“We don’t want to change. Every change is a menace to stability.” ― Aldous Huxley
There is a problem with finishing up a blog post on a vacation day, you forget one of the nice ideas you wanted to share. So here is a brief addendum to what I wrote yesterday.
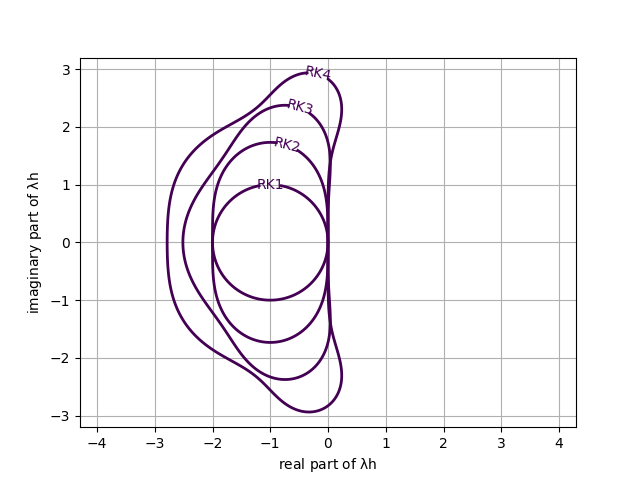
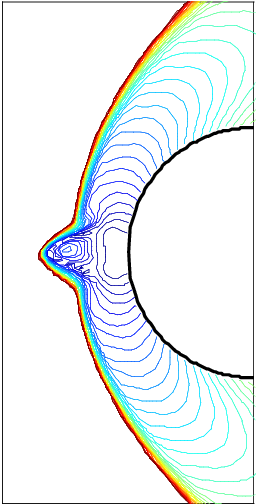
Here is a little addition to my last post here. It is another type of test I’ve tried, but also seldom seen documented. A standard threat to numerical methods is violating stability conditions. Stability is one of the most important numerical concepts. It is a prerequisite for convergence and is usually implicitly assumed. What is not usually tested is an active test of the transition of a calculation to instability. The simplest way to do this is to violate the time step size determined for instability.
The tests are simple. Basically, run the code with time steps over the stability limit and observe how sharp the limits are in practice. It also does a good job of documenting what an instability actually looks like when it appears. If the limit is not sharp, it might indicate an opportunity to improve the code by sharpening a bound. One could also examine if the lack of stability inhibits convergence, too. This would just be cases where the instability is mild and not catastrophic.
I did this once in my paper with Jeff Greenough, comparing a couple of methods for computing shocks. In this case, the test was the difference between linear and nonlinear stability for a Runge-Kutta integrator. The linear limit is far more generous than the nonlinear limit (by about a factor of three!). The accuracy of the method is significantly impacted at the limit of each of the two conditions. For shock problems, the difference in solutions and accuracy is much stronger. It also impacts the efficiency of the method a great deal.
Greenough, J. A., and W. J. Rider. “A quantitative comparison of numerical methods for the compressible Euler equations: fifth-order WENO and piecewise-linear Godunov.” Journal of Computational Physics 196, no. 1 (2004): 259-281.
The standard narrative for code verification is demonstrating correctness and finding bugs. While this is true, it also sells verification as a practice that is wildly short. Code verification has a myriad of other uses, foremost the assessment of accuracy without ambiguity. It can also define features of code, such as adherence to invariants in solutions. Perhaps, most compellingly, it can define the limits of a code-method and research needs to advance capability.
“Details matter, it’s worth waiting to get it right.” ― Steve Jobs
What People Think It Does
There is a standard accepted narrative for code verification. It is a technical process of determining that a code is correct. A lack of correctness is caused by bugs in the code that implements a method. It is supported by two engineering society standards written by AIAA (aerospace engineers) and ASME (mechanical engineers). The DOE-NNSA’s computing program, ASC, has adopted the same definition. It is important for the quality of code, but it is drifting to obscurity and a lack of any priority. (Note the IEEE has a different definition for verification, leading to widespread confusion.)
The definition has several really big issues that I will discuss below. Firstly, the definition is too limited and arguably wrong in emphasis. Secondly, it means that most of the scientific community doesn’t give a shit about it. It is boring and not a priority. It plays a tiny role in research. Thirdly, it sells the entire practice short by a huge degree. Code verification can do many important things that are currently overlooked and valuable. Basically there are a bunch of reasons to give a fuck about it. We need to stop undermining the practice.
The basics of code verification are simple. A method for solving differential equations has an ideal order of accuracy. Code verification compares the solution by the code with an analytical solution over a sequence of meshes. If the order of accuracy observed matches the theory, the code is correct. If it does not, the code has an error either in the code or in the construction of the method. One of the key reasons we solve differential equations with computers is the dearth of analytical solutions. For most circumstances of practical interest, there is no analytical solution, nor circumstances that match the order of accuracy of method design.
One of the answers to the dearth of analytical solutions is the practice of the method of manufactured solutions (MMS). It is a simple idea in concept where an analytical right-hand side is added to equations to force a solution. The forced solution is known and ideal. Using this practice, the code can be studied. The technique has several practical problems that should be acknowledged. First is the complexity of these right-hand sides is often extreme, and the source term must be added to the code. It makes the code different than the code used to solve practical problems in this key way. Secondly, the MMS problems are wildly unrealistic. Generally speaking, the solutions with MMS are dramatically unlike any realistic solution.
MMS simply expands the distance of code verification for the code’s actual use. All this does is amplify the degree to which code users disdain code verification. The whole practice is almost constructed to destroy the importance of code verification. It’s also pretty much dull as dirt. Unless you just love math (some of us do), MMS isn’t exciting. We need to move forward towards practices people give a shit about. I’m going to start by naming a few.
“If you thought that science was certain – well, that is just an error on your part.” ― Richard P. Feynman
It Can Measure Accuracy
“I learned very early the difference between knowing the name of something and knowing something.” ― Richard P. Feynman
I’ve already taken a stab at this topic, noting that code verification needs are refresh:
Here, I will just recap the first and most obvious overlooked benefit, measuring the meaningful accuracy of codes. Code verification’s standard definition concentrates on order of accuracy as the key metric. Practical solutions with code rarely achieve the design order of accuracy. This further undermines code verification as significant. Most practical solutions give first-order accuracy (or lower). The second metric from verification is error, and with analytical solutions, you can get precise errors from the code. The second thing to focus on is the efficiency of a code that connects directly.
A practical measure of code efficiency is accuracy per unit effort. Both of these can be measured with code verification. One can get the precise errors by solving a problem with an analytical solution. By simultaneously measuring the cost of the solution, the efficiency can be assessed. For practical use, this measurement means far more than finding bugs via standard code verification. Users simply assume codes are bug-free and discount the importance of this. They don’t actually care much because they can’t see it. Yes, this is dysfunctional, but it is the objective reality.
The measurement and study of code accuracy is the most straightforward extension of the nominal dull as dirt practice. There’s so much more as we shall see..
It Can Test Symmetries
“Symmetry is what we see at a glance; based on the fact that there is no reason for any difference…” ― Blaise Pascal
One of the most important aspect of many physical laws are symmetries. These are often preserved by ideal versions of these laws (like the differential equations code’s solve). Many of these symmetries are solved inexactly by methods in codes. Some of these symmetries are simple, like preservation of geometric symmetry, such as cylindrical or spherical flows. This can give rise to simple measures that accompany classical analytical solutions. The symmetry measure can augment the standard verification approach with additional value. In some applications, the symmetry is of extreme importance.
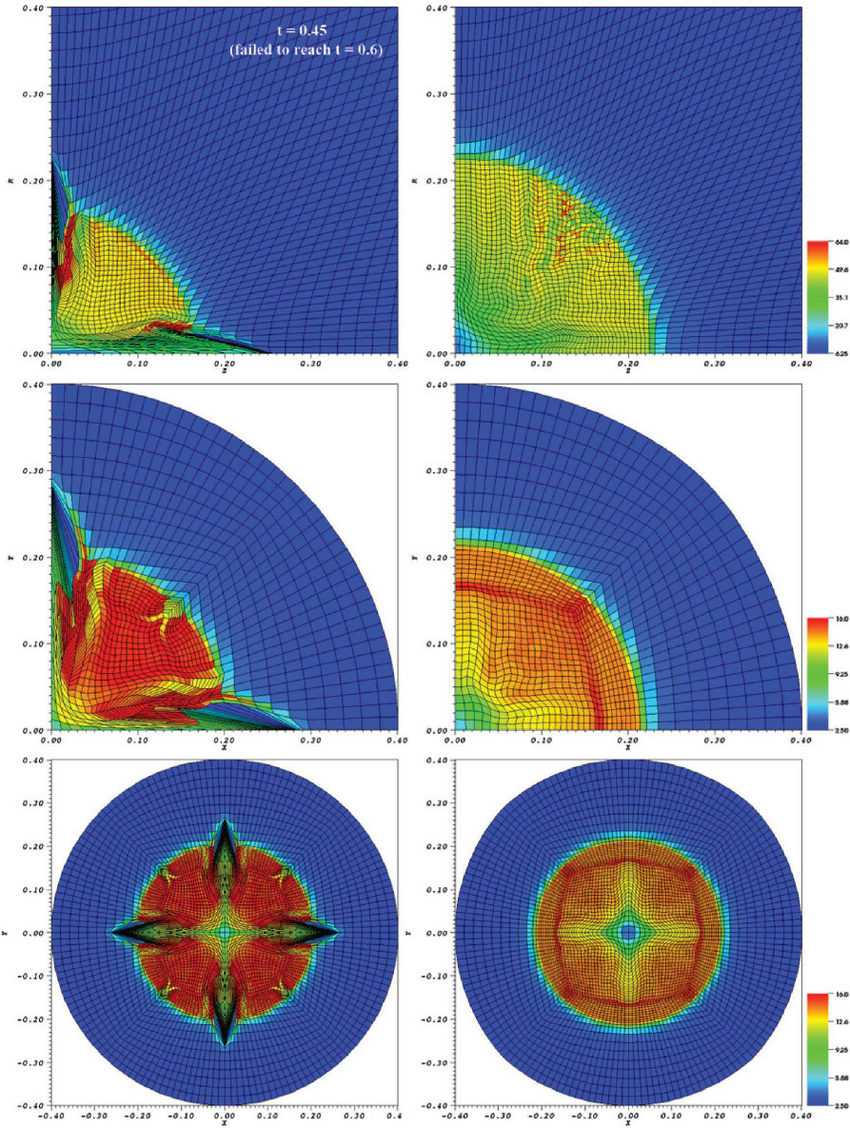
There are many more problems that can be examined for symmetry without having an analytical solution. One can create all sorts of problems with symmetries built into the solution. A good example of this is a Rayleigh-Taylor instability problem with a symmetry plane where left-right symmetry is desired. The solution can be examined as a function of time. This is an instability, and the challenge to symmetry grows over time. As the problem evolves forward the lack of symmetry becomes more difficult to control. It makes the test extreme if run for very long times. Symmetry problems also tend to grow as the mesh is refined.
It is a problem I used over 30 years ago to learn how to preserve stability. It was an incompressible variable-density code. I found the symmetry could be threatened by two main parts of the code: the details of upwinding in the discretization, and numerical linear algebra. I found that the pressure solve needed to be symmetric as well. I had to modify each part of the algorithm to get my desired result. The upwinding had to be changed to avoid any asymmetry concerning the sign of upwinding. This sort of testing and improvement is the hallmark of high-quality code and algorithms. Too little of this sort of work is taking place today.
It Can Find “Features”
“A clever person solves a problem. A wise person avoids it.” ― Albert Einstein
The usual mantra for code verification is lack of convergence means a bug. This is not true. This is a very naive and limiting perspective. For codes that compute the solution to shock waves (and weak solutions), correct solutions require conservation and entropy conditions. Methods and codes do not always adhere to these conditions. In those cases, a “perfect” bug-free code will produce incorrect solutions. They will converge on a solution, just converge to the wrong solution. The wrong solution is a feature of the method and code. These wrong solutions are revealed easily by extreme solutions with very strong shocks.
These features are easily fixed by using different methods. The problem is that the codes with these features are the product of decades of investment and reflect deeply held cultural norms. Respect for verification is acutely not one of those norms. My experience is that users of these codes make all sorts of excuses for this feature. Mostly, this sounds like the systematic devaluing of the verification work and excuses for ignoring the problem. Usually, they start talking about how important the practical work the code does. They fail to see how damning the results of failing to solve these problems. Frankly, it is a pathetic and unethical stand. I’ve seen this over and over at multiple Labs.
Before I leave this topic, I will get to another example of a code feature. This has a similarity to the symmetry examination. Shock codes can often have a shock instability with a funky name, the carbuncle phenomenon. This is where you have a shock aligned with a grid, and the shock becomes non-aligned and unstable. This feature is a direct result of properly implemented methods. It is subtle and difficult to detect. For a large class of problems, it is a fatal flaw. Fixing the problem requires some relatively simple but detailed changes to the code. It also shows up in strong shock problems like Noh and Sedov. At the symmetry axes, the shocks can lose stability and show anomalous jetting.
This gets to the last category of code verification benefits, determining a code’s limits and a research agenda.
“What I cannot create, I do not understand.” ― Richard P. Feynman
It Can Find Your Limits and Define Research
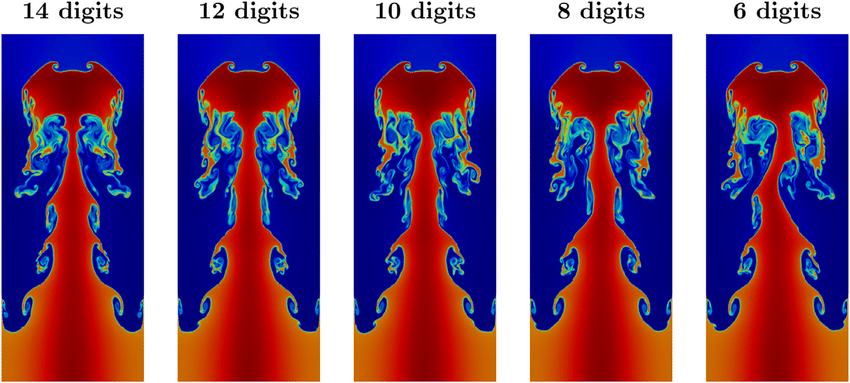
If you are doing code verification correctly, the results will show you a couple of key things: what the limits of the code are, and where research is needed. My philosophy of code verification is to beat the shit out of a code. Find problems that break the code. The better the code is, the harder it is to break. The way you break the code is to define harder problems with more extreme conditions. One needs to do research to get to the correct convergent solutions.
Where the code breaks is a great place to focus on research. Moving the horizons of capability outward can define an excellent and useful research agenda. In a broad sense, the identification of negative features is a good practice (the previous section). Another example of this is extreme expansion waves approaching vacuum conditions. In the past, I have found that most usual shock methods cannot solve this problem well. Solutions are either non-convergent or so poorly convergent as to render the code useless.
This problem is not altogether surprising given the emphasis on methods. Computing shock waves has been the priority for decades. When a method cannot compute a shock properly, the issues are more obvious. There is a clear lack of convergence in some cases or catastrophic instability. Expansion waves are smooth, offering less challenge, but they are also dissipation-free and nonlinear. Methods focused on shocks shouldn’t necessarily solve them well (and don’t when they’re strong enough).
I’ll close by another related challenge. The use of methods that are not conservative is driven by the desire to compute adiabatic flows. For some endeavors like fusion, adiabatic mechanisms are essential. Conservative methods necessary for shocks often (or generally) cannot compute adiabatic flows well. A good research agenda might be finding the methods that can achieve conservations, preserving adiabatic flows, and strong shock waves. A wide range of challenging verification test problems is absolutely essential for success.
“The first principle is that you must not fool yourself and you are the easiest person to fool.” ― Richard P. Feynman
Uncertainty quantification (UQ) is ascending while verification & validation (V&V) is declining. UQ is largely done in silico and offers results that trivially harness modern parallel computing. UQ thus parallels the appeal of AI and easy computational results. It is also easily untethered to objective reality. V&V is a deeply technical and naturally critical practice. Verification is extremely technical. Validation is extremely difficult and time-consuming. Furthermore, V&V can be deeply procedural and regulatory. UQ has few of these difficulties although its techniques are quite technical. Unfortunately, UQ without V&V is not viable. In fact, UQ without the grounding of V&V is tailor-made for bullshit and hallucinations. The community needs to take a different path that mixes UQ with V&V, or disaster awaits.
“Doubt is an uncomfortable condition, but certainty is a ridiculous one.” ― Voltaire
UQ is Hot
If one looks at the topics of V&V and UQ, it is easy to see that UQ is a hot topic. It is vogue and garners great attention and support. Conversely, V&V is not. Before I give my sharp critique of UQ, I need to make something clear. UQ is extremely important and valuable. It is necessary. We need better techniques, codes, and methodologies to produce estimates of uncertainty. The study of uncertainty is guiding us to grapple with a key topic; how much we don’t know? This is difficult and uncomfortable work. Our emphasis on UQ is welcome. That said, this emphasis needs to be grounded in reality. I’ve spoken in the past about the danger of ignoring uncertainty. When an uncertainty is ignored it gets the default value of ZERO. In other words, ignored uncertainties are assigned the smallest possible value.
“The quest for certainty blocks the search for meaning. Uncertainty is the very condition to impel man to unfold his powers. ” ― Erich Fromm
As my last post discussed, the focus needs to be rational and balanced. When I observe the current conduct of UQ research, I see neither character. UQ takes on the mantle of the silver bullet. It is subject to the fallacy of the “free lunch” solutions. It seems easy and tailor-made for our currently computationally rich environment. It produces copious results without many of the complications of V&V. The practice of V&V is doubt based on deep technical analysis. It is uncomfortable and asks hard questions. Often questions that don’t have easy or available answers. UQ just gives answers with ease and it’s semi-automatic, in silico. You just need lots of computing power.
“I would rather have questions that can’t be answered than answers that can’t be questioned.” ― Richard Feynman
This ease gets to the heart of the problem. UQ needs validation to connect it to objective reality. UQ needs verification to make sure the code is faithfully correct to the underlying math. Neither practice is so well established that it can be ignored. Yet, increasingly, they are being ignored. Experimental results are needed to challenge our surety. UQ has a natural appetite for computing thus our exascale computers lap it up. It is a natural way to create vast amounts of data. UQ attaches statistics naturally to modeling & simulation, a long-standing gap. Statistics connects to machine learning as it is the algorithmic extension of statistics. The mindset parallels the euphoria recently for AI.
For these reasons, UQ is a hot topic and attracting funding and attention today. Being in silico UQ becomes an easy way to get V&V-like results from ML/AI. What is missing? For the most part, UQ is done assuming V&V is done. For AI/ML this is a truly bad assumption. If you’re working in simulation you know that assumption is suspect. The basics of V&V are largely complete, but its practice is haphazard and poor generally. My observation is that computational work has regressed concerning V&V. Advances made in publishing and research standards have gone backward in recent years. Rather than V&V being completed and simply applied, it is dispised.
All of this equals a distinct danger for UQ. Without V&V UQ is simply an invitation for ModSim hallucinations akin to the problem AI has. Worse yet, it is an invitation to bullshit the consumers of simulation results. Answers can be given knowing they have a tenuous connection to reality. It is a recipe to fool ourselves with false confidence.
“The first principle is that you must not fool yourself and you are the easiest person to fool.” ― Richard P. Feynman
AI/ML Feel Like UQ and Surrogates are Dangerous
One of the big takeaways from the problems with UQ is the appeal of its in-silico nature. This paves the way to easy results. Once you have a model and working simulation UQ is like falling off a log. You just need lots of computing power and patience. Yes, it can be improved and made more accurate and efficient. Nonetheless, UQ asks no real questions about the results. Turn the crank and the results fall out (unless it triggers a problem with the code). You can easily get results although doing this efficiently is a research topic. Nonetheless being in silico removes most of the barriers. Better yet, it uses the absolute fuck out of supercomputers. You can so fill a machine up with calculations. You get results galore.
If one is paying attention to the computational landscape you should be experiencing deja vu. AI is some exciting in-silico shit that uses the fuck out of the hardware. Better yet, UQ is an exciting thing to do with AI (or machine learning really). Even better you can use AI/ML to make UQ more efficient. We can use computational models and results to train ML models that can cheaply evaluate uncertainty. All those super-fast computers can generate a shitload of data. These are called surrogates and they are all the rage. Now you don’t have to run the expensive model anymore; you just train the surrogate and evaluate the fuck out of it on the cheap. Generally machine learning is poor at extrapolating, and in high dimensions (UQ is very high dimensional) you are always extrapolating. You better understand what you’re doing and machine learning isn’t well understood.
What could possibly go wrong?
If the model you trained the surrogate on has weak V&V, a lot can go wrong. You are basically evaluating bullshit squared. Validation is essential to establishing how good a model is. You should produce a model form error that expresses how well the computational model works. The model also has numerical errors due to the finite representation of the computation. I can honestly say that I’ve never seen either of these fundamental errors associated with a surrogate. Nonetheless, surrogates are being developed to power UQ all over the place. It’s not a bad idea, but these basic V&V steps should be an intrinsic part of this. To me, the state of affairs says more about the rot at the heart of the field. We have lost the ability to seriously question computed results. V&V is a vehicle for asking these questions. These questions are too uncomfortable to be confronted with.
V&V is Hard; Too Hard?
I’ve worked at two NNSA Labs (Los Alamos and Sandia) in the NNSA V&V program. So I know where the bodies are buried. I’ve been part of some of the achievements of the program and where it has failed. I was at Los Alamos when V&V arrived. It was like pulling teeth to make progress. I still remember the original response to validation as a focus, “Every calculation a designer does is all the validation we need!” The Los Alamos weapons designers wanted hegemonic control over any assessment of simulation quality. Code developers, computer scientists, and any non-designer were deemed incompetent to assess quality. To say it was an uphill battle was an understatement. Nonetheless, progress was made, albeit mildly.
V&V fared better at Sandia. In many ways, the original composition of the program had its intellectual base at Sandia. This explained a lot of the foundational resistance from the physics labs. It also gets too much of a problem with V&V today. Its focus on the credibility of simulations makes it very process-oriented and regulatory. As such it is eye-rollingly boring and generates hate. This character was the focus of the opposition at Los Alamos (Livermore too). V&V has too much of an “I told you so” vibe. No one likes this and V&V starts to get ignored because it just delivers bad news. Put differently, V&V asks lots of questions but generates few answers.
Since budgets are tight and experiments are scarce, the problems grow. We start to demand calculations to have close agreement with available data. Early predictions typically don’t meet standards. By and large, simulations have a lot of numerical error even on the fastest computers. The cure for this is an ex-post-facto calibration of the model to match experiments better. The problem is that this then short-circuits validation. Basically, there is little or no actual validation. Almost everything is calibrated unless the simulation is extremely easy. The model has a fixed grid, so there’s no verification either. Verification is bad news without a viable current solution. What you can do with such a model is lots of UQ. Thus UQ becomes the results for the entire V&V program.
To really see this clearly we need to look West to Livermore.
What does UQ mean without V&V?
I will say up front that I’m going to give Livermore’s V&V program a hard time, but first, they need big kudos. The practice of computational physics and science at Livermore is truly first-rate. They have eclipsed both Sandia and Los Alamos in these areas. They are exceptional code developers and use modern supercomputers with immense skill. They are a juggernaut in computing.
By almost any objective measure Livermore’s V&V program produced the most important product of the entire ASC program, common models. Livermore has a track record of telling Washington one thing and doing something a bit different. Even better, this something different is something better. Not just a little better, but a lot better. Common models are the archetypical example of this. Back in the 1990’s, there was this metrics project looking at validating codes. Not a terrible idea at all. In a real sense, Livermore did do the metrics in the end but took a different smarter path to them.
What Livermore scientists created instead was a library of common models that combined experimental data, computational models, and auxiliary experiments. The data was accumulated across many different experiments and connected into a self-consistent set of models. It is an incredible product. It has been repeated at Livermore and then at Los Alamos too across the application space. I will note that Sandia hasn’t created this, but that’s another story of differences in Lab culture. These suites of common models are utterly transformative to the program. It is a massive achievement. Good thing too because the rest of V&V there is far less stellar.
What Livermore has created instead is lots of UQ tools and practice. The common models are great for UQ too. One of the first things you notice about Livermore’s V&V is the lack of V&V. Verification leads the way in being ignored. The reasons are subtle and cultural. Key to this is an important observation about Livermore’s identity as the fusion lab. Achieving fusion is the core cultural imperative. Recently, Livermore has achieved a breakthrough at the National Ignition Facility (NIF). This was “breakeven” in terms of energy. They got more fusion energy out than laser energy in for some NIF experiments (all depends on where you draw the control volume!).
The NIF program also has the archetypical example of UQ gone wrong. Early on in the NIF program, there was a study of fusion capsule design and results. They looked at a large span of uncertainties in the modeling of NIF and NIF capsules. It was an impressive display of the UQ tools developed by Livermore, their codes, and computers. At the end of the study, they created an immensely detailed and carefully studied prediction of outcomes for the upcoming experiments. This was presented as a probability distribution function of capsule yield. It covered an order of magnitude from 900 kJ to 9 MJ of yield. When they started to conduct experiments, the results were not even in the range predicted by about a factor of three on the low side. The problems and dangers of UQ were laid bare.
“The mistake is thinking that there can be an antidote to the uncertainty.” ― David Levithan
If you want to achieve fusion the key is really hot and dense matter. The way to get this hot and dense matter is to adiabatically compress the living fuck out of material. To do this there is a belief in numerical Lagrangian hydrodynamics with numerical viscosity turned off in adiabatic regions gives good results. The methods they use are classical and oppositional to modern shock-capturing methods. To compute shocks properly needs dissipation and conservation. The ugly reality is that hydrodynamic mixing (excessively non-adiabatic dissipative and ubiquitous) is an anathema to Lagrangian methods. Codes need to leave the Lagrangian frame of reference and remap. Conserving energy is one considerable difficulty.
Thus, the methods favored at Livermore cannot successfully pass verification tests for strong shocks. Thus, verification results are not shown. For simple verification problems there is a technique to get good answers. The problem is that the method doesn’t work on applied problems. Thus, good verification results for shocks don’t apply to key cases where the codes are used. They know the results will be bad because they are following the fusion mantra. Failure to recognize the consequences of bad code verification results is magical thinking. Nothing induces magical thinking like a cultural perspective that values one thing over all others. This is a form of extremism discussed in the last blog post.
There are two unfortunate side effects. The first obvious one is the failure to pursue numerical methods that simultaneously preserve adiabats and compute shocks correctly. This is a serious challenge for computational physics. It should be vigorously pursued and developed by the program. It also represents a question asked by verification without an easy answer. The second side effect is a complete commitment to UQ as the vehicle for V&V where answers are given and questions aren’t asked. At least not really hard questions.
UQ is left and becomes the focus. It is much better for results and for giving answers. If those answers don’t need to be correct, we have an easy “success.”
“It doesn’t matter how beautiful your theory is, it doesn’t matter how smart you are. If it doesn’t agree with experiment, it’s wrong.” ― Richard P. Feynman
A Better Path Forward
Let’s be crystal clear about the UQ work at Livermore, it is very good. Their tools are incredible. In a purely in silico way the work is absolutely world-class. The problems with the UQ results are all related to gaps in verification and validation. The numerical results are suspect and generally under-resolved. The validation of the models is lacking. This gap is chiefly from the lack of acknowledgment of calibrations. Calibration of results is essential for useful simulations of challenging systems. NIF capsules are one obvious example. Global climate models are another. We need to choose a better way to focus our work and use UQ properly.
“Science is what we have learned about how to keep from fooling ourselves.” ― Richard Feynman
My first key recommendation is to ground validation with calibrated models. There needs to be a clear separation of what is validated and what is calibrated. One of the big parts of the calibration is the finite mesh resolution of the models. Thus the calibrations mix both model form error and numerical error. All of this needs to be sorted out and clarified. In many cases, these are the dominant uncertainties in simulations. They swallow and neutralize the UQ we spend our attention on. This is the most difficult problem we are NOT solving today. It is one of the questions raised by V&V that we need to answer.
“Maturity, one discovers, has everything to do with the acceptance of ‘not knowing.” ― Mark Z. Danielewski
The practice of verification is in crisis. The lack of meaningful estimates of numerical error in our most important calculation is appalling. Code verification has become a niche activity without any priority. Code verification for finding bugs is about as important as taking your receipt with you from the grocery store. Nice to have, but it’s very rarely checked by anybody. When it is checked, it’s because you’re probably doing something a little sketchy. Code verification is key to code and model quality. It needs to expand in scope and utility. It is also the recipe for improved codes. Our codes and numerical methods need to progress, They must continue to get better. The challenge of correctly computing strong shocks and adiabats is but one. There are many others that matter. We are still far from meeting our modeling and simulation needs.
“What I cannot create, I do not understand.” ― Richard P. Feynman
Ultimately we need to recognize how V&V is a partner to science. It asks key questions of our computational science. It is then the goal to meet these questions with a genuine search for answers. V&V also provides evidence of how well the question is answered, This question-and-answer cycle is how science must work. Without the cycle, progress stalls, and the hopes of the future are put at risk.
“If you thought that science was certain – well, that is just an error on your part.” ― Richard P. Feynman
Today’s world is ruled by extreme views and movements. These extremes are often a direct reaction to progress and change. People often prefer order and a well-defined direction. The current conservative backlash is a reaction. Much of it is based on the discomfort of social progress and economic disorder. In almost all things balance and moderation are a better path. The middle way leads to progress that sticks. Slow and deliberate change is accepted, while fast and precipitous change invites opposition. I will discuss how this plays out in both politics and science. In science, many elements contribute to the success of any field. These elements need to be present for success. Without the balance failure is the ultimate end. Peter Lax’s work was an example of this balance.
“All extremes of feeling are allied with madness.” ― Virginia Woolf
The Extremes Rule Today
It is not controversial to say that today’s world is dominated by extremism. What is a bit different is to point to the world of science for the same trend. The political world’s trends are illustrated vividly on screens across the World. We see the damage these extremes are doing in the USA, Russia, Israel-Gaza and everywhere online. One extreme will likely breed an equal and opposite reaction. Examples abound today such as over-regulation or political correctness in the USA. In each, true excesses are greeted with equal or greater excesses reversing them.
Science is not immune to these trends and excesses. I will detail below a couple of examples where no balance exists. One program is the exascale computing program which focuses on computational hardware. A second example is the support for AI. It is similarly hardware-focused. In both cases, we fail to recognize how the original success was catalyzed. The impacts, the need, and the route to progress are not seen clearly. We have programs that can only see computing hardware and fail to see the depth and nature of software.
In science software is a concrete instantiation of theory and mathematics. If theory and math are not supported, the software is limited in value. The progress desired by these efforts is effectively short-circuited. In computing, software has the lion’s share of the value. Hardware is necessary, but not where the largest advances have occurred. Yet the hardware is the most tangible and visible aspect of technology. In a mathematical parlance, the hardware is necessary, but not sufficient. We are advancing science in a clearly insufficient way.
“To put everything in balance is good, to put everything in harmony is better.” ― Victor Hugo
Balance in All Things
Extremism is simple. Reality is complex. Simple answers fall apart upon meeting the real World. This is true for politics and science. When extreme responses to problems are implemented, they invite an opposite extreme reaction. Lasting solutions require a subtle balance of perspectives and sources of progress. The best from each approach is necessary.
Take the issue of over-regulation as an example. Simply removing regulations invites the same forces that created the over-regulation in the first place. A far better approach is to pare back regulation thoughtfully. Careful identification of excess regulation build support for the project. The same thing applies to the freedom of speech and the excesses of “woke” or “cancel culture”. Those movements overstepped and created a powerful backlash. They were also responding to genuine societal problems of bigotry and oppressive hierarchy. A complete reversal is wrong and will create horrible excesses inviting a reverse backlash. Again, smaller changes that balance progress with genuine freedom would be lasting.
With those examples in mind, let us turn to science. In the computational world, we have seen a decade of excess. First with computing and pursuit of exascale high-performance computing. Next, in a starkly similar fashion artificial intelligence became an obsession. Current efforts to advance AI are focused on computational hardware. Other sources of progress are nearly ignored. In each case, there is serious hype along with an appealing simplicity in the sales pitch. In both cases, the simple approach short-changes progress and hampers broader success and long-term progress.
Let’s turn briefly to what a more balanced approach would look like.
At the core of any discussion of science should be the execution of the scientific method. This has two key parts working in harmony, theory and experiment (observation). Making these two approaches harmonize is the route to progress. Theory is usually expressed in mathematics and is most often solved on computers. If this theory describes what can be measured in the real world, we believe that we understand reality. Better yet, we can predict reality leading to engineering and control. Our technology is a direct result of this and much of our societal prosperity.
With this foundation, we can judge other scientific efforts. Take the recent Exascale program, which focused on creating faster supercomputers. The project focused on computing hardware and computer science while not supporting mathematics and theory vibrantly. This is predicated on some poor assumptions that theory is adequate (it isn’t) and our math is healthy. Both the theory and math need sustained attention. Examining history shows that math and theory have been to core of progress in computing. It is worse than this. The exascale focus came as Moore’s law ended. This was the exponential growth in computing power that held for almost a half-century starting in 1965. Its end was largely based on encountering physical barriers to progress. The route to increased computing value should shift to theory and math (i.e., algorithms). Yet, the focus was on hardware trying to breathe life into the dying Moore’s law. It is both inefficient and ultimately futile
Today, we see the same thing happening with AI. The focus is on computing hardware even though the growth in power is incremental. Meanwhile, the massive breakthrough in AI was enabled by algorithms. Limits on trust and correctness of AI are also grounded in the weakness of the underlying math for AI. A more vibrant and successful AI program would reduce hardware focus and increase math and algorithm support. This would serve both progress and societal needs. Yet we see the opposite.
We are failing to learn from our mistakes. The main reason is that we can’t call them mistakes. In every case, we are seeing excess breed more excess. Instead, we should balance and strike a middle way.
“Progress and motion are not synonymous.” ― Tim Fargo
A Couple Examples
The USA today is living through a set of extremes that are closely related. There is a burgeoning authoritarian oligarchy emerging as the central societal power. Much of the blame for this development is out-of-control capitalism without legal boundaries. There is virtually limitless wealth flowing to a small number of individuals. With this wealth, political power is amassing. A backlash is inevitable. The worst correction to this capitalist overreach would be a suspension of capitalism. Socialism seems to be the obvious cure. A mistake would be too much socialism. It would throw the baby up with the bathwater. A mixture of capitalism and socialism works best. A subtle balance of the two is needed. The most obvious societal example is health care where capitalism is a disaster. We have huge costs with worse outcomes.
In science, recent years have seen an overemphasis on computing hardware over all else. My comments apply to exascale and AI with near equality. Granted there are differences in the computing approach needed for each, but commonality is obvious. The value of that hardware is bound to software. Software’s value is bound to algorithms, which in turn are grounded in mathematics. That math can be discrete, information-related, or a theory of the physical world. This pipeline is the route to computing’s ability to transform our world and society. The answer is not to ignore hardware but to moderate it with other parts of the computing recipe for science. Without that balance the pipeline empties and becomes stale. That has probably already happened.
As I published this article, news of the death of Peter Lax arrived. I was buoyed by the prominence of his obituary in the New York Times. Peter’s work was essential to my career, and it is good to see him appropriately honored. Peter was the epitome of the creation of the value in the balance I’m discussing here. He was the consummate mathematical genius applying it to solve essential problems. While he contributed to applications of math, his work had the elegance and beauty of pure math. He also recognized the essential role of computing and computers. We would be wise to honor his contributions by following his path more closely. I’ve written about Peter and his work on several occasions here (links below).
“Keep in mind that there is in truth no central core theory of nonlinear partial differential equations, nor can there be. The sources of partial differential equations are so many – physical, probalistic, geometric etc. – that the subject is a confederation of diverse subareas, each studying different phenomena for different nonlinear partial differential equation by utterly different methods.”– Peter Lax
“It is impossible for someone to lie unless he thinks he knows the truth. Producing bullshit requires no such conviction.” ― Harry G. Frankfurt,On Bullshit
Its really cool when your blog post generates a lot of feedback. Its like when you give a talk, and you get lots of questions. It is a sign that people give a fuck. No questions, is not engagement and lots of no fucks given.
One friend sent me an article, “ChatGPT is Bullshit.” It was riffing on Harry Frankfurt’s amazing monograph, “On Bullshit.” To put it mildly, bullshit is much worse than a hallucination. Even if that hallucination is produced by drugs. Hallucinations are innocent and morally neutral. Bullshit is unethical. The paper makes the case that LLMs are bullshitting us, not offering some innocent hallucinations. We should apply the same standard to computational modeling of the classical sort.
This is, of course, not a case of anthropomorphizing the LLM. The people responsible for designing LLMs want it to provide answers. Providing answers makes the users of LLMs happy. Happy users use their product. Unhappy ones don’t. Bullshit is willful deception. It is deception with a purpose. We should be mindful about willful deception for classical modeling & simulation work. In a subtle way the absence of due diligence such as avoiding V&V is treading close to the line. If V&V is done and then silenced and ignored, you have bullshit. So I’ve seen a lot of bullshit in my career. So have you.
Bullshit is a pox. We need to recognize and eliminate bullshit. Bullshit is the enemy of truth. It is vastly worse than hallucinations and demands attention.
“The bullshitter ignores these demands altogether. He does not reject the authority of the truth, as the liar does, and oppose himself to it. He pays no attention to it at all. By virtue of this, bullshit is a greater enemy of the truth than lies are.” ― Harry G. Frankfurt,
Hicks, Michael Townsen, James Humphries, and Joe Slater. “ChatGPT is bullshit.” Ethics and Information Technology 26, no. 2 (2024): 1-10.
One of the most damning aspects of the amazing results from LLMs are hallucinations. These are garbage answers delivered with complete confidence. Is this purely an artifact of LLMs, or more common than believed? I believe the answer is yes. Classical modeling and simulations using differential equations can deliver confident results without credibility. In the service of prediction this can be common. It is especially true when the models are crude or heavily calibrated then used to extrapolate away from data. The key to avoiding hallucination is the scientific method. For modeling and simulation this means verification and validation. This requires care and due diligence be applied in all cases of computed results.
“It’s the stupid questions that have some of the most surprising and interesting answers. Most people never think to ask the stupid questions.” ― Cory Doctorow
What are Hallucinations in LLMs?
In the last few years one of the most stunning technological breakthroughs are Large Language Models (LLMs, like ChatGPT, Claude, Gemini …). This breakthough has spurred visions of achieving artificial general intelligence soon. The answers to queries are generally complete and amazing. In many contexts we see LLMs replacing search as a means of information gathering. It is clearly one of the most important technologies for the future. There is the general view of LLMs broadly driving the economy of our future. There is a blemish on this forecast, hallucinations! Some of these complete confident answers are partial to complete bullshit.
“I believe in everything until it’s disproved. So I believe in fairies, the myths, dragons. It all exists, even if it’s in your mind. Who’s to say that dreams and nightmares aren’t as real as the here and now?” ― John Lennon
A LLM answers questions with unwavering confidence. Most of the time this is well grounded in objective facts. Unfortunately, this confidence is shown when results are false. Many examples show that LLMs will make up answers that sound great, but are lies. I asked ChatGPT to create a bio for me and it constructed a great sounding lie. It had me born in 1956 (1963) with a PhD in Math from UC Berkeley (Nuke Engineering, New Mexico). Other times I’ve asked to elaborate on experts in fields I know well. More than half the information is spot on, but a few experts are fictional.
“It was all completely serious, all completely hallucinated, all completely happy.” ― Jack Kerouac
The question is what would be better?
In my opinion the correct response is for the LLM to say, “I don’t know.” “That’s not something I can answer.” To a some serious extent this is starting to happen. LLMs will tell you they don’t have the ability to answer a questions. You also get responses like “this questions violate their rules.” We see the LLM community responding to this terrible problem. The current state is imperfect and hallucinations still happen. The community guidelines for LLMs are tantamount to censorship in many cases. That said, they are moving toward dealing with it.
Do classical computational models have the same issue?
Are they dealing with problems as they should?
Yes and no.
“I don’t paint dreams or nightmares, I paint my own reality.” ― Frida Kahlo
What would Hallucination be in Simulation?
Standard computational modeling is thought to be better because it is based on physical principles. We typically solve well defined and accepted governing equations. These equations are solved in a manner that is based on well known mathematical and computer science methods. This is correct, but it is not bulletproof. The reasons are multiple. One of the principal ways problems occur are the properties of the materials in a problem. A second way is the inclusion of physics not included in the governing equations (often called closure). A third major category is the construction of a problem in terms of initial and boundary conditions, or major assumptions. Numerical solutions can be under-resolved or produce spurious solutions. Mesh resolution can be suspect or inadequete for the numerical solution. The governing equations themselves include assumptions that may not be true or apply to the problem being solved..
“Why should you believe your eyes? You were given eyes to see with, not to believe with. Your eyes can see the mirage, the hallucination as easily as the actual scenery.” ― Ward Moore
The major weakness is the need for closure of the physical models used. This can take the form of constitutive relations for the media in the problem. It also applies to unresolved sales or physics in the problem. Constitutive relations usually abide by well defined principles quite often grounded in thermodynamics. They are the product of considering the nature of the material at scales under the simulation’s resolution. Almost always these scales are considered to be averaged/mean values. Thus the variability in the true solution is excluded from the problem. Large or divergent physics can emerge if the variability of materials is great at the scale of the simulation. Simple logic dictates that this variability grows larger as the resolution of a simulation becomes smaller.
A second connected piece of this problem is subscale physics not resolved, but dynamic. Turbulence modeling is the classical version of this. These models have significantly limited applicability and great shortcomings. This gets to the first category of assumption that needs to be taken in account. Is the model being used in a manner appropriate for it. Models also interact heavily with the numerical solution. The numerical effects/errors can often mimic the model’s physical effects. Numerical dissipation is the most common version of this, Turbulence is a nonlinear dissipative process, and numerical diffusion is often essential for stability. Surrounding all of this is the necessity of identifying unresolved physics to begin with.
Problems are defined by analysts in a truncated version of the universe. The interaction of a problem with that universe is defined by boundary conditions. The analyst also defines a starting point for a problem if it involves time evolution. Usually the state a problem starts from in a simple quiessiant version of reality. Typically it is far more homogeneous and simple that how reality is. The same goes to the boundary conditions. Each of these decisions influences the subsequent solution. In general these selections make problem less dynamically rich than reality.
Finally, we can choose the wrong governing equations based on assumptions about a problem. This can include choosing equations that leave out major physical effects. A compressible flow problem cannot be described by incompressible equations. Including radiation or multi-material effects is greatly complicating. Radiation transport has a heirarchy of equations ranging from diffusion to full transport. Each level of approximation involves vast assumptions and loss of fidelity. The more complete the equations are physically, the more expensive they are. There is great economy in choosing the proper level for modeling. The wrong choice can produce results that are not meaningful for a problem.
Classical simulations are distiguished by the use of numerical methods to solve equations. This produces solution to these equations far beyond where they are analytical. These numerical methods are grounded in powerful proven mathematics. Of course, the proven powerful math needs to be used and listened to. When it isn’t the solutions are suspect. Too often corners are cut and the theory is not applied. This can result in poorly resolved or spurious solutions. Marginal stability can threaten solutions. Numerical solutions can be non-converged or poorly resolved. Some of the biggest issues numerically are seen with solutions labeled as direct numerical simulation (DNS). Often the declaration of DNS means all doubt and scrutiny is short-circuited. This is dangerous because DNS is often treated as a substitute for experiments.
These five categories of modeling problems should convince the reader that mistakes are likely. These errors can be large and create extremely unphysical results. If the limitations or wrong assumptions are not acknowledged or known, the solution might be viewed as hallucinations. The solution may be presented with extreme confidence. It may seem to be impressive or use vast amounts of computing power. It may be presented as being predictive and an oracle. This may be far from the truth
The conclusion is that classical modeling can definitely hallucinate too! Holy shit! Houston, we have a problem!
“Software doesn’t eat the world, it enshittifies it” – Cory Doctorow
How to Detect Hallucinations?
To find hallucinations, you need to look for them. There needs to be some active doubt applied to results given by the computer. Period.
The greatest risk is for computational results to be a priori believed. Doubt is a good thing. Much of the problem with hallucinating LLMs is the desire to give the user an answer no matter what. In the process of always giving an answer, bad answers are inevitable. Rather than reply that the answer can’t be given or is unreliable, the answer is given with confidence. In response to this problem LLMs have started to respond with caution.
“Would you mind repeating that? I’m afraid I might have lost my wits altogether and just hallucinated what I’ve longed to hear.” ― Jeaniene Frost
The same thing happens with classical simulations. In my experience the users of our codes want to always get an answer. If the codes succeed at this, some of the answers will be wrong. Solutions do not include any warnings or caveats. There are two routes to doing this. Technically the harder route is for the code itself to give warnings and caveats when used improperly. This would require the code’s authors to understand its limits. The other route is V&V. This requires the solutions to be examined carefully for credibility using standard techniques. Upon reflection, both routes go through the same steps, but applied systematically to the code’s solutions. The caveats are simply applied up front if the knowledge of limits is extensive. This can only be achieved through extensive V&V.
Some of these problems are inescapable. There is a way to minimize these hallucinations systematically. In a nutshell the scientific method offers the path for this. Again, we see verification and validation is the scientific method for computational simulation. It offers specific techniques and steps to guard against the problems outlined above. These steps offer an examination of the elements going into the solution. The suitability of the numerical solutions of the models and the models themsevles are examined critically. Detailed comparisons of solutions are made to experimental results. We see how well models produce solutions that model reality. Of course, this is expensive and time consuming. It is much easier to just accept solutions and confidently forge ahead. This is also horribly irresponsible.
“In the land of the blind, the one-eyed man is a hallucinating idiot…for he sees what no one else does: things that, to everyone else, are not there.” ― Marshall McLuhan
How to Prevent Hallucinations?
To a great extent the problem of hallucinations cannot be prevented. The question is whether the users of software are subjected to it without caution. An alternative is for the users to be presented with a notice of caution with results. This does point to the need for caution to be exercised for all computational results. This is true for classical simulations and LLM results. All results should be treated with doubt and scrutiny.
V&V is the route to this scrutiny. For classical simulation V&V is a well-developed field, but often not practiced. For LLMs (AI/ML) V&V is nascent and growing, but immature. In both cases, V&V is difficult and time consuming. The biggest impediment is to V&V is a lack of willingness to do it. The users of all computational work would rather just blindly accept results than apply due diligence.
For the users it is about motivation and culture. Is the pressure on getting answers and moving to the next problem? or getting the right answer? My observation is that horizons are short-term and little energy motivates getting the right answer. With fewer experiments and tests to examine the solutions, the answer isn’t even checked. Where I’ve worked this is about nuclear weapons. You would think that due diligence would be a priority. Sadly it isn’t. I’m afraid we are fucked. How fucked? Time will tell.
“We’re all living through the enshittocene, a great enshittening, in which the services that matter to us, that we rely on, are turning into giant piles of shit.” – Cory Doctorow