply misdiagnosed. Black box users often simply do a mesh sensitivity study, and assume that small changes under mesh variation are indicative of convergence and small errors. They may or may not be such evidence. Without doing a more formal analysis this sort of conclusion is not justified. If code and problem is not converging, the small changes may be indicative of very large numerical errors or even divergence and a complete lack of control. Moore’s law isn’t a law, but rather an empirical observation that has held sway for far longer than could have been imagined fifty years ago. In some way shape or form, Moore’s law has provided a powerful narrative for the triumph of computer technology in our modern World. For a while it seemed almost magical in its gift of massive growth in computing power over the scant passage of time. Like all good things, it will come to an end, and soon if not already.
Moore’s law isn’t a law, but rather an empirical observation that has held sway for far longer than could have been imagined fifty years ago. In some way shape or form, Moore’s law has provided a powerful narrative for the triumph of computer technology in our modern World. For a while it seemed almost magical in its gift of massive growth in computing power over the scant passage of time. Like all good things, it will come to an end, and soon if not already.


 For those of us doing real practical work on computers this program is a disaster. Even doing the same things we do today will be harder and more expensive. It is likely that the practical work will get harder to complete and more difficult to be sure of. Real gains in throughput are likely to be far less than the reported gains in performance attributed to the new computers too. In sum the program will almost certainly be a massive waste of money. The plan is for most of the money going to the hardware and the hardware vendors (should I think corporate welfare?). All of this will be done to squeeze another 7 to 10 years of life out of Moore’s law even though the patient is metaphorically in a coma already.
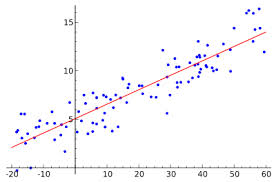
For those of us doing real practical work on computers this program is a disaster. Even doing the same things we do today will be harder and more expensive. It is likely that the practical work will get harder to complete and more difficult to be sure of. Real gains in throughput are likely to be far less than the reported gains in performance attributed to the new computers too. In sum the program will almost certainly be a massive waste of money. The plan is for most of the money going to the hardware and the hardware vendors (should I think corporate welfare?). All of this will be done to squeeze another 7 to 10 years of life out of Moore’s law even though the patient is metaphorically in a coma already. If someone gives you some data and asks you to fit a function that “models” the data, many of you know the intuitive answer, “least squares”. This is the obvious, simple choice, and perhaps, not surprisingly, not the best answer. How bad this choice may be depends on the situation? One way to do better is to recognize the situations where the solution via least squares may be problematic, and produce an undue influence on the results.
If someone gives you some data and asks you to fit a function that “models” the data, many of you know the intuitive answer, “least squares”. This is the obvious, simple choice, and perhaps, not surprisingly, not the best answer. How bad this choice may be depends on the situation? One way to do better is to recognize the situations where the solution via least squares may be problematic, and produce an undue influence on the results. one. If the deviations are large or some of your data might be corrupt (i.e., outliers), the choice of least squares can be catastrophic. The corrupt data may have a completely overwhelming impact on the fit. There are a number of methods for dealing with outliers in least squares, and in my opinion none of them good.
one. If the deviations are large or some of your data might be corrupt (i.e., outliers), the choice of least squares can be catastrophic. The corrupt data may have a completely overwhelming impact on the fit. There are a number of methods for dealing with outliers in least squares, and in my opinion none of them good. Fortunately there are existing methods that are free from these pathologies. For example the least median deviation fit can deal with corrupt data easily. It naturally excludes outliers from the fit because of a different underlying model. Where least squares are the solution of a minimization problem in the energy or L2 norm, the least median deviation uses the L1 norm. The problem is that the fitting algorithm is inherently nonlinear, and generally not included in most software.
Fortunately there are existing methods that are free from these pathologies. For example the least median deviation fit can deal with corrupt data easily. It naturally excludes outliers from the fit because of a different underlying model. Where least squares are the solution of a minimization problem in the energy or L2 norm, the least median deviation uses the L1 norm. The problem is that the fitting algorithm is inherently nonlinear, and generally not included in most software.
 One of the problems is that least squares are virtually knee-jerk in its application. It is contained in standard software such as Microsoft Excel and can be applied with almost no thought. If you have to write your own curve-fitting program by far the simplest approach is to use least squares. It can often produce a linear system of equations to solve where alternatives are invariably nonlinear. The key point is to realize that this convenience has a consequence. If your data reduction is important, it might be a good idea to think about what you ought to do a bit more.
One of the problems is that least squares are virtually knee-jerk in its application. It is contained in standard software such as Microsoft Excel and can be applied with almost no thought. If you have to write your own curve-fitting program by far the simplest approach is to use least squares. It can often produce a linear system of equations to solve where alternatives are invariably nonlinear. The key point is to realize that this convenience has a consequence. If your data reduction is important, it might be a good idea to think about what you ought to do a bit more.