I suppose it is tempting, if the only tool you have is a hammer, to treat everything as if it were a nail.
― Abraham Maslow
High performance computing is a big deal these days and may become a bigger deal very soon. It has be come a new battleground for national supremacy. The United States will very likely soon commit to a new program for achieving progress in computing. This program by all accounts will be focused primarily on the computing hardware first, and then the system software that directly connects to this hardware. The goal will be the creation of a new generation of supercomputers that attempt to continue the growth of computing power into the next decade, and provide a path to “exascale”. I think it is past time to ask, “do we have the right priorities?” “Is this goal important and worthy of achieving?”
come a new battleground for national supremacy. The United States will very likely soon commit to a new program for achieving progress in computing. This program by all accounts will be focused primarily on the computing hardware first, and then the system software that directly connects to this hardware. The goal will be the creation of a new generation of supercomputers that attempt to continue the growth of computing power into the next decade, and provide a path to “exascale”. I think it is past time to ask, “do we have the right priorities?” “Is this goal important and worthy of achieving?”
Lack of direction, not lack of time, is the problem. We all have twenty-four hour days.
― Zig Ziglar
 I’ll return to these two questions at the end, but first I’d like to touch on an essential concept in high performance computing, scaling. Scaling is a big deal, it measures success in computing, in a nutshell describes efficiency of solving problems particular with respect to changing problem size or computing resource. In scientific computing one of the primary assumptions is that bigger faster computers yield better, more accurate results that have greater relevance to the real world. The success of computing depends on scaling and breakthroughs in achieving it, defines the sort of problems that could be solved.
I’ll return to these two questions at the end, but first I’d like to touch on an essential concept in high performance computing, scaling. Scaling is a big deal, it measures success in computing, in a nutshell describes efficiency of solving problems particular with respect to changing problem size or computing resource. In scientific computing one of the primary assumptions is that bigger faster computers yield better, more accurate results that have greater relevance to the real world. The success of computing depends on scaling and breakthroughs in achieving it, defines the sort of problems that could be solved.
Nothing is less productive than to make more efficient what should not be done at all.
― Peter Drucker
There are se veral types of scaling with distinctly different character. Lately the dominant scaling in computing has been associated with parallel computing performance. Originally the focus was on strong scaling, which is defined by the ability of greater computing resources to solve a problem of fixed size faster. In other words perfect strong scaling would result from solving a problem twice as fast with two CPUs than with one CPU.
veral types of scaling with distinctly different character. Lately the dominant scaling in computing has been associated with parallel computing performance. Originally the focus was on strong scaling, which is defined by the ability of greater computing resources to solve a problem of fixed size faster. In other words perfect strong scaling would result from solving a problem twice as fast with two CPUs than with one CPU.
Lately this has been replaced by weak scaling where the problem size is adjusted along with the resource. The goal is to solve a problem that is twice as big with two CPUs just as fast as the original problem is solved with one CPU. These scaling results depend both on the software implementation and the quality of the hardware. They are the stock and trade of success in the currently envisioned high performance-computing program nationally. They are also both relatively unimportant and poor measures of the power of computing to solve scientific problems.
Two things are infinite: the universe and human stupidity; and I’m not sure about the universe.
― Albert Einstein
Algorithmic scaling is another form of scaling and it is massive in its power. We are failing to measure, invest and utilize it in moving forward in computing nationally. The gains to be made through algorithmic scaling will almost certainly lay waste to anything that computing hardware will deliver. It isn’t that hardware investments aren’t necessary; they are simply grossly over-emphasized to a harmful degree.
The saddest aspect of life right now is that science gathers knowledge faster than society gathers wisdom.
― Isaac Asimov
The archetype of a lgorithmic scaling is sorting a list, which is an amazingly common and important function for a computer program. Common sorting algorithms are things like insertion, or quick-sort, and each comes with a scaling for the memory required and the number of operations to work to completion. In most cases the best that can be done is linear scaling, in other words for a list that is
lgorithmic scaling is sorting a list, which is an amazingly common and important function for a computer program. Common sorting algorithms are things like insertion, or quick-sort, and each comes with a scaling for the memory required and the number of operations to work to completion. In most cases the best that can be done is linear scaling, in other words for a list that is 



 aspects of the algorithm and it’s scaling that speak to the memory-storage needed and the complexity of the algorithm’s implementation. These themes carry on to a discussion of more esoteric computational science algorithms next.
aspects of the algorithm and it’s scaling that speak to the memory-storage needed and the complexity of the algorithm’s implementation. These themes carry on to a discussion of more esoteric computational science algorithms next.
In scientific computing two categories of algorithm loom large over substantial swaths of the field: numerical linear algebra, and discretization-methods. Both of these categories have important scaling relations associated with their use that have a huge impact on the efficiency of solution. We have not been paying much attention at all to the efficiencies possible from these areas. Improvements in both areas could yield improvements in performance that would put any new computer to shame.
For numerical linear algebra the issue is the cost of solving the matrix problem with respect to the number of equations. For the simplest view of the problem one uses a naïve method like Gaussian elimination (or LU decomposition), which scales like 

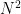

If an approximate solution is desired or useful one can use lower cost iterative methods. The simplest methods like the Jacobi or Gauss-Seidel iteration also scale at
Each of this sequence of methods has a constant in front of the scalin g, and the constant gets larger as scaling gets better. Nonetheless it is easy to see that if you’re solving a billion unknowns the difference between
g, and the constant gets larger as scaling gets better. Nonetheless it is easy to see that if you’re solving a billion unknowns the difference between
Learn from yesterday, live for today, hope for tomorrow. The important thing is to not stop questioning.
― Albert Einstein
 Discretization can provide even great wins. If a problem is amenable to high-order accuracy, a higher order method will unequivocally win over a low-order method. The problem is that most practical problems you can get paid to solve don’t have this property. In almost every case the solution will converge at a first-order accuracy. This is the nature of the world. The knee-jerk response is that this means that high-order methods are not useful. This shows a lack of understanding on what they bring to the table and how they scale. High-order methods produce lower errors than low-order methods even when high-order accuracy cannot be achieved.
Discretization can provide even great wins. If a problem is amenable to high-order accuracy, a higher order method will unequivocally win over a low-order method. The problem is that most practical problems you can get paid to solve don’t have this property. In almost every case the solution will converge at a first-order accuracy. This is the nature of the world. The knee-jerk response is that this means that high-order methods are not useful. This shows a lack of understanding on what they bring to the table and how they scale. High-order methods produce lower errors than low-order methods even when high-order accuracy cannot be achieved.
As a simple example take a high-order method that delivers half the error of a low order method. To get equivalent results the high-order method would take half the mesh defined by a number of “cell” or “elements” per dimension 



 The counter-point to these methods is their computational cost and complexity. The second issue is their fragility, which can be recast as their robustness or stability in the face of real problems. Still their performance gains are sufficient to amortize the costs given the vast magnitude of the accuracy gains and effective scaling.
The counter-point to these methods is their computational cost and complexity. The second issue is their fragility, which can be recast as their robustness or stability in the face of real problems. Still their performance gains are sufficient to amortize the costs given the vast magnitude of the accuracy gains and effective scaling.
An expert is a person who has made all the mistakes that can be made in a very narrow field.
― Niels Bohr
 The last issue to touch upon is the need to make algorithms robust, which is just another word for stable. Work on stability of algorithms is simply not happening these days. Part of the consequence is a lack of progress. For example one way to view the lack of ability of multigrid to dominate numerical linear algebra is its lack of robustness (stability). The same thing holds for high-order discretizations, which are typically not as robust or stable as low order ones. As a result low-order methods dominate scientific computing. For algorithms to prosper work on stability and robustness needs to be part of the recipe.
The last issue to touch upon is the need to make algorithms robust, which is just another word for stable. Work on stability of algorithms is simply not happening these days. Part of the consequence is a lack of progress. For example one way to view the lack of ability of multigrid to dominate numerical linear algebra is its lack of robustness (stability). The same thing holds for high-order discretizations, which are typically not as robust or stable as low order ones. As a result low-order methods dominate scientific computing. For algorithms to prosper work on stability and robustness needs to be part of the recipe.
If we knew what it was we were doing, it would not be called research, would it?
― Albert Einstein
Performance is a monotonically sucking function of time. Our current approach to HPC will not help matters, and effectively ignores the ability of algorithms to make things better. So “do we have the right priorities?” and “is this goal (of computing supremacy) important and worthy of achieving?” The answers are an unqualified NO and a qualified YES. The goal of computing dominance and supremacy is certainly worth achieving, but having the fastest computer will absolutely not get us there. It is neither necessary, nor sufficient for success.
This gets to the issue of priorities directly. Our c urrent program is so intellectually bankrupt as to be comical, and reflects a starkly superficial thinking that ignores the sort of facts staring them directly in the face such as the evidence of commercial computing. Computing matters because of how it impacts the real world we live it. This means the applications of computing matter most of all. In the approach to computing taken today the applications are taken completely for granted, and reality is a mere afterthought.
urrent program is so intellectually bankrupt as to be comical, and reflects a starkly superficial thinking that ignores the sort of facts staring them directly in the face such as the evidence of commercial computing. Computing matters because of how it impacts the real world we live it. This means the applications of computing matter most of all. In the approach to computing taken today the applications are taken completely for granted, and reality is a mere afterthought.
Any sufficiently advanced technology is indistinguishable from magic.
― Arthur C. Clarke