
 In the past quarter century the role of software in science has made a huge change in importance. I work in a computer research organization that employs many applied mathematicians. One would think that we have a little maelstrom of mathematical thought. Very little actual mathematics takes place with most of them writing software as their prime activity. A great deal of emphasis is placed on software as something to be preserved or invested in. This dynamic places a great deal of other forms of work on the backburner like mathematics (or modeling or algorithmic-methods investigation). The proper question to think about is whether the emphasis on software along with collateral decreases in focus on mathematics or physical modeling is a benefit to the conduct of science.
In the past quarter century the role of software in science has made a huge change in importance. I work in a computer research organization that employs many applied mathematicians. One would think that we have a little maelstrom of mathematical thought. Very little actual mathematics takes place with most of them writing software as their prime activity. A great deal of emphasis is placed on software as something to be preserved or invested in. This dynamic places a great deal of other forms of work on the backburner like mathematics (or modeling or algorithmic-methods investigation). The proper question to think about is whether the emphasis on software along with collateral decreases in focus on mathematics or physical modeling is a benefit to the conduct of science.
Doing mathematics should always mean finding patterns and crafting beautiful and meaningful explanations.
― Paul Lockhart
I’ll focus on my wife’s favorite question, “what is code?”(I put this up on a slide when she was in the audience, and she rolled her eyes at me and walked out). If we understand what exactly code is we can answer the question of whether it can be preserved and whether it is worthwhile to do.
 The simplest answer to the question at hand is that code is a set of instructions that a computer can understand that provides a recipe provided by humans for conducting some calculations. These instructions could integrate a function, or a differential equations, sort some data out, filter an image, or millions of other things. In every case the instructions are devised by humans to do something, and carried out by a computer with greater automation and speed than humans can possibly manage. Without the guidance of humans, the computer is utterly useless, but with human guidance it is a transformative tool. We see modern society completely reshaped by the computer. Too often the focus of humans is on the tool and not the things that give it power, skillful human instructions devised by creative intellects. Dangerously, science is falling into this trap, and the misunderstanding of the true dynamic may have disastrous consequences for the state of progress. We must keep in mind the nature of computing and man’s key role in its utility.
The simplest answer to the question at hand is that code is a set of instructions that a computer can understand that provides a recipe provided by humans for conducting some calculations. These instructions could integrate a function, or a differential equations, sort some data out, filter an image, or millions of other things. In every case the instructions are devised by humans to do something, and carried out by a computer with greater automation and speed than humans can possibly manage. Without the guidance of humans, the computer is utterly useless, but with human guidance it is a transformative tool. We see modern society completely reshaped by the computer. Too often the focus of humans is on the tool and not the things that give it power, skillful human instructions devised by creative intellects. Dangerously, science is falling into this trap, and the misunderstanding of the true dynamic may have disastrous consequences for the state of progress. We must keep in mind the nature of computing and man’s key role in its utility.
Mathematics is the cheapest science. Unlike physics or chemistry, it does not require any expensive equipment. All one needs for mathematics is a pencil and paper.
― George Pólya
The manner of treating applied mathematics today serves as an instructive lesson in how out of balance the dynamic is today. Among the sciences mathematics may be the most purely thoughtful endeavor. Some have quipped that mathematics is the most cost efficient discipline, requiring nothing more than time, pen and paper. Often massive progress happens without pen and paper whole the mathematical mind ponders and schemes about theorem, proof and conceptual breakthroughs. Increasingly this idealized model is foreign to mathematicians and the desire for a more concrete product has taken hold. This is most keenly seen in the drive for software as a tangible end product.
 Nothing is remotely wrong with creating working software to demonstrate a mathematical concept. Often mathematics is empowered by the tangible demonstration of the utility of the ideas expressed in code. The problem occurs when the code becomes the central activity and mathematics is subdued in priority. Increasingly, the essential aspects of mathematics are absent from the demands of the research being replaced by software. This software is viewed as an investment that must be transferred along to new generations of computers. The issue is that the porting of libraries of mathematical code has become the raison d’etre for research. This porting has swallowed innovation in mathematical ideas whole, and the balance in research is desperately lacking.
Nothing is remotely wrong with creating working software to demonstrate a mathematical concept. Often mathematics is empowered by the tangible demonstration of the utility of the ideas expressed in code. The problem occurs when the code becomes the central activity and mathematics is subdued in priority. Increasingly, the essential aspects of mathematics are absent from the demands of the research being replaced by software. This software is viewed as an investment that must be transferred along to new generations of computers. The issue is that the porting of libraries of mathematical code has become the raison d’etre for research. This porting has swallowed innovation in mathematical ideas whole, and the balance in research is desperately lacking.
Instead of focusing on being mathematicians, we increasingly see software engineering and programming as the focal point for people’s work. Software engineering and maintenance of complex software is a worthy endeavor (more later), but our talented mathematicians should be discovering math, not porting code and finding bugs as their principle professional focus. The discovery of deep, innovative and exciting mathematics promises to provide far more benefit to the future of computing than any software instantiation. New mathematical ideas if focused upon and delivered will ultimately unleash far greater benefits in the long run. This is an obvious thing, yet focus is entirely away from this model. We are steadfastly turning our mathematicians into software engineers.
Let’s get to the crux of the problem with current thinking about software. Mathematical software is like a basic plumbing of lots of codes used for scientific activities, but this model is deeply flawed. It is not like infrastructure at all where the code would be repaired and services after it is built. This leads to the current maintainers of the code to not innovate or extend the intellectual ideas in software, which I would contend is necessary to intellectually own the software. Instead a mathematical body of code is more like an automobile. The auto must be fueled and services, but over time becomes old and outdated needing to be replaced. The classic car has a certain luster and beauty, but its efficiency and utility is far less than a new car. Any automobile can take you places, but eventually the old car cannot compete with the new car. This is how we should think about our mathematical software. It should be serviced and maintained by software professionals, but mathematicians should be working on a new model all the time.
For so much of what we do with computers mathematics forms the core and foundation of the capability. The lack of focus on the actual execution of mathematical research will have long lasting effects on our future. In essence we are living on the mathematical (and physics, engineering, …) research of the past without reinvesting in the next generation of breakthroughs. We are emptying the pipeline of discovery and  impoverishing our future. In addition we are failing to take advantage of the skills, talents and imagination of the current generation of scientists. We are creating a deficit of possibility that will harm our future in ways we can scarcely imagine. The guilt lies in the failure of our leaders to have sufficient faith in the power of human thought and innovation to continue to march forward into the future in the manner we have in the
impoverishing our future. In addition we are failing to take advantage of the skills, talents and imagination of the current generation of scientists. We are creating a deficit of possibility that will harm our future in ways we can scarcely imagine. The guilt lies in the failure of our leaders to have sufficient faith in the power of human thought and innovation to continue to march forward into the future in the manner we have in the
past. People if turned loose on challenging problems will solve them; we always have and past is prolog.
Progress is possible only if we train ourselves to think about programs without thinking of them as pieces of executable code.
― Edsger W. Dijkstra
The key to this notion is putting software in its proper place. Just as a computer itself, software is a tool. Software is an expression of intellect plain and simple. If the intellectual capital isn’t present the value of the software is diminished. Intellectual ownership is a big deal and the key to real value. Increasingly we are creating software where no one working on really owns the knowledge encoded. This is a massively dangerous trend. Unfortunately we are not funding the basic process where the ownership is obtained. Full ownership is established through the creative process, the ability to innovate and create new knowledge grants ownership. Without the creation of new knowledge the intellectual ownership is incomplete. An additional benefit of the ownership is new capability for mankind. The foundation of all of this is mathematical research.
Our foundation is crumbling beneath our feet from abject neglect. Again, like everything else today, the reason for this is a focus on money as the arbitrator of all that is good or bad. We simply do what we are paid to do, no more and no less. No one is paying for math, they are paying for software, it’s as simple as that.
Programs must be written for people to read, and only incidentally for machines to execute.
― Harold Abelson

 which can be a wonderful characteristic, but I know what Los Alamos used to mean, and it causes me a great deal of personal pain to see the magnitude of the decline and damage we have done to it. The changes at Los Alamos have been done in the name of compliance, to bring an unruly institution to heel and conform to imposed mediocrity.
which can be a wonderful characteristic, but I know what Los Alamos used to mean, and it causes me a great deal of personal pain to see the magnitude of the decline and damage we have done to it. The changes at Los Alamos have been done in the name of compliance, to bring an unruly institution to heel and conform to imposed mediocrity. culture that Karen and I so greatly benefited from. Organizational culture is a deep well to draw from. It shapes so much of what we see from different institutions. At Los Alamos it has formed the underlying resistance to the imposition of the modern compliance culture. On the other hand, my current institution is tailor made to complete compliance, even subservience to the demands of our masters. When those masters have no interest in progress, quality, or productivity, the result in unremitting mediocrity. This is the core of the discussion, our master’s prime directive is compliance, which bluntly and specifically means “don’t ever fuck up!” In this context Los Alamos is the king of the fuck-ups, and others simply keep places nose clean thus succeeding in the eyes of the masters..
culture that Karen and I so greatly benefited from. Organizational culture is a deep well to draw from. It shapes so much of what we see from different institutions. At Los Alamos it has formed the underlying resistance to the imposition of the modern compliance culture. On the other hand, my current institution is tailor made to complete compliance, even subservience to the demands of our masters. When those masters have no interest in progress, quality, or productivity, the result in unremitting mediocrity. This is the core of the discussion, our master’s prime directive is compliance, which bluntly and specifically means “don’t ever fuck up!” In this context Los Alamos is the king of the fuck-ups, and others simply keep places nose clean thus succeeding in the eyes of the masters.. productivity is never a priority in the modern world. This is especially true once the institutions realized that they could bullshit their way through accomplishment without risking the core value of compliance. Thus doing anything real and difficult is detrimental because you can more easily BS your way to excellence and not run the risk of violating the demands of compliance. In large part compliance assures the most precious commodity in the modern research institution, funding. Lack of compliance is punished by lack of funding. Our chains are created out of money.
productivity is never a priority in the modern world. This is especially true once the institutions realized that they could bullshit their way through accomplishment without risking the core value of compliance. Thus doing anything real and difficult is detrimental because you can more easily BS your way to excellence and not run the risk of violating the demands of compliance. In large part compliance assures the most precious commodity in the modern research institution, funding. Lack of compliance is punished by lack of funding. Our chains are created out of money. A large part of the compliance is lack of resistance to intellectually poor programs. There was once a time when the Labs helped craft the programs that fund them. With each passing year this dynamic breaks down, and the intellectual core of crafting well-defined programs to accomplish important National goals wanes. Why engage in the hard work of providing feedback when it threatens the flow of money? Increasingly the only sign of success is the aggregate dollar figure flowing into a given institution or organization. Any actual quality or accomplishment is merely coincidental. Why focus on excellence or quality when it is so much easier to simply generate a press release that looks good.
A large part of the compliance is lack of resistance to intellectually poor programs. There was once a time when the Labs helped craft the programs that fund them. With each passing year this dynamic breaks down, and the intellectual core of crafting well-defined programs to accomplish important National goals wanes. Why engage in the hard work of providing feedback when it threatens the flow of money? Increasingly the only sign of success is the aggregate dollar figure flowing into a given institution or organization. Any actual quality or accomplishment is merely coincidental. Why focus on excellence or quality when it is so much easier to simply generate a press release that looks good. bad things ever happening. In the end the only way to do this is stop all progress and make sure no one ever accomplishes anything substantial.
bad things ever happening. In the end the only way to do this is stop all progress and make sure no one ever accomplishes anything substantial. Over the past few decades there has been a lot of sturm and drang around the prospect that computation changed science in some fundamental way. The proposition was that computation formed a new way of conducting scientific work to compliment theory, experiment/observation. In essence computation had become the third way for science. I don’t think this proposition stands the test of time and should be rejected. A more proper way to view computation is as a new tool that aids scientists. Traditional computational science is primarily a means of investigating theoretical models of the universe in ways that classical mathematics could not. Today this role is expanding to include augmentation of data acquisition, analysis, and exploration well beyond the capabilities of unaided humans. Computers make for better science, but recognizing that it does change science at all is important to make good decisions.
Over the past few decades there has been a lot of sturm and drang around the prospect that computation changed science in some fundamental way. The proposition was that computation formed a new way of conducting scientific work to compliment theory, experiment/observation. In essence computation had become the third way for science. I don’t think this proposition stands the test of time and should be rejected. A more proper way to view computation is as a new tool that aids scientists. Traditional computational science is primarily a means of investigating theoretical models of the universe in ways that classical mathematics could not. Today this role is expanding to include augmentation of data acquisition, analysis, and exploration well beyond the capabilities of unaided humans. Computers make for better science, but recognizing that it does change science at all is important to make good decisions. The key to my rejection of the premise that computation is a close examination of what science is. Science is a systematic endeavor to understand and organize knowledge of the universe in a testable framework. Standard computation is conducted in a systematic manner to conduct studies of the solution to theoretical equations, but the solutions always depend entirely on the theory. Computation also provides more general ways of testing theory and making predictions well beyond the approaches available prior to computation. Computation frees us of limitations for solving the equations comprising the theory, but nothing about the fundamental dynamic in play. The key point is that utilizing computation is as an enhanced tool set to conduct science in an otherwise standard way.
The key to my rejection of the premise that computation is a close examination of what science is. Science is a systematic endeavor to understand and organize knowledge of the universe in a testable framework. Standard computation is conducted in a systematic manner to conduct studies of the solution to theoretical equations, but the solutions always depend entirely on the theory. Computation also provides more general ways of testing theory and making predictions well beyond the approaches available prior to computation. Computation frees us of limitations for solving the equations comprising the theory, but nothing about the fundamental dynamic in play. The key point is that utilizing computation is as an enhanced tool set to conduct science in an otherwise standard way.



 Observations still require human ingenuity and innovation to be achieved. This can take the form of the mere inspiration of measuring or observing a certain factor in the World. Another form is the development of measurement devices that allow measurements. Here is a place where computation is playing a greater and greater role. In many cases computation allows the management of mountains of data that are unthinkably large by former standards. Another way of changing data that is either complementary or completely different is analysis. New methods are available to enhance diagnostics or see effects that were previously hidden or invisible. In essence the ability to drag signal from noise and make the unseeable, clear and crisp. All of these uses are profoundly important to science, but it is science that still operates as it did before. We just have better tools to apply to its conduct.
Observations still require human ingenuity and innovation to be achieved. This can take the form of the mere inspiration of measuring or observing a certain factor in the World. Another form is the development of measurement devices that allow measurements. Here is a place where computation is playing a greater and greater role. In many cases computation allows the management of mountains of data that are unthinkably large by former standards. Another way of changing data that is either complementary or completely different is analysis. New methods are available to enhance diagnostics or see effects that were previously hidden or invisible. In essence the ability to drag signal from noise and make the unseeable, clear and crisp. All of these uses are profoundly important to science, but it is science that still operates as it did before. We just have better tools to apply to its conduct. One of the big ways for computation to reflect the proper structure of science is verification and validation (V&V). In a nutshell V&V is the classical scientific method applied to computational modeling and simulation in a structured, disciplined manner. The high performance computing programs being rolled out today ignore verification and validation almost entirely. Science is supposed to arrive via computation as if by magic. If it is present it is an afterthought. The deeper and more pernicious danger is the belief by many that modeling and simulation can produce data of equal (or even greater) validity than nature itself. This is not a recipe for progress, but rather a recipe for disaster. We are priming ourselves for believing some rather dangerous fictions.
One of the big ways for computation to reflect the proper structure of science is verification and validation (V&V). In a nutshell V&V is the classical scientific method applied to computational modeling and simulation in a structured, disciplined manner. The high performance computing programs being rolled out today ignore verification and validation almost entirely. Science is supposed to arrive via computation as if by magic. If it is present it is an afterthought. The deeper and more pernicious danger is the belief by many that modeling and simulation can produce data of equal (or even greater) validity than nature itself. This is not a recipe for progress, but rather a recipe for disaster. We are priming ourselves for believing some rather dangerous fictions.
 The deepest issue with current programs pushing forward on the computing hardware is their balance. The practice of scientific computing requires the interaction and application of great swathes of scientific disciplines. Computing hardware is a small component in the overall scientific enterprise and among the aspect least responsible for the success. The single greatest element in the success of scientific computing is the nature of the models being solved. Nothing else we can focus on has anywhere close to this impact. To put this differently, if a model is incorrect no amount of computer speed, mesh resolution or numerical accuracy can rescue the solution. This is the statement of how scientific theory applies to computation. Even if the model is unyieldingly correct, then the method and approach to solving the model is the next largest aspect in terms of impact. The damning thing about exascale computing is the utter lack of emphasis on either of these activities. Moreover without the application of V&V in a structured, rigorous and systematic manner, these shortcomings will remain unexposed.
The deepest issue with current programs pushing forward on the computing hardware is their balance. The practice of scientific computing requires the interaction and application of great swathes of scientific disciplines. Computing hardware is a small component in the overall scientific enterprise and among the aspect least responsible for the success. The single greatest element in the success of scientific computing is the nature of the models being solved. Nothing else we can focus on has anywhere close to this impact. To put this differently, if a model is incorrect no amount of computer speed, mesh resolution or numerical accuracy can rescue the solution. This is the statement of how scientific theory applies to computation. Even if the model is unyieldingly correct, then the method and approach to solving the model is the next largest aspect in terms of impact. The damning thing about exascale computing is the utter lack of emphasis on either of these activities. Moreover without the application of V&V in a structured, rigorous and systematic manner, these shortcomings will remain unexposed. In summary, we are left to draw a couple of big conclusions: computation is not a new way to do science, but rather an enabling tool for doing standard science better. If we want to get the most out of computing requires a deep and balanced portfolio of scientific activities. The current drive for performance with computing hardware ignores the most important aspects of the portfolio, if science is indeed the objective. If we want to get the most science out of computation, a vigorous V&V program is one way to inject the scientific method into the work. V&V is the scientific method and gaps in V&V reflect gaps in scientific credibility. Simply recognizing how scientific progress occurs and following that recipe can achieve a similar effect. The lack of scientific vitality in current computing programs is utterly damning.
In summary, we are left to draw a couple of big conclusions: computation is not a new way to do science, but rather an enabling tool for doing standard science better. If we want to get the most out of computing requires a deep and balanced portfolio of scientific activities. The current drive for performance with computing hardware ignores the most important aspects of the portfolio, if science is indeed the objective. If we want to get the most science out of computation, a vigorous V&V program is one way to inject the scientific method into the work. V&V is the scientific method and gaps in V&V reflect gaps in scientific credibility. Simply recognizing how scientific progress occurs and following that recipe can achieve a similar effect. The lack of scientific vitality in current computing programs is utterly damning. My wife has a very distinct preference in late night TV shows. First, the show cannot be on late night TV, she is fast asleep by 9:30 most nights. Secondly, she is quite loyal. More than twenty years ago she was essentially forced to watch late night TV while breastfeeding our newborn daughter. Conan O’Brien kept her laughing and smiling through many late night feedings. He isn’t the best late night host, but he is almost certainly the silliest. His shtick is simply stupid with a certain sophisticated spin. One of the dumb bits on his current show is “Why China is kicking
My wife has a very distinct preference in late night TV shows. First, the show cannot be on late night TV, she is fast asleep by 9:30 most nights. Secondly, she is quite loyal. More than twenty years ago she was essentially forced to watch late night TV while breastfeeding our newborn daughter. Conan O’Brien kept her laughing and smiling through many late night feedings. He isn’t the best late night host, but he is almost certainly the silliest. His shtick is simply stupid with a certain sophisticated spin. One of the dumb bits on his current show is “Why China is kicking our ass”. It features Americans doing all sorts of thoughtless and idiotic things on video with the premise being that our stupidity is the root of any loss of American hegemony. As sad as this might inherently be, the principle is rather broadly applicable and generally right on the money. The loss of preeminence nationally is more due to shear hubris; manifest overconfidence and sprawling incompetence on the part of Americans than anything being done by our competitors.
our ass”. It features Americans doing all sorts of thoughtless and idiotic things on video with the premise being that our stupidity is the root of any loss of American hegemony. As sad as this might inherently be, the principle is rather broadly applicable and generally right on the money. The loss of preeminence nationally is more due to shear hubris; manifest overconfidence and sprawling incompetence on the part of Americans than anything being done by our competitors. High performance computing is no different. By our chosen set of metrics, we are losing to the Chinese rather badly through a series of self-inflicted wounds instead of superior Chinese execution. Nonetheless, we are basically handing the crown of international achievement to them because we have become so incredibly incompetent at intellectual endeavors. Today, I’m going to unveil how we have thoughtlessly and idiotically run our high performance computing programs in a manner that undermines our success. My key point is that stopping the self-inflicted damage is the first step toward success. One must take careful note that the measure of superiority is based on a benchmark that has no practical value. Having metric of success with no practical value is a large part of the underlying problem.
High performance computing is no different. By our chosen set of metrics, we are losing to the Chinese rather badly through a series of self-inflicted wounds instead of superior Chinese execution. Nonetheless, we are basically handing the crown of international achievement to them because we have become so incredibly incompetent at intellectual endeavors. Today, I’m going to unveil how we have thoughtlessly and idiotically run our high performance computing programs in a manner that undermines our success. My key point is that stopping the self-inflicted damage is the first step toward success. One must take careful note that the measure of superiority is based on a benchmark that has no practical value. Having metric of success with no practical value is a large part of the underlying problem.
 Scientific computing has been a thing for about 70 years being born during World War 2. During that history there has been a constant push and pull of capability of computers, software, models, mathematics, engineering, method and physics. Experimental work has been essential to keep computations tethered to reality. An advance in one area would spur the advances in another in a flywheel of progress. A faster computer would make new problems previously seeming impossible to solve suddenly tractable. Mathematical rigor may suddenly give people faith in a method that previously seemed ad hoc and unreliable. Physics might ask new questions counter to previous knowledge, or experiments would confirm or invalidate model applicability. The ability to express ideas in software allows algorithms and models to be used that may have been too complex with older software systems. Innovative engineering provides new applications for computing that extend the scope and reach of computing to new areas of societal impact. Every single one of these elements is subdued in the present approach to HPC, and robs the ecosystem of vitality and power. We have learned these lessons in the recent past, yet swiftly forgotten them when composing this new program.
Scientific computing has been a thing for about 70 years being born during World War 2. During that history there has been a constant push and pull of capability of computers, software, models, mathematics, engineering, method and physics. Experimental work has been essential to keep computations tethered to reality. An advance in one area would spur the advances in another in a flywheel of progress. A faster computer would make new problems previously seeming impossible to solve suddenly tractable. Mathematical rigor may suddenly give people faith in a method that previously seemed ad hoc and unreliable. Physics might ask new questions counter to previous knowledge, or experiments would confirm or invalidate model applicability. The ability to express ideas in software allows algorithms and models to be used that may have been too complex with older software systems. Innovative engineering provides new applications for computing that extend the scope and reach of computing to new areas of societal impact. Every single one of these elements is subdued in the present approach to HPC, and robs the ecosystem of vitality and power. We have learned these lessons in the recent past, yet swiftly forgotten them when composing this new program. under siege. The assault on scientific competence is broad-based and pervasive as expertise is viewed with suspicion rather than respect. Part of this problem is the lack of intellectual stewardship reflected in numerous empty thoughtless programs. The second piece is the way we are managing science. A couple of easy things engrained into the way we do things that lead to systematic underachievement is inappropriately applied project planning and intrusive micromanagement into the scientific process. The issue isn’t management per se, but its utterly inappropriate application and priorities that are orthogonal to technical achievement.
under siege. The assault on scientific competence is broad-based and pervasive as expertise is viewed with suspicion rather than respect. Part of this problem is the lack of intellectual stewardship reflected in numerous empty thoughtless programs. The second piece is the way we are managing science. A couple of easy things engrained into the way we do things that lead to systematic underachievement is inappropriately applied project planning and intrusive micromanagement into the scientific process. The issue isn’t management per se, but its utterly inappropriate application and priorities that are orthogonal to technical achievement. ve no big long-term goals as a nation beyond simple survival. Its like we have forgotten to dream big and produce any sort of inspirational societal goals. Instead we create big soulless programs in the place of big goals. Exascale computing is perfect example. It is a goal without a real connection to anything societally important and is crafted solely for the purpose of getting money. It is absolutely vacuous and anti-intellectual at its core by viewing supercomputing as a hardware-centered enterprise. Then it is being managed like everything else with relentless short-term focus and failure avoidance. Unfortunately, even if it succeeds, we will continue our tumble into mediocrity.
ve no big long-term goals as a nation beyond simple survival. Its like we have forgotten to dream big and produce any sort of inspirational societal goals. Instead we create big soulless programs in the place of big goals. Exascale computing is perfect example. It is a goal without a real connection to anything societally important and is crafted solely for the purpose of getting money. It is absolutely vacuous and anti-intellectual at its core by viewing supercomputing as a hardware-centered enterprise. Then it is being managed like everything else with relentless short-term focus and failure avoidance. Unfortunately, even if it succeeds, we will continue our tumble into mediocrity. ne of the cornerstones of the program. SBSS provided a backstop against financial catastrophe at the Labs and provided long-term funding stability. This HPC element in SBSS was the ASCI program (which became the ASC program as it matured). The original ASCI program was relentlessly hardware focused with lots of computer science, along with activities to port older modeling and simulation codes to the new computers. This should seem very familiar to anyone looking at the new ECP program. The ASCI program is the model for the current exascale program. Within a few years it became clear that ASCI’s emphasis on hardware and computer science was inadequate to provide modeling and simulation support for SBSS with sufficient confidence. Important scientific elements were added to ASCI including algorithm and method development, verification and validation, and physics model development as well as stronger ties to experimental programs. These additions were absolutely essential for success of the program. That being said, these elements are all subcritical in terms of support, but they are much better than nothing.
ne of the cornerstones of the program. SBSS provided a backstop against financial catastrophe at the Labs and provided long-term funding stability. This HPC element in SBSS was the ASCI program (which became the ASC program as it matured). The original ASCI program was relentlessly hardware focused with lots of computer science, along with activities to port older modeling and simulation codes to the new computers. This should seem very familiar to anyone looking at the new ECP program. The ASCI program is the model for the current exascale program. Within a few years it became clear that ASCI’s emphasis on hardware and computer science was inadequate to provide modeling and simulation support for SBSS with sufficient confidence. Important scientific elements were added to ASCI including algorithm and method development, verification and validation, and physics model development as well as stronger ties to experimental programs. These additions were absolutely essential for success of the program. That being said, these elements are all subcritical in terms of support, but they are much better than nothing. f one looks at the ECP program the composition and emphasis looks just like the original ASCI program without the changes made shortly into its life. It is clear that the lessons learned by ASCI were ignored or forgotten by the new ECP program. It’s a reasonable conclusion that the main lesson taken from ASC program was how to get money by focusing on hardware. Two issues dominate the analysis of this connection:
f one looks at the ECP program the composition and emphasis looks just like the original ASCI program without the changes made shortly into its life. It is clear that the lessons learned by ASCI were ignored or forgotten by the new ECP program. It’s a reasonable conclusion that the main lesson taken from ASC program was how to get money by focusing on hardware. Two issues dominate the analysis of this connection: Taken in sufficient isolation the objectives of the exascale program are laudable. An exascale computer is useful if it can be reasonably used. The issue is that such a computer does not live in isolation; it exists in a complex trade space where other options exist. My premise has never been that better or faster computer hardware is inherently bad. My premise is that the opportunity cost associated with such hardware is too high. The focus on the hardware is starving other activities essential for modeling and simulation success. The goal of producing an exascale computer is not an objective of opportunity, but rather a goal that we should actively divest ourselves of. Gains in supercomputing are overly expensive and work to hamper progress in related areas simply by the implicit tax produced by how difficult the new computers are to use. Improvements in real modeling and simulation capability would be far greater if we invested our efforts in different aspects of the ecosystem.
Taken in sufficient isolation the objectives of the exascale program are laudable. An exascale computer is useful if it can be reasonably used. The issue is that such a computer does not live in isolation; it exists in a complex trade space where other options exist. My premise has never been that better or faster computer hardware is inherently bad. My premise is that the opportunity cost associated with such hardware is too high. The focus on the hardware is starving other activities essential for modeling and simulation success. The goal of producing an exascale computer is not an objective of opportunity, but rather a goal that we should actively divest ourselves of. Gains in supercomputing are overly expensive and work to hamper progress in related areas simply by the implicit tax produced by how difficult the new computers are to use. Improvements in real modeling and simulation capability would be far greater if we invested our efforts in different aspects of the ecosystem.
 ng. Simplicity and stripping away the complexities of reality were the order of the day. Today we are freed to a very large extent from the confines of analytical study by the capacity to approximate solutions to equations. We are free to study the universe as it actually is, and produce a deep study of reality. The analytical methods and ideas still have utility for gaining confidence in these numerical methods, but their lack of grasp on describing reality should be realized. Our ability to study the reality should be celebrated and be the center of our focus. Our seeming devotion to the ideal simply distracts us and draws attention from understanding the real World.
ng. Simplicity and stripping away the complexities of reality were the order of the day. Today we are freed to a very large extent from the confines of analytical study by the capacity to approximate solutions to equations. We are free to study the universe as it actually is, and produce a deep study of reality. The analytical methods and ideas still have utility for gaining confidence in these numerical methods, but their lack of grasp on describing reality should be realized. Our ability to study the reality should be celebrated and be the center of our focus. Our seeming devotion to the ideal simply distracts us and draws attention from understanding the real World. solutions. The ideal equations are supposed to represent the perfect, and in a sense the “hand of God” working in the cosmos. As such they represent the antithesis of moderni
solutions. The ideal equations are supposed to represent the perfect, and in a sense the “hand of God” working in the cosmos. As such they represent the antithesis of moderni Not only are these equations suspect for philosophical reasons, they are suspect for the imposed simplicity of the time they are taken from. In many respects the ideal equations miss most of fruits of the last Century of scientific progress. We have faithfully extended our grasp of reality to include more and more “dirty” features of the actual physical World. To a very great extent the continued ties to the ideal contribute to the lack of progress in some very important endeavors. Perhaps no case more amply demonstrates this handicapping of progress as well as turbulence. Our continued insistence that turbulence is tied to the ideal nature of incompressibility is becoming patently ridiculous. It highlights that important aspects of the ideal are synonymous with the unphysical.
Not only are these equations suspect for philosophical reasons, they are suspect for the imposed simplicity of the time they are taken from. In many respects the ideal equations miss most of fruits of the last Century of scientific progress. We have faithfully extended our grasp of reality to include more and more “dirty” features of the actual physical World. To a very great extent the continued ties to the ideal contribute to the lack of progress in some very important endeavors. Perhaps no case more amply demonstrates this handicapping of progress as well as turbulence. Our continued insistence that turbulence is tied to the ideal nature of incompressibility is becoming patently ridiculous. It highlights that important aspects of the ideal are synonymous with the unphysical. ). Real and nontrivial flow fields are only approximately incompressible. It is important to recognize that approximate and exactly incompressible are very different at their core. Exactly incompressible flows are fundamentally unphysical and unrealizable in the real world. Put differently, they are absolutely pathological.
). Real and nontrivial flow fields are only approximately incompressible. It is important to recognize that approximate and exactly incompressible are very different at their core. Exactly incompressible flows are fundamentally unphysical and unrealizable in the real world. Put differently, they are absolutely pathological.
 explosion like type II supernovas. The classic picture was a static spherical star that burned elements in a series of concentric spheres or increasing mass as one got deeper into the star. Eventually the whole process becomes unstable as the nuclear reactions shift from exothermic to endothermic when iron is created. We observe explosions in such stars, but the idealized stars would not explode. Even if we forced the explosion, the evolution of the post-explosion could not match important observational evidence that implied deep mixing of heavy elements into the expanding envelope of the star.
explosion like type II supernovas. The classic picture was a static spherical star that burned elements in a series of concentric spheres or increasing mass as one got deeper into the star. Eventually the whole process becomes unstable as the nuclear reactions shift from exothermic to endothermic when iron is created. We observe explosions in such stars, but the idealized stars would not explode. Even if we forced the explosion, the evolution of the post-explosion could not match important observational evidence that implied deep mixing of heavy elements into the expanding envelope of the star. evolution as the gold standard is quite strong. Another great example of this is the concept of kinetic energy conservation. Many flows and numerical methods are designed to exactly conserve kinetic energy. This only occurs in the most ideal of circumstances when flows have no natural dissipation (itself deeply unphysical) while retaining well-resolved smooth structure. So the properties are only seen in flows that are unphysical. Many believe that such flows should be exactly preserved as the foundation for numerical methods. This belief is somehow impervious to the observation that such flows are utterly unphysical and could never be observed in reality. It is difficult to square this belief system with the desire to model anything practical.
evolution as the gold standard is quite strong. Another great example of this is the concept of kinetic energy conservation. Many flows and numerical methods are designed to exactly conserve kinetic energy. This only occurs in the most ideal of circumstances when flows have no natural dissipation (itself deeply unphysical) while retaining well-resolved smooth structure. So the properties are only seen in flows that are unphysical. Many believe that such flows should be exactly preserved as the foundation for numerical methods. This belief is somehow impervious to the observation that such flows are utterly unphysical and could never be observed in reality. It is difficult to square this belief system with the desire to model anything practical. A great example of this dichotomy is turbulent fluid mechanics and it’s modeling. It is instructive to explore the issues surrounding the origin of the models with connections to purely numerical approaches. There is the classical thinking about modeling turbulence that basically comes down to solving the ideal equations as perfectly as possible, and modeling the entirety of turbulence with additional models added to the ideal equations. It is the standard approach and by comparison to many other areas of numerical simulation, a relative failure. Nonetheless this approach is followed with almost a religious fervor. I might surmise that the lack of progress in understanding turbulence is somewhat related to the combination of adherence to a faulty basic model (incompressibility) and the solution approach that supposes that all the non-ideal physics can be modeled explicitly.
A great example of this dichotomy is turbulent fluid mechanics and it’s modeling. It is instructive to explore the issues surrounding the origin of the models with connections to purely numerical approaches. There is the classical thinking about modeling turbulence that basically comes down to solving the ideal equations as perfectly as possible, and modeling the entirety of turbulence with additional models added to the ideal equations. It is the standard approach and by comparison to many other areas of numerical simulation, a relative failure. Nonetheless this approach is followed with almost a religious fervor. I might surmise that the lack of progress in understanding turbulence is somewhat related to the combination of adherence to a faulty basic model (incompressibility) and the solution approach that supposes that all the non-ideal physics can be modeled explicitly. It is instructive in closing to peer more keenly at the whole turbulence modeling problem. A simple, but very successful model for turbulence is the Smagorinsky model originally devised for climate and weather modeling, but forming the foundation for the practice of large eddy simulation (LES). What is under appreciated about the Smagorinsky model is its origins. This model was originally created as a way of stabilizing shock calculations by Robert Richtmyer and applied to an ideal differencing method devised by John Von Neumann. The ideal equation solution without Richtmyer’s viscosity was unstable and effectively useless. With the numerically stabilizing term added to the solution, the method was incredibly powerful and forms the basis of shock capturing. The same term was then added to weather modeling to stabilize those equations. It did just that and remarkably it suddenly transformed into a “model” for turbulence. In the process we lost the role it played for numerical stability, but also the strong and undeniable connection between the entropy generated by a shock and observed turbulence behavior. This connection was then systematically ignored because the unphysical incompressible equations we assume turbulence is governed by do not admit shocks. In this lack perspective we find the recipe for lack of progress. It is too powerful for a connection not to be present. Such connections creates issues that undermine some core convictions in the basic understanding of turbulence that seem too tightly held to allow the lack of progress to question.
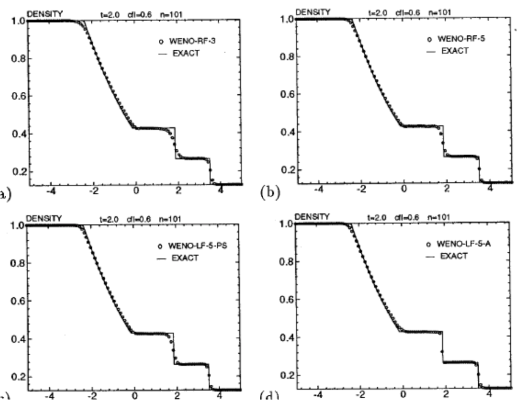
It is instructive in closing to peer more keenly at the whole turbulence modeling problem. A simple, but very successful model for turbulence is the Smagorinsky model originally devised for climate and weather modeling, but forming the foundation for the practice of large eddy simulation (LES). What is under appreciated about the Smagorinsky model is its origins. This model was originally created as a way of stabilizing shock calculations by Robert Richtmyer and applied to an ideal differencing method devised by John Von Neumann. The ideal equation solution without Richtmyer’s viscosity was unstable and effectively useless. With the numerically stabilizing term added to the solution, the method was incredibly powerful and forms the basis of shock capturing. The same term was then added to weather modeling to stabilize those equations. It did just that and remarkably it suddenly transformed into a “model” for turbulence. In the process we lost the role it played for numerical stability, but also the strong and undeniable connection between the entropy generated by a shock and observed turbulence behavior. This connection was then systematically ignored because the unphysical incompressible equations we assume turbulence is governed by do not admit shocks. In this lack perspective we find the recipe for lack of progress. It is too powerful for a connection not to be present. Such connections creates issues that undermine some core convictions in the basic understanding of turbulence that seem too tightly held to allow the lack of progress to question. In area of endeavor standards of excellence are important. Numerical methods are no different. Every area of study has a standard set of test problems that researchers can demonstrate and study their work on. These test problems end up being used not just to communicate work, but also test whether work has been reproduced successfully or compare methods. Where the standards are sharp and refined the testing of methods has a degree of precision and results in actionable consequences. Where the standards are weak, expert judgment reigns and progress is stymied. In shock physics, the Sod shock tube (Sod 1978) is such a standard test. The problem is effectively a “hello World” problem for the field, but suffers from weak standards of acceptance focused on expert opinion of what is good and bad without any unbiased quantitative standard being applied. Ultimately, this weakness in accepted standards contributes to stagnant progress we are witnessing in the field. It also allows a rather misguided focus and assessment of capability to persist unperturbed by results (standards and metrics can energize progress,
In area of endeavor standards of excellence are important. Numerical methods are no different. Every area of study has a standard set of test problems that researchers can demonstrate and study their work on. These test problems end up being used not just to communicate work, but also test whether work has been reproduced successfully or compare methods. Where the standards are sharp and refined the testing of methods has a degree of precision and results in actionable consequences. Where the standards are weak, expert judgment reigns and progress is stymied. In shock physics, the Sod shock tube (Sod 1978) is such a standard test. The problem is effectively a “hello World” problem for the field, but suffers from weak standards of acceptance focused on expert opinion of what is good and bad without any unbiased quantitative standard being applied. Ultimately, this weakness in accepted standards contributes to stagnant progress we are witnessing in the field. It also allows a rather misguided focus and assessment of capability to persist unperturbed by results (standards and metrics can energize progress, 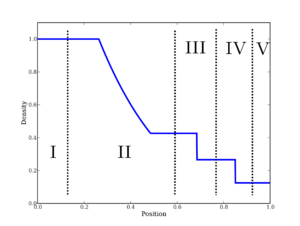 Specifically, Sod’s shock tube (
Specifically, Sod’s shock tube (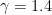 ,
, ![x\in \left[0,1\right]](https://s0.wp.com/latex.php?latex=x%5Cin+%5Cleft%5B0%2C1%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) , the domain is divided into two equal regions; on
, the domain is divided into two equal regions; on ![x\in \left[0,0.5\right]](https://s0.wp.com/latex.php?latex=x%5Cin+%5Cleft%5B0%2C0.5%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) ,
,  ; on
; on ![x\in \left[0.5,1\right]](https://s0.wp.com/latex.php?latex=x%5Cin+%5Cleft%5B0.5%2C1%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) ,
,  . The flow is described by the compressible Euler equations (conservation of mass,
. The flow is described by the compressible Euler equations (conservation of mass,  , momentum
, momentum  and energy
and energy ![\left[\rho \left(e + \frac{1}{2} u^2 \right) \right]_t + \left[rho u \left(e + \frac{1}{2}u^2 \right) + p u\right]_x = 0](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Crho+%5Cleft%28e+%2B+%5Cfrac%7B1%7D%7B2%7D+u%5E2+%5Cright%29+%5Cright%5D_t+%2B+%5Cleft%5Brho+u+%5Cleft%28e+%2B+%5Cfrac%7B1%7D%7B2%7Du%5E2+%5Cright%29+%2B+p+u%5Cright%5D_x+%3D+0&bg=ffffff&fg=000&s=0&c=20201002) ), and an equation of state,
), and an equation of state,  . At time zero the flow develops a self-similar structure with a right moving shock followed by a contact discontinuity, and a left moving rarefaction (expansion fan). This is the classical Riemann problem. The solution may be found through semi-analytical means solving a nonlinear equation defined by the Rankine-Hugoniot relations (see Gottlieb and Groth for a wonderful exposition on this solution via Newton’s method).
. At time zero the flow develops a self-similar structure with a right moving shock followed by a contact discontinuity, and a left moving rarefaction (expansion fan). This is the classical Riemann problem. The solution may be found through semi-analytical means solving a nonlinear equation defined by the Rankine-Hugoniot relations (see Gottlieb and Groth for a wonderful exposition on this solution via Newton’s method).

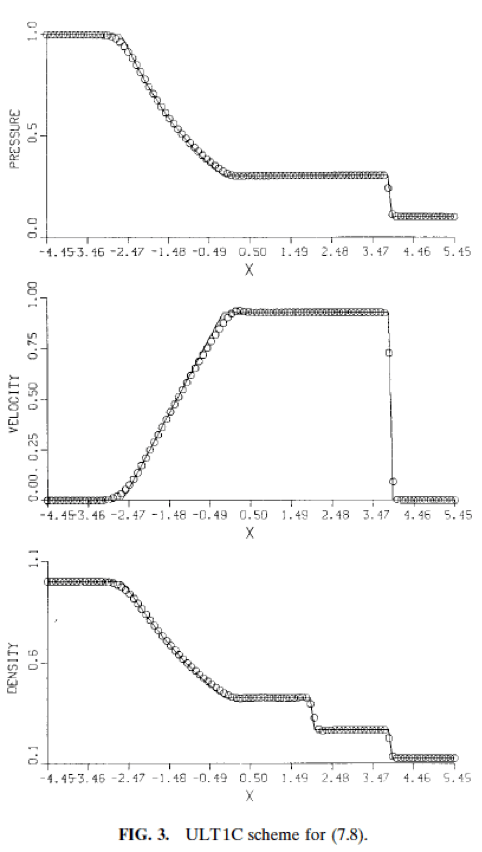
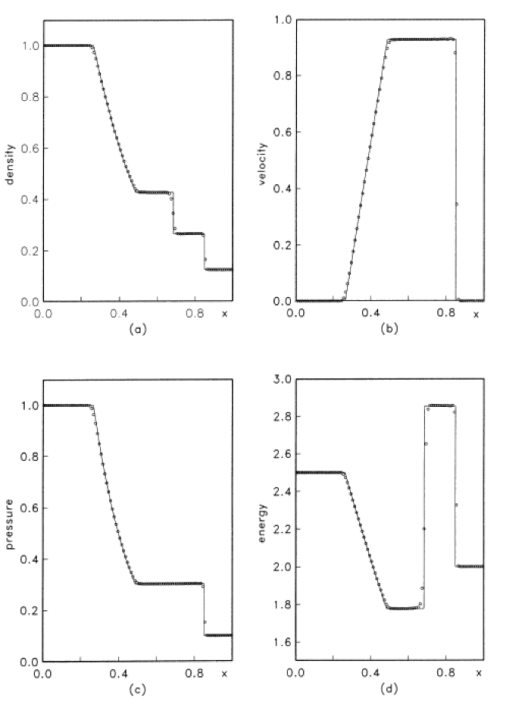
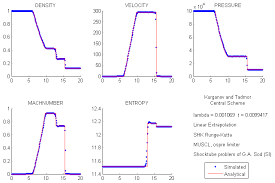 For all these reasons the current standard and practice with shock capturing methods are doing a great disservice to the community. The current practice inhibits progress by hiding deep issues and failing to expose the true performance of methods. Interestingly the source of this issue extends back to the inception of the problem by Sod. I want to be clear that Sod wasn’t to blame because none of the methods available to him were acceptable, but within 5 years very good methods arose, but the manner of presentation chosen originally persisted. Sod on showed qualitative pictures of the solution at a single mesh resolution (100 cells), and relative run times for the solution. This manner of presentation has persisted to the modern day (nearly 40 years almost without deviation). One can travel through the archival literature and see this pattern repeated over and over in an (almost) unthinking manner. The bottom line is that it is well past time to do better and set about using a higher standard.
For all these reasons the current standard and practice with shock capturing methods are doing a great disservice to the community. The current practice inhibits progress by hiding deep issues and failing to expose the true performance of methods. Interestingly the source of this issue extends back to the inception of the problem by Sod. I want to be clear that Sod wasn’t to blame because none of the methods available to him were acceptable, but within 5 years very good methods arose, but the manner of presentation chosen originally persisted. Sod on showed qualitative pictures of the solution at a single mesh resolution (100 cells), and relative run times for the solution. This manner of presentation has persisted to the modern day (nearly 40 years almost without deviation). One can travel through the archival literature and see this pattern repeated over and over in an (almost) unthinking manner. The bottom line is that it is well past time to do better and set about using a higher standard.

 instead of the standard
instead of the standard  . This subtlety is usually lost in a field where people don’t convergence test at all unless they expect full order of accuracy for the problem.
. This subtlety is usually lost in a field where people don’t convergence test at all unless they expect full order of accuracy for the problem.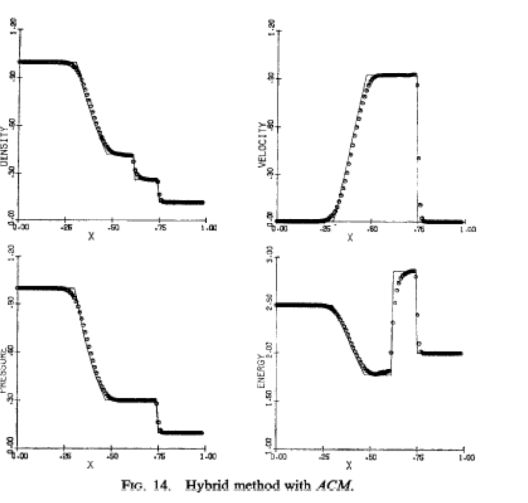
 is exactly the spirit that has been utterly lost by the current high performance computer push. In a deep way the program lacks the appropriate humanity in its composition, which is absolutely necessary for progress.
is exactly the spirit that has been utterly lost by the current high performance computer push. In a deep way the program lacks the appropriate humanity in its composition, which is absolutely necessary for progress. enerated history of scientific computing. The key to the success and impact of scientific computing has been its ability to augment its foundational fields as a supplement to human’s innate intellect in an area that human’s ability is a bit diminished. While it supplements raw computational power, the impact of the field depends entirely on human’s natural talent as expressed in the base science and mathematics. One place of natural connection is the mathematical expression of the knowledge in basic science. Among the greatest sins of modern scientific computing is the diminished role of mathematics in the march toward progress.
enerated history of scientific computing. The key to the success and impact of scientific computing has been its ability to augment its foundational fields as a supplement to human’s innate intellect in an area that human’s ability is a bit diminished. While it supplements raw computational power, the impact of the field depends entirely on human’s natural talent as expressed in the base science and mathematics. One place of natural connection is the mathematical expression of the knowledge in basic science. Among the greatest sins of modern scientific computing is the diminished role of mathematics in the march toward progress. greater scientific computing. For example I work in an organization that is devoted to applied mathematics, yet virtually no mathematics actually takes place. Our applied mathematics programs have turned into software programs. Somehow the decision was made 20-30 years ago that software “weaponized” mathematics, and in the process the software became the entire enterprise, and the mathematics itself became lost, an afterthought of the process. Without the actual mathematical foundation for computing, important efficiencies, powerful insights and structural understanding is scarified.
greater scientific computing. For example I work in an organization that is devoted to applied mathematics, yet virtually no mathematics actually takes place. Our applied mathematics programs have turned into software programs. Somehow the decision was made 20-30 years ago that software “weaponized” mathematics, and in the process the software became the entire enterprise, and the mathematics itself became lost, an afterthought of the process. Without the actual mathematical foundation for computing, important efficiencies, powerful insights and structural understanding is scarified. raison d’être for math programs. In the process of the emphasis on the software instantiating mathematical ideas, the production and assault on mathematics has stalled. It has lost its centrality to the enterprise. This is horrible because there is so much yet to do.
raison d’être for math programs. In the process of the emphasis on the software instantiating mathematical ideas, the production and assault on mathematics has stalled. It has lost its centrality to the enterprise. This is horrible because there is so much yet to do. pletely unthinkable to be achieved. Discoveries make the impossible, possible, and we are denying ourselves the possibility of these results through our inept management of mathematics proper role in scientific computing. What might be some of the important topics in need of refined and focused mathematical thinking?
pletely unthinkable to be achieved. Discoveries make the impossible, possible, and we are denying ourselves the possibility of these results through our inept management of mathematics proper role in scientific computing. What might be some of the important topics in need of refined and focused mathematical thinking? y related to the multi-dimensional issues with compressible fluids is the topic of one of the Clay prizes. This is a million dollar prize for proving the existence of solutions to the Navier-Stokes equations. There is a deep problem with the way this problem is posed that may make its solution both impossible and practically useless. The equations posed in the problem statement are fundamentally wrong. They are physically wrong, not mathematically although this wrongness has consequences. In a very deep practical way fluids are never truly incompressible; incompressible is an approximation, but not a fact. This makes the equations have an intrinsically elliptic character (because incompressibility implies infinite sound speeds, and lack of thermodynamic character).
y related to the multi-dimensional issues with compressible fluids is the topic of one of the Clay prizes. This is a million dollar prize for proving the existence of solutions to the Navier-Stokes equations. There is a deep problem with the way this problem is posed that may make its solution both impossible and practically useless. The equations posed in the problem statement are fundamentally wrong. They are physically wrong, not mathematically although this wrongness has consequences. In a very deep practical way fluids are never truly incompressible; incompressible is an approximation, but not a fact. This makes the equations have an intrinsically elliptic character (because incompressibility implies infinite sound speeds, and lack of thermodynamic character). s such models tractable or not. The existence theory problems for the incompressible Navier-Stokes equations are essential for turbulence. For a century it has largely been assumed that the Navier-Stokes equations describe turbulent flow with an acute focus on incompressibility. More modern understanding should have highlighted that the very mechanism we depend upon for creating the sort of singularities turbulence observations imply has been removed in the process of the choice of incompressibility. The irony is absolutely tragic. Turbulence brings almost an endless amount of difficulty to its study whether experimental, theoretical, or computational. In every case the depth of the necessary contributions by mathematics is vast. It seems somewhat likely that we have compounded the difficulty of turbulence by choosing a model with terrible properties. If so, it is likely that the problem remains unsolved, not due to its difficulty, but rather our blindness to the shortcomings, and the almost religious faith many have followed in attacking turbulence with such a model.
s such models tractable or not. The existence theory problems for the incompressible Navier-Stokes equations are essential for turbulence. For a century it has largely been assumed that the Navier-Stokes equations describe turbulent flow with an acute focus on incompressibility. More modern understanding should have highlighted that the very mechanism we depend upon for creating the sort of singularities turbulence observations imply has been removed in the process of the choice of incompressibility. The irony is absolutely tragic. Turbulence brings almost an endless amount of difficulty to its study whether experimental, theoretical, or computational. In every case the depth of the necessary contributions by mathematics is vast. It seems somewhat likely that we have compounded the difficulty of turbulence by choosing a model with terrible properties. If so, it is likely that the problem remains unsolved, not due to its difficulty, but rather our blindness to the shortcomings, and the almost religious faith many have followed in attacking turbulence with such a model. es to problem solving. An area in need of fresh ideas, connections and better understanding is mechanics. This is a classical field with a rich and storied past, but suffering from a dire lack of connection between the classical mathematical rigor and the modern numerical world. Perhaps in no way is this more evident in the prevalent use of hypo-elastic models where hyper-elasticity would be far better. The hypo-elastic legacy comes from the simplicity of its numerical solution being the basis of methods and codes used around the World. It also only applies to very small incremental deformations. For the applications being studied, it should is invalid. In spite of this famous shortcoming, hypo-elasticity rules supreme, and hyper-elasticity sits in an almost purely academic role. Progress is needed here and mathematical rigor is part of the solution.
es to problem solving. An area in need of fresh ideas, connections and better understanding is mechanics. This is a classical field with a rich and storied past, but suffering from a dire lack of connection between the classical mathematical rigor and the modern numerical world. Perhaps in no way is this more evident in the prevalent use of hypo-elastic models where hyper-elasticity would be far better. The hypo-elastic legacy comes from the simplicity of its numerical solution being the basis of methods and codes used around the World. It also only applies to very small incremental deformations. For the applications being studied, it should is invalid. In spite of this famous shortcoming, hypo-elasticity rules supreme, and hyper-elasticity sits in an almost purely academic role. Progress is needed here and mathematical rigor is part of the solution. re less reliable). This area needs new ideas and a fresh perspective in the worst way. The second classical area of investigation that has stalled is high-order methods. I’ve written about this a lot. Needless to say we need a combination of new ideas, and a somewhat more honest and pragmatic assessment of what is needed in practical terms. We have to thread the needle of accuracy, efficiency and robustness in both cases. Again without mathematics holding us to the level of rigor it demands progress seems unlikely.
re less reliable). This area needs new ideas and a fresh perspective in the worst way. The second classical area of investigation that has stalled is high-order methods. I’ve written about this a lot. Needless to say we need a combination of new ideas, and a somewhat more honest and pragmatic assessment of what is needed in practical terms. We have to thread the needle of accuracy, efficiency and robustness in both cases. Again without mathematics holding us to the level of rigor it demands progress seems unlikely. orlds of physics and engineering need to seek mathematical rigor as a part of solidifying advances. Mathematics needs to seek inspiration from physics and engineering. Sometimes we need the pragmatic success in the ad hoc “seat of the pants” approach to provide the impetus for mathematical investigation. Finding out that something works tends to be a powerful driver to understanding why something works. For example the field of compressed sensing arose from a practical and pragmatic regularization method that worked without theoretical support. Far too much emphasis is placed on software and far too little on mathematical discovery and deep understand. We need a lot more discovery and understanding today, perhaps no place more than scientific computing!
orlds of physics and engineering need to seek mathematical rigor as a part of solidifying advances. Mathematics needs to seek inspiration from physics and engineering. Sometimes we need the pragmatic success in the ad hoc “seat of the pants” approach to provide the impetus for mathematical investigation. Finding out that something works tends to be a powerful driver to understanding why something works. For example the field of compressed sensing arose from a practical and pragmatic regularization method that worked without theoretical support. Far too much emphasis is placed on software and far too little on mathematical discovery and deep understand. We need a lot more discovery and understanding today, perhaps no place more than scientific computing! and terrifying shit show of the 2016 American Presidential election. It all seems to be coming together in a massive orgy of angst, lack of honesty and fundamental integrity across the full spectrum of life. As an active adult within this society I feel the forces tugging away at me, and I want to recoil from the carnage I see. A lot of days it seems safer to simply stay at home and hunker down and let this storm pass. It seems to be present at every level of life involving what is open and obvious to what is private and hidden.
and terrifying shit show of the 2016 American Presidential election. It all seems to be coming together in a massive orgy of angst, lack of honesty and fundamental integrity across the full spectrum of life. As an active adult within this society I feel the forces tugging away at me, and I want to recoil from the carnage I see. A lot of days it seems safer to simply stay at home and hunker down and let this storm pass. It seems to be present at every level of life involving what is open and obvious to what is private and hidden. the same thing is that progress depends on finding important, valuable problems and driving solutions. A second piece of integrity is hard work, persistence, and focus on the important valuable problems linked to great National or World concerns. Lastly, a powerful aspect of integrity is commitment to self. This includes a focus on self-improvement, and commitment to a full and well-rounded life. Every single bit of this is in rather precarious and constant tension, which is fine. What isn’t fine is the intrusion of outright bullshit into the mix undermining integrity at every turn.
the same thing is that progress depends on finding important, valuable problems and driving solutions. A second piece of integrity is hard work, persistence, and focus on the important valuable problems linked to great National or World concerns. Lastly, a powerful aspect of integrity is commitment to self. This includes a focus on self-improvement, and commitment to a full and well-rounded life. Every single bit of this is in rather precarious and constant tension, which is fine. What isn’t fine is the intrusion of outright bullshit into the mix undermining integrity at every turn. inimal value that get marketed as breakthroughs. The lack of integrity at the level of leadership simply takes this bullshit and passes it along. Eventually the bullshit gets to people who are incapable of recognizing the difference. Ultimately, the result of the acceptance of bullshit produces a lowering of standards, and undermines the reality of progress. Bullshit is the death of integrity in the professional world.
inimal value that get marketed as breakthroughs. The lack of integrity at the level of leadership simply takes this bullshit and passes it along. Eventually the bullshit gets to people who are incapable of recognizing the difference. Ultimately, the result of the acceptance of bullshit produces a lowering of standards, and undermines the reality of progress. Bullshit is the death of integrity in the professional world. within a vibrant and growing bullshit economy. Taken in this broad context, the dominance of bullshit in my professional life and the potential election of Donald Trump are closely connected.
within a vibrant and growing bullshit economy. Taken in this broad context, the dominance of bullshit in my professional life and the potential election of Donald Trump are closely connected. ated by fear mongering bullshit. Even worse it has paved the way for greater purveyors of bullshit like Trump. We may well see bullshit providing the vehicle to elect an unqualified con man as the President.
ated by fear mongering bullshit. Even worse it has paved the way for greater purveyors of bullshit like Trump. We may well see bullshit providing the vehicle to elect an unqualified con man as the President. e beauty of it is the made up shit can conform to whatever narrative you desire, and completely fit whatever your message is. In such a world real problems can simply be ignored when the path to progress is problematic for those in power.
e beauty of it is the made up shit can conform to whatever narrative you desire, and completely fit whatever your message is. In such a world real problems can simply be ignored when the path to progress is problematic for those in power. n the early days of computational science we were just happy to get things to work for simple physics in one spatial dimension. Over time, our grasp on more difficult coupled multi-dimensional physics became ever more bold and expansive. The quickest route to this goal was the use of operator splitting where the simple operators, single physics and one-dimensional were composed into complex operators. Most of our complex multiphysics codes operate in this operator split manner. Research into doing better almost always entails doing away with this composition of operators, or operator splitting and doing everything fully coupled. It is assumed that this is always superior. Reality is more difficult than this proposition, and most of the time the fully coupled or unsplit approach is actually worse with lower accuracy and greater expense with little identifiable benefits. So the question is should we keep trying to do this?
n the early days of computational science we were just happy to get things to work for simple physics in one spatial dimension. Over time, our grasp on more difficult coupled multi-dimensional physics became ever more bold and expansive. The quickest route to this goal was the use of operator splitting where the simple operators, single physics and one-dimensional were composed into complex operators. Most of our complex multiphysics codes operate in this operator split manner. Research into doing better almost always entails doing away with this composition of operators, or operator splitting and doing everything fully coupled. It is assumed that this is always superior. Reality is more difficult than this proposition, and most of the time the fully coupled or unsplit approach is actually worse with lower accuracy and greater expense with little identifiable benefits. So the question is should we keep trying to do this? solution involves a precise dynamic balance. This is when you have the situation of equal and opposite terms in the equations that produce solutions in near equilibrium. This produces critical points where solution make complete turns in outcomes based on the very detailed nature of the solution. These situations also produce substantial changes in the effective time scales of the solution. When very fast phenomena combine in this balanced form, the result is a slow time scale. It is most acute in the form of the steady-state solution where such balances are the full essence of the physical solution. This is where operator splitting is problematic and should be avoided.
solution involves a precise dynamic balance. This is when you have the situation of equal and opposite terms in the equations that produce solutions in near equilibrium. This produces critical points where solution make complete turns in outcomes based on the very detailed nature of the solution. These situations also produce substantial changes in the effective time scales of the solution. When very fast phenomena combine in this balanced form, the result is a slow time scale. It is most acute in the form of the steady-state solution where such balances are the full essence of the physical solution. This is where operator splitting is problematic and should be avoided. ods is their disadvantage for the fundamental approximations. When operators are discretized separately quite efficient and optimized approaches can be applied. For example if solving a hyperbolic equation it can be very effective and efficient to produce an extremely high-order approximation to the equations. For the fully coupled (unsplit) case such approximations are quite expensive, difficult and complex to produce. If the solution you are really interested in is first-order accurate, the benefit of the fully coupled case is mostly lost. This is with the distinct exception of small part of the solution domain where the dynamic balance is present and the benefits of coupling are undeniable.
ods is their disadvantage for the fundamental approximations. When operators are discretized separately quite efficient and optimized approaches can be applied. For example if solving a hyperbolic equation it can be very effective and efficient to produce an extremely high-order approximation to the equations. For the fully coupled (unsplit) case such approximations are quite expensive, difficult and complex to produce. If the solution you are really interested in is first-order accurate, the benefit of the fully coupled case is mostly lost. This is with the distinct exception of small part of the solution domain where the dynamic balance is present and the benefits of coupling are undeniable. method should be adaptive and locally tailored to the nature of the solution. One size fits all is almost never the right answer (to anything). Unfortunately this whole line of attack is not favored by anyone these days, we seem to be stuck in the worst of both worlds where codes used for solving real problems are operator split, and research is focused on coupling without regard for the demands of reality. We need to break out of this stagnation! This is ironic because stagnation is one of the things that coupled methods excel at!
method should be adaptive and locally tailored to the nature of the solution. One size fits all is almost never the right answer (to anything). Unfortunately this whole line of attack is not favored by anyone these days, we seem to be stuck in the worst of both worlds where codes used for solving real problems are operator split, and research is focused on coupling without regard for the demands of reality. We need to break out of this stagnation! This is ironic because stagnation is one of the things that coupled methods excel at! Today’s title is a conclusion that comes from my recent assessments and experiences at work. It has completely thrown me off stride as I struggle to come to terms with the evidence in front of me. The obvious and reasonable conclusions from the consideration of recent experiential evidence directly conflicts with most of my most deeply held values. As a result I find myself in a deep quandary about how to proceed with work. Somehow my performance is perceived to be better when I don’t care much about my work. One reasonable conclusion is that when I have little concern about outcomes of the work, I don’t show my displeasure when those outcomes are poor.
Today’s title is a conclusion that comes from my recent assessments and experiences at work. It has completely thrown me off stride as I struggle to come to terms with the evidence in front of me. The obvious and reasonable conclusions from the consideration of recent experiential evidence directly conflicts with most of my most deeply held values. As a result I find myself in a deep quandary about how to proceed with work. Somehow my performance is perceived to be better when I don’t care much about my work. One reasonable conclusion is that when I have little concern about outcomes of the work, I don’t show my displeasure when those outcomes are poor. nal integrity is important to pay attention to. Hard work, personal excellence and a devotion to progress has been the path to my success professionally. The only thing that the current environment seems to favor is hard work (and even that’s questionable). The issues causing tension are related to technical and scientific quality, or work that denotes any commitment to technical excellence. It’s everything I’ve written about recently, success with high performance computing, progress in computational science, and integrity in peer review. Attention to any and all of these topics is a source of tension that seems to be completely unwelcome. We seem to be managed to mostly pay attention to nothing but the very narrow and well-defined boundaries of work. Any thinking or work “outside the box” seems to invite ire, punishment and unhappiness. Basically, the evidence seems to indicate that my performance is perceived to be much better if I “stay in the box”. In other words I am managed to be predictable and well defined in my actions, don’t provide any surprises.
nal integrity is important to pay attention to. Hard work, personal excellence and a devotion to progress has been the path to my success professionally. The only thing that the current environment seems to favor is hard work (and even that’s questionable). The issues causing tension are related to technical and scientific quality, or work that denotes any commitment to technical excellence. It’s everything I’ve written about recently, success with high performance computing, progress in computational science, and integrity in peer review. Attention to any and all of these topics is a source of tension that seems to be completely unwelcome. We seem to be managed to mostly pay attention to nothing but the very narrow and well-defined boundaries of work. Any thinking or work “outside the box” seems to invite ire, punishment and unhappiness. Basically, the evidence seems to indicate that my performance is perceived to be much better if I “stay in the box”. In other words I am managed to be predictable and well defined in my actions, don’t provide any surprises. The only way I can “stay in the box” is to turn my back on the same values that brought me success. Most of my professional success is based on doing “out of the box” thinking working to provide real progress on important issues. Recently it’s been pretty clear that this isn’t appreciated any more. To stop thinking out of the box I need to stop giving a shit. Every time I seem to care more deeply about work and do something extra not only is it not appreciated; it gets me into trouble. Just do the minimum seems to be the real directive, and extra effort is not welcome seem to be the modern mantra. Do exactly what you’re told to do, no more and no less. This is the path to success.
The only way I can “stay in the box” is to turn my back on the same values that brought me success. Most of my professional success is based on doing “out of the box” thinking working to provide real progress on important issues. Recently it’s been pretty clear that this isn’t appreciated any more. To stop thinking out of the box I need to stop giving a shit. Every time I seem to care more deeply about work and do something extra not only is it not appreciated; it gets me into trouble. Just do the minimum seems to be the real directive, and extra effort is not welcome seem to be the modern mantra. Do exactly what you’re told to do, no more and no less. This is the path to success. done the experiment and the evidence was absolutely clear. When I don’t care, don’t give a shit and have different priorities than work, I get awesome performance reviews. When I do give a shit, it creates problems. A big part of the problem is the whole “in the box” and “out of the box” issue. We are managed to provide predictable results and avoid surprises. It is all part of the low risk mindset that permeates the current World, and the workplace as well. Honesty and progress is a source of tension (i.e., risk) and as such it makes waves, and if you make waves you create problems. Management doesn’t like tension, waves or anything that isn’t completely predictable. Don’t cause trouble or make problems, just do stuff that makes us look good. The best way to provide this sort of outcome is just come to work and do what you’re expected to do, no more, no less. Don’t be creative and let someone else tell you what is important. In other words, don’t give a shit, or better yet don’t give fuck either.
done the experiment and the evidence was absolutely clear. When I don’t care, don’t give a shit and have different priorities than work, I get awesome performance reviews. When I do give a shit, it creates problems. A big part of the problem is the whole “in the box” and “out of the box” issue. We are managed to provide predictable results and avoid surprises. It is all part of the low risk mindset that permeates the current World, and the workplace as well. Honesty and progress is a source of tension (i.e., risk) and as such it makes waves, and if you make waves you create problems. Management doesn’t like tension, waves or anything that isn’t completely predictable. Don’t cause trouble or make problems, just do stuff that makes us look good. The best way to provide this sort of outcome is just come to work and do what you’re expected to do, no more, no less. Don’t be creative and let someone else tell you what is important. In other words, don’t give a shit, or better yet don’t give fuck either.
