
tl;dr
If a simulation does not converge under mesh refinement, it is generally a bad thing. For most practical calculations, this is not even tested, which is even worse. For simulation, the notion of convergence is the basis of faith in investing in faster computers. In brief, you expect to approach the exact solution as you use more computing resources. This comes from a smaller mesh size or time step size, needing more computing. Generally, this is simply assumed and not checked. The reality is that this often does not emerge.
What are the consequences?
We have less reliability in simulations than we should. Problems and challenges with our current technology are not challenged and improved. Progress stagnates without the feedback of reality. The promise of computational science is undermined by our accepting lax practices.
Why This Matters?
“In numerical analysis, the Lax equivalence theorem is a fundamental theorem in the analysis of linear finite difference methods for the numerical solution of linear partial differential equations. It states that for a linear consistent finite difference method for a well-posed linear initial value problem, the method is convergent if and only if it is stable. ” – John Strikwerda


In computational science, the premise that faster computers yield better solutions is axiomatic. It provides unyielding confidence in the utility of computers for better science. As the Lax equivalence theorem states, it is not without conditions. It is not assured. The issue is that the necessary homework to ensure it is in effect is too rarely done. Most computational science today simply makes this assumption and treats convergence as a fait accompli. This is dangerous for the use of computation. It threatens progress and undermines the credibility and utility of the field.
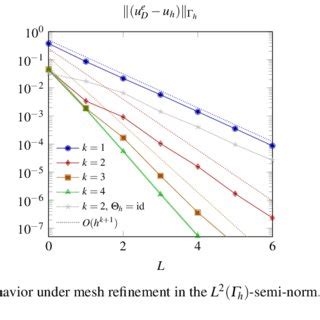
There are many reasons for this, mostly laziness or ignorance. The practice of code verification is firmly grounded in the equivalence theorem. Doing a code verification exercise makes this theorem actionable. The practice of code verification is relatively uncommon. It is definitely done far more in the case where full numerical accuracy can be achieved, i.e., smooth solutions often via the method of manufactured solutions. It is done far less often when calculations lose smoothness. This gets to a couple of large gaps in practice:
1. Code verification allows precise error estimation,
2. Code verification can still be done on solutions not allowing full numerical accuracy, but still demanding convergence,
3. And most importantly, these non-smooth circumstances are what the vast majority of practical applications of computation produce.
Even with the vast availability of computing power today, numerical error persists. The technique of solution verification exists to measure this error. More importantly, the practice checks to see if the application of more computing gives better answers. It makes sure the promise of the equivalence theorem is delivered. This promise requires attention to detail and focus. It is also more technically complex in many cases. The entire premise is still a place for progress to be made. That progress has stagnated over the past couple of decades. The whole thing is also a lot of work and thus expensive. Right now, laziness and cheapness is winning.

Why Is it Avoided?
There is a virtual universal tendency to ignore numerical error in practical calculations. This can be traced back to the same principle in looking at the error in the verification of methods. In the ubiquitous Sod shock tube, the “Hello World” problem for shocks, is rarely subjected to any sort of accuracy or order of convergence testing. This applies to virtually every shock problem used to demonstrate and follow practical calculations. In those practical calculations, this is premised on the underlying characteristic where convergence is actually generally first order (or less). The truth is that the level of error varies a great deal. Often, more expensive high-order methods are less accurate with shocks and quite expensive. All of this is contributing to stagnation in the advancement of practical methods.
The upshot of this is a tendency to ignore numerical error in practical calculations. Thus, we don’t confront the very real problem and avoid the very real opportunity of higher resolution methods having a benefit for methods in general. This contributes to the stagnation in methodology and avoids the uplift in method efficacy and efficiency that will result from improved numerical methods. We see yet another example of systematic avoidance of reality. This then leads to the lack of progress and the failure to improve the state of the world. Even when the answers are lying right in front of us. Of course, if you never do any estimation or convergence testing, you’ll never know whether the calculation will converge at all. Convergence and improvement with more computation are simply assumed as if they were an “iron law”. It is not. All of this allows the systematic avoidance of very real problems in progress that should be happening. The whole issue around the lack of convergence in solution verification is a very ugly and deep topic. For the most part, it is not explored at all in the literature, nor are the consequences appreciated. Yet this lack of convergence is, in a very deep sense, a problem that receives no attention. If it fails, those results are often simply hidden, never discussed, but these results have a much deeper and more insidious problem. The issue most days is that it’s merely inconvenient, but they point towards a notion that the methods and models in the code need to be examined and improved. The lack of improvement renders the supercomputers that are the focus of so much attention, not delivering the benefits they promise.
What are the excuses for this deplorable practice?
- The most common thing is that the analyst doesn’t even think about it. They just use the same resolution they always have or that their buddy used in doing a similar calculation. The excuses only get worse from there.
- The next excuse is that they use as much computing as they can possibly afford. They assume that because it’s as much as they can afford, it’s the best calculation they can get.
- They never check to see whether a coarser resolution would actually provide an adequate solution. Those relatively cheap coarse solutions might produce a sequence of calculations that is well-ordered and convergent.
- To get a step worse, you have the analysts who absolutely know that the calculation will not converge to anything. They mindfully avoid looking at the question because they know the answer is bad. This is far too common and often related to acknowledged shortcomings in the simulation software that nobody looks at, nobody is willing to fix, and simply persists endlessly.
As you go down this hierarchy of repugnant behavior, you see a constancy of an unwillingness to ask deeper questions or demand higher standards from the software. Ultimately, the analysis of meaningful systems suffers. The credibility of the analysis suffers. Progress towards better results suffers. In the long run, humanity suffers from the lack of progress towards better science and engineering. In today’s world, all ofthese excuses hold because they’re highly cost-effective and don’t cost anyone extra money. Asking questions that are hard or finding problems in simulation software is something that nobody wants to pay for, and as a result, all the bad behaviors are essentially chosen out of expediency.
“We can only see a short distance ahead, but we can see plenty there that needs to be done.” ― Alan Turing
The Deeper Issues Underneath
“Failure is constructive feedback that tells you to try a different approach to accomplish what you want.” ― Idowu Koyenikan


A common way for the equations to be inconsistent is ignorance of the mass equation. Remarkably, the mass equation is violated. It is remarkable as conservation of mass is the most fundamental conservation law. When it is violated, all the conservation laws are trashed. This happens often in a couple of cases where the conservation of mass is implicit in the equations. It is just assumed to hold. As such, the equation is not evident, and this underlies the root of a huge mistake.
For example, in a Lagrangian calculation, the mass is conserved, but it is implicit in the position of the mesh nodes. Thu,s there is a transformation between that motion and the conservation of mass. If those positions get scrambled by shear in a flow, then the transformation can become ill-posed. This can be fatal for a calculation. This causes panic in the code user. The simple answer is to delete the misbehavior. It works, but also destroys the consistency of the calculation. Convergence toward the correct solution is also destroyed. The equivalence theorem is systematically violated.
In an incompressible flow, the divergence constraint can be derived either from the mass equation. In other derivations, the pressure equation is used. This is probably the more consistent way to do this. The conservation of mass can be lost if one labels mass for a multi-material flow, such as a method like level sets, where the area is represented. The area or volume then is proportional to the mass, just as in Lagrangian equations. In some cases (like standard level sets), the area-volume is not preserved, and mass is lostor gained (mostly lost). Again, the most fundamental conservation law is not maintained. The equivalence theorem is violated. Convergence is not assured by construction.

A worse and more pernicious way for this to happen is in shock calculations at Sandia, where troublesome material states are deleted. This is done to avoid issues with equations of state as material evolves into extreme conditions. This is done with several codes at Sandia. I had pointed out to management that this leads to an inconsistency in the fundamental governing equations and a violation of the Lax-Equivalence theorem. I had done this nearly 20 years ago and again more recently. The response was “meh, we don’t care”. The technique is really useful for making the code “robust”. This is just like the excuse for deleting elements described next. The calculation runs faster and to completion. Inconsistency physically, isn’t a concern apparently. This means solutions using this approach are likely bullshit.
A common approach in Sandia codes and other solid mechanics code, it is to practice element death. This is where mass is deletedwhen the Lagrangian representation becomes troublesome. This is the inversion of elements or cells due to their position. It almost always happens in shear. Shear is ubiqutious physicallybecause turbulence. This destroys the consistency of the equation, and any sense of convergence under mesh refinement is similarly destroyed. Yet this practice persists and is commonly used for extremely high consequence calculations across a number of important settings, industrial or military related. Again, the lack of convergence is seemingly ignored by practitioners. The behavior of the analysts indicates they know this, but the practice persists.
The reliance on this technique is appalling when there are more suitable approaches that would converge. Most notably, remapping, remeshing, and methods used in arbitrary Lagrangian-Eulerian (ALE) calculations. This is a well-developed and mature technology that is being ignored. Convergence is simply unimportant. It would take care of this problem. I would counter: it’s more expensive to buy a very expensive supercomputer that’s rendered incompetent by the code and methods that are puton it, that have no consistency with the fundamental governing equations. Theseconcerns have fallen on deaf ears as we simply persist in using these methods. These practices and their persistence are among the most vexing and unsupportable things I’ve seen in terms of practice. It isn’t as bad as the lack of ethics, but definitely incompetent.

To get concrete on the negative side effects of all this, one thing is the acceptance of either poor, inaccurate, or even non-convergent numerical methods. In the wake of this, you often get a calibration of a calculation to data that includes the effects of mesh resolution as part of this. So the model used is mesh dependent instead of consistent. To some extent, this is inevitable for most challenging physics. In these cases, this is not a case where the physics is too difficult. This is mindful ignorance and downright lazy. We know how to avoid these problems. We just are not doing the work; it is lazy. Thus, you cut off any improvement in the numerical methods or the code at the knees by simply taking the poor results and encoding it into the model. Simulations relying on these techniques are simply not credible.
Now that we’ve gotten the willful ignorance and incompetence out of the way, we can move on. There are other, more banal reasons for the lack of convergence.

Both deep theoretical questions remain unanswered regarding calculations of things that look and feel like turbulence and may indeed be turbulence. There are also gaps in how we practically model a host of important systems that are not being examined. Our modeling is thus more uncertain than it should be. These issues are not being investigated sufficientlyand progress is not being made because they are not being looked at. Granted, there are some huge theoretical challenges too. The mathematics and numerical methods are not up to the challenge yet. The bigger issue is that the standard practices are not forcing the issue. The obvious fundamental questions are not being asked.
In most practical calculations, the quantities of interest are not the full field, and the convergence in various norms makes little sense. Thus, the numerical analysis is not fully applicable. The metrics are integrated measures like energy released. Worse yet specific quantities and given locations that are measured. This is often guided by the application setting. Another clear example is maximum or minimum conditions, such as temperature. This case is adjacent to the L-infinity norm, which tends to be difficult to achieve convergence in. We know that things like mins and maxes are incredibly poorly behaved, but also extremely important in terms of safety and various thresholds that we do not want materials to reach. All of this requires a much sterner and more committed scientific exercise in trying to produce reliable, credible calculations.
If we don’t ask the basic questions of the calculations, progress certainly won’t happen by magic.
In general, if we have turbulent or turbulent-like phenomena, we can assume that parts of the correct solution vary substantially. This variability depends on things like the initial conditions and the degree of homogeneity of those initial conditions. It is a reasonable belief that initial conditions in a calculation are far more quiescent and homogeneous than reality. The impact of that is not accountable in calculations.
Moreover, a single calculation is just one draw from a realisation. Often, the experiment we are comparing to is a similar single draw. We should have no expectation that we are drawing from the same realization as a calculation. Appropriate variability over a set of initial, boundary, and material compositions would lead to a variable outcome and ultimately a PDF of a given solution. One would then look at solution verification as how this PDF changes as a function of the mesh resolution, independent of all other differences in initial and boundary conditions. For the most part, we are not thinking of simulations like this at all.
The upshot of all of this is a general lack of credibility in computational simulations that is unnecessary today. It results in the vast investments in supercomputing going unrealized in terms of their potential impact in science and engineering.
If we had more reliable mesh conversions done as part of the analysis, the results would be immediate. You would expose problems, define opportunities for improvement, and produce a far better science. All ofthis would serve the benefits of computer simulation far better than today’s lazy practices. We have a lot of potential to make this technology far more accurate and capable of producing extremely great outcomes for society. The problem is that the lazy practices are accepted because they’re cheap. High quality and doing things right isn’t cheap, but in the long run, it produces far higher value, a value that we today are missing.
“Your assumptions are your windows on the world. Scrub them off every once in a while, or the light won’t come in.” ― Alan Alda


The Path Forward
“If you’re going to say what you want to say, you’re going to hear what you don’t want to hear.” ― Roberto Bolaño
The way to make things better is at once simple and complex. A first step is to start doing the fucking work! Simply doing the (required) tests and asking questions is the way forward. Practically speaking, there are a number of things that need to change to do this. We need management support for it. We need funding support for this. Leadership needs to be willing to support negative results and appropriate responses. We need a genuine effort to cast failures as opportunities to learn and grow.
There needs to be trust that the negative results are not evidence of malfesence or incompetence. We need project and program management that allows adjustment in the trajectory of work to the results. Work is not a straight line. We are not building a bridge or repaving a road. We need a commitment to progress and advancing knowledge. All of these things are lacking today. We need a different spirit of work. Above all else we need trust in each other.
“The Four Agreements
1. Be impeccable with your word.
2. Don’t take anything personally.
3. Don’t make assumptions.
4. Always do your best. ” ― don Miguel Ruiz
