People almost invariably arrive at their beliefs not on the basis of proof but on the basis of what they find attractive.
― Blaise Pascal
 When we hear about supercomputing, the media focus, press release is always talking about massive calculations. The bigger is always better with as many zeros as possible with some sort of exotic name for the rate of computation, mega, tera, peta, eta, zeta,… Up and to the right! The implicit proposition is that bigger the calculation, the better the science. This is quite simply complete and utter bullshit. These big calculations providing the media footprint for supercomputing and winning prizes are simply stunts, or more generously technology demonstrations, and not actual science. Scientific computation is a much more involved and thoughtful activity involving lots of different calculations many at a vastly smaller scale. Rarely, if ever, do the massive calculations come as a package including the sorts of evidence science is based upon. Real science has error analysis, uncertainty estimates, and in this sense the massive calculations produce a disservice to computational science by skewing the picture of what science using computers should look like.
When we hear about supercomputing, the media focus, press release is always talking about massive calculations. The bigger is always better with as many zeros as possible with some sort of exotic name for the rate of computation, mega, tera, peta, eta, zeta,… Up and to the right! The implicit proposition is that bigger the calculation, the better the science. This is quite simply complete and utter bullshit. These big calculations providing the media footprint for supercomputing and winning prizes are simply stunts, or more generously technology demonstrations, and not actual science. Scientific computation is a much more involved and thoughtful activity involving lots of different calculations many at a vastly smaller scale. Rarely, if ever, do the massive calculations come as a package including the sorts of evidence science is based upon. Real science has error analysis, uncertainty estimates, and in this sense the massive calculations produce a disservice to computational science by skewing the picture of what science using computers should look like.
This post aims to correct this rather improper vision, and replace it with a discussion of what computational science should be.
With a substantial amount of focus on the drive toward the first exascale supercomputer, it is high time to remind everyone that a single massive calculation is a stunt meant to sell the purchase of said computers, and not science. This week the supercomputing community is meeting in Salt Lake City for a trade show  masquerading as a scientific conference. It is simply another in a phalanx of echo chambers we seem to form with increasing regularity across every sector of society. I’m sure the cheerleaders for supercomputing will be crowing about the transformative power of these computers and the boon for science they represent. There will be celebrations of enormous calculations and pronouncements about their scientific value. There is a certain lack of political correctness to the truth about all this; it is mostly pure bullshit.
masquerading as a scientific conference. It is simply another in a phalanx of echo chambers we seem to form with increasing regularity across every sector of society. I’m sure the cheerleaders for supercomputing will be crowing about the transformative power of these computers and the boon for science they represent. There will be celebrations of enormous calculations and pronouncements about their scientific value. There is a certain lack of political correctness to the truth about all this; it is mostly pure bullshit.
The entire enterprise pushing toward exascale is primarily a technology push program. It is a furious and futile attempt to stave off the death of Moore’s law. Moore’s law has  provided an enormous gain in the power of computers for 50 years and enabled much of the transformative power of computing technology. The key point is that computers and software are just tools; they are incredibly useful tools, but tools nonetheless. Tools allow a human being to extend their own biological capabilities in a myriad of ways. Computers are marvelous at replicating and automating calculations and thought operations at speeds utterly impossible for humans. Everything useful done with these tools is utterly dependent on human beings to devise. My key critique about this approach to computing is the hollowing out of the investigation into devising better ways to use computers and focusing myopically on enhancing the speed of computation.
provided an enormous gain in the power of computers for 50 years and enabled much of the transformative power of computing technology. The key point is that computers and software are just tools; they are incredibly useful tools, but tools nonetheless. Tools allow a human being to extend their own biological capabilities in a myriad of ways. Computers are marvelous at replicating and automating calculations and thought operations at speeds utterly impossible for humans. Everything useful done with these tools is utterly dependent on human beings to devise. My key critique about this approach to computing is the hollowing out of the investigation into devising better ways to use computers and focusing myopically on enhancing the speed of computation.
Truth is only relative to those that ignore hard evidence.
― A.E. Samaan
The core of my assertion that its mostly bullshit comes from looking at the scientific method and its application to these enormous calculations. The scientific method is fundamentally about understanding the World (and using this understanding via engineering). The World is observed either in its natural form, or through experiments de vised to unveil difficult to see phenomena. We then produce explanations or theories to describe what we see, and allow us to predict what we haven’t see yet. The degree of comparison between the theory and the observations confirms our degree of understanding. There is always a gap between our theory and our observations, and each is imperfect in its own way. Observations are intrinsically prone to a variety of errors, and theory is always imperfect. The solutions to theoretical models are also imperfect especially when solved via computation. Understanding these imperfections and the nature of the comparisons between theory and observation is essential to a comprehension of the state of our science.
vised to unveil difficult to see phenomena. We then produce explanations or theories to describe what we see, and allow us to predict what we haven’t see yet. The degree of comparison between the theory and the observations confirms our degree of understanding. There is always a gap between our theory and our observations, and each is imperfect in its own way. Observations are intrinsically prone to a variety of errors, and theory is always imperfect. The solutions to theoretical models are also imperfect especially when solved via computation. Understanding these imperfections and the nature of the comparisons between theory and observation is essential to a comprehension of the state of our science.
 As I’ve stated before, the scientific method applied to scientific computing is embedded in the practice of verification and validation. Simply stated, a single massive calculation cannot be verified or validated (it could be, but not with current computational techniques and the development of such capability is a worthy research endeavor). The uncertainties in the solution and the model cannot be unveiled in a single calculation, and the comparison with observations cannot be put into a quantitative context. The proponents of our current approach to computing want you to believe that massive calculations have intrinsic scientific value. Why? Because they are so big, they have to be the truth. The problem with this thinking is that any single calculation does not contain steps necessary for determining the quality of the calculation, or putting any model comparison in context.
As I’ve stated before, the scientific method applied to scientific computing is embedded in the practice of verification and validation. Simply stated, a single massive calculation cannot be verified or validated (it could be, but not with current computational techniques and the development of such capability is a worthy research endeavor). The uncertainties in the solution and the model cannot be unveiled in a single calculation, and the comparison with observations cannot be put into a quantitative context. The proponents of our current approach to computing want you to believe that massive calculations have intrinsic scientific value. Why? Because they are so big, they have to be the truth. The problem with this thinking is that any single calculation does not contain steps necessary for determining the quality of the calculation, or putting any model comparison in context.
The context of any given calculation is determined by the structure of the errors associated with the computational modeling. For example it is important to understand the nature of any numerical errors, and producing an estimate of these errors. In some (many, most) cases a very good comparison between reality and a model is the result of calibration of uncertain model parameters. In many cases the choices for the modeling parameters are mesh dependent, which produces the uncomfortable outcome where a finer mesh produces a systematically worse comparison. This state of affairs is incredibly common, and generally an unadvertised feature.
An important meta-feature of the computing dialog is the skewing of computer size, design and abilities. For example, the term capability computer comes up where these computers can produce the largest calculations we see, the ones on press release s. These computers are generally the focus of all the attention and cost the most money. The dirty secret is that they are almost completely useless for science and engineering. They are technology demonstrations and little else. They do almost nothing of value to the myriad of programs reporting to use computations to do produce results. All of the utility to actual science and engineering come from the homely cousins of these supercomputers, the capacity computers. These computers are the workhorses of science and engineering because they are set up to do something useful. The capability computers are just show ponies, and perfect exemplars of the modern bullshit based science economy. I’m not OK with this; I’m here to do science and engineering. Are our so-called leaders OK with the focus of attention (and bulk of funding) being non-scientific, media-based, press release generators?
s. These computers are generally the focus of all the attention and cost the most money. The dirty secret is that they are almost completely useless for science and engineering. They are technology demonstrations and little else. They do almost nothing of value to the myriad of programs reporting to use computations to do produce results. All of the utility to actual science and engineering come from the homely cousins of these supercomputers, the capacity computers. These computers are the workhorses of science and engineering because they are set up to do something useful. The capability computers are just show ponies, and perfect exemplars of the modern bullshit based science economy. I’m not OK with this; I’m here to do science and engineering. Are our so-called leaders OK with the focus of attention (and bulk of funding) being non-scientific, media-based, press release generators?
 How would we do a better job with science and high performance computing?
How would we do a better job with science and high performance computing?
The starting point is the full embrace of the scientific method. Taken at face value the observational or experimental community is expected to provide observational uncertainties with their data. These uncertainties should be de-convolved between errors/uncertainties in raw measurement and any variability in the phenomena. Those of us using such measurements for validating codes should demand that observations always come with these uncertainties. By the same token, computational simulations have uncertainties from a variety numerical errors and modeling choices and assumptions that should be demanded. Each of these error sources needs to be characterized to put any comparison with observations/experimental data into context. Without knowledge of these uncertainties on both sides of the scientific process, any comparison is completely untethered.
If nothing else, the uncertainty in any aspect of this process provides a degree of confidence and impact of comparative differences. If a comparison between a model and data is poor, but the data has large uncertainties, the comparison suddenly becomes more palatable. On the other hand small uncertainties with the data would imply that the model is potentially too incorrect. This conclusion would be made once the modeling uncertainty has been explored. One reasonable case would be the identification of large numerical errors in the model’s solution. This is the case where a refined calculation might be genuinely justified. If the bias with a coarse grid is sufficient, a finer grid calculation could be a reasonable way of getting more agreement. Ther e are certainly cases where exascale computing is enabling for model solutions with small enough error to make models useful. This case is rarely made or justified in any massive calculation rather being asserted by authority.
e are certainly cases where exascale computing is enabling for model solutions with small enough error to make models useful. This case is rarely made or justified in any massive calculation rather being asserted by authority.
On the other hand numerical error could be a small contributor to the disagreement. In this case, which is incredibly common, a finer mesh does little to rectify model error or uncertainty. The lack of quality comparison is dominated by modeling error, or uncertainty about the parameterization of the models. Worse yet, the models are poor representations of the physics of interest. If the model is a poor representation solving it very accurately is a genuinely wasteful exercise, at least if your goal is scientific in nature. If you’re interested in colorful graphics and a marketing exercise, computer power is your friend, but don’t confuse this with science (or at least good science). The worst case of this issue is a dominant model form error. This is the case where the model is simply wrong, and incapable of reproducing the data. Today many examples exist where models we know are wrong are beat to death with a supercomputer. This does little to advance science, which needs to work at producing a new model that ameliorates the deficiencies in the old model. Unfortunately our supercomputing programs are sapping the vitality from our modeling programs. Even worse, many people seem to confuse computing power as a remedy to model form error.
Equidistributed error is probably the best goal of modeling and simulation that is a balance of numerical and modeling error/uncertainty. This would be the case where the combination of modeling error and uncertainty with a numerical solution has the smallest value. The standard exascale computing driven model would have the numerical error driven to be nearly zero without regard for the modeling error. This ends up being a small numerical error by fiat or proof by authority, proof by overwhelming power. Practically, this is foolhardy and technically indefensible. The issue is the inability to effectively hunt down modeling uncertainties under these conditions, which is hamstrung by the massive cal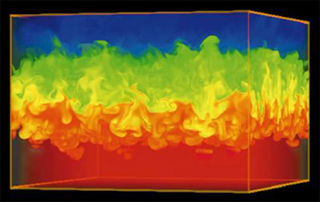 culations. The most common practice is to assess the modeling uncertainty via some sort of sampling approach. This requires many calculations because of the high-dimensional nature of the problem. Sampling converges very slowly with any mean value for the modeling being proportional to the inverse square root of the number of samples and the measure of the variance of the solution.
culations. The most common practice is to assess the modeling uncertainty via some sort of sampling approach. This requires many calculations because of the high-dimensional nature of the problem. Sampling converges very slowly with any mean value for the modeling being proportional to the inverse square root of the number of samples and the measure of the variance of the solution.
Thus a single calculation will have an undefined variance. With a single massive calculation you have no knowledge of the uncertainty either modeling or numerical (at least without have some sort of embedded uncertainty methodology). Without assessing the uncertainty of the calculation you don’t have a scientific or engineering activity. For driving down the inherent uncertainties especially where the modeling uncertainty dominates, you are aided by smaller calculations that can be executed over and over as to drive down the uncertainty. These calculations are always done on capacity computers and never on capability computers. In fact if you try to use a capability computer to do one of these studies, you will be punished and get kicked off. In other words the rules of use enforced via the queuing policies are anti-scientific.
 The uncertainty structure can be approached at a high level, but to truly get to the bottom of the issue requires some technical depth. For example numerical error has many potential sources: discretization error (space, time, energy, … whatever we approximate in), linear algebra error, nonlinear solver error, round-off error, solution regularity and smoothness. Many classes of problems are not well posed and admit multiple physically valid solutions. In this case the whole concept of convergence under mesh refinement needs overhauling. Recently the concept of measure-valued (statistical) solutions has entered the fray. These are taxing on computer resources in the same manner as sampling approaches to uncertainty. Each of these sources requires specific and focused approaches to their estimation along with requisite fidelity.
The uncertainty structure can be approached at a high level, but to truly get to the bottom of the issue requires some technical depth. For example numerical error has many potential sources: discretization error (space, time, energy, … whatever we approximate in), linear algebra error, nonlinear solver error, round-off error, solution regularity and smoothness. Many classes of problems are not well posed and admit multiple physically valid solutions. In this case the whole concept of convergence under mesh refinement needs overhauling. Recently the concept of measure-valued (statistical) solutions has entered the fray. These are taxing on computer resources in the same manner as sampling approaches to uncertainty. Each of these sources requires specific and focused approaches to their estimation along with requisite fidelity.
Modeling uncertainty is similarly complex and elaborate. The hardest aspect to evaluate is the form of the physical model. In cases where multiple reasonable models exist, the issue is evaluating the model’s (or sub-model’s) influence on solutions. Models often have adjustable parameters that are unknown or subject to calibration. Most commonly the impact of these parameters and their values are investigated via sampling solutions, an expensive prospect. Similarly there are modeling issues that are purely random, or statistical in nature. The solution to the problem is simply not determinate. Again sampling the solution of a range of parameters that define such randomness is a common approach. All this sampling is very expensive and very difficult to accurately compute. All of our focus on exascale does little to enable good outcomes.
The last area of error is the experimental or observational error and uncertainty. This is important in defining the relative quality of modeling, and the sense and sensibility of using massive computing resources to solve models. We have several standard components in the structure of the error in experiments: the error in measuring a quantity, and then the variation in the actual measured quantity. In one case there is some intrinsic uncertainty in being able to measure something with complete precision. The second part of this is the variation of the actual value in the experiment. Turbulence is the archetype of this sort of phenomena. This uncertainty is intrinsically statistical, and the decomposition is essential to truly understand the nature of the world, and put modeling in proper and useful context.
 The bottom line is that science and engineering is evidence. To do things correctly you need to operate on an evidentiary basis. More often than not, high performance computing avoids this key scientific approach. Instead we see the basic decision-making operating via assumption. The assumption is that a bigger, more expensive calculation is always better and always serves the scientific interest. This view is as common as it is naïve. There are many and perhaps most cases where the greatest service of science is many smaller calculations. This hinges upon the overall structure of uncertainty in the simulations and whether it is dominated by approximation error, modeling form or lack of knowledge, and even the observational quality available. These matters are subtle and complex, and we all know that today neither subtle, nor complex sells.
The bottom line is that science and engineering is evidence. To do things correctly you need to operate on an evidentiary basis. More often than not, high performance computing avoids this key scientific approach. Instead we see the basic decision-making operating via assumption. The assumption is that a bigger, more expensive calculation is always better and always serves the scientific interest. This view is as common as it is naïve. There are many and perhaps most cases where the greatest service of science is many smaller calculations. This hinges upon the overall structure of uncertainty in the simulations and whether it is dominated by approximation error, modeling form or lack of knowledge, and even the observational quality available. These matters are subtle and complex, and we all know that today neither subtle, nor complex sells.
What can be asserted without evidence can also be dismissed without evidence.
― Christopher Hitchens

 Despite a relatively obvious path to fulfillment, the estimation of numerical error in modeling and simulation appears to be worryingly difficult to achieve. A big part of the problem is outright laziness, inattention, and poor standards. A secondary issue is the mismatch between theory and practice. If we maintain reasonable pressure on the modeling and simulation community we can overcome the first problem, but it does require not accepting substandard work. The second problem requires some focused research, along with a more pragmatic approach to practical problems. Along with these systemic issues we can deal with a simpler problem, where to put the error bars on simulations, or should they show a bias or symmetric error. I strongly favor a bias.
Despite a relatively obvious path to fulfillment, the estimation of numerical error in modeling and simulation appears to be worryingly difficult to achieve. A big part of the problem is outright laziness, inattention, and poor standards. A secondary issue is the mismatch between theory and practice. If we maintain reasonable pressure on the modeling and simulation community we can overcome the first problem, but it does require not accepting substandard work. The second problem requires some focused research, along with a more pragmatic approach to practical problems. Along with these systemic issues we can deal with a simpler problem, where to put the error bars on simulations, or should they show a bias or symmetric error. I strongly favor a bias.






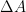


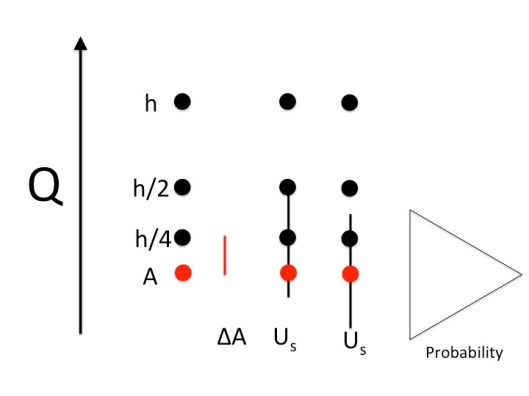 The core issue I’m talking about is the position of the numerical error bar. Current approaches center the error bar on the finite grid solution of interest, usually the finest mesh used. This has the effect of giving the impression that this solution is the most likely answer, and the true answer could be either direction from that answer. Neither of these suggestions is supported by the data used to construct the error bar. For this reason the standard practice today is problematic and should be changed to something supportable by the evidence. The current error bars suggest incorrectly that the most likely error is zero. This is completely and utterly unsupported by evidence.
The core issue I’m talking about is the position of the numerical error bar. Current approaches center the error bar on the finite grid solution of interest, usually the finest mesh used. This has the effect of giving the impression that this solution is the most likely answer, and the true answer could be either direction from that answer. Neither of these suggestions is supported by the data used to construct the error bar. For this reason the standard practice today is problematic and should be changed to something supportable by the evidence. The current error bars suggest incorrectly that the most likely error is zero. This is completely and utterly unsupported by evidence.
 mulation examples in existence are subject to bias in the solutions. This bias comes from numerical solution, modeling inadequacy, and bad assumptions to name a few of the sources. In contrast uncertainty quantification is usually applied in a statistical and clearly unbiased manner. This is a serious difference in perspective. The differences are clear. With bias the difference between simulation and reality is one sided and the deviation can be cured by calibrating parts of the model to compensate. Unbiased uncertainty is common in measurement error and ends up dominating the approach to UQ in simulations. The result is a mismatch between the dominant mode of uncertainty and how it is modeled. Coming up with a more nuanced and appropriate model that acknowledges and deals with bias appropriately would be great progress.
mulation examples in existence are subject to bias in the solutions. This bias comes from numerical solution, modeling inadequacy, and bad assumptions to name a few of the sources. In contrast uncertainty quantification is usually applied in a statistical and clearly unbiased manner. This is a serious difference in perspective. The differences are clear. With bias the difference between simulation and reality is one sided and the deviation can be cured by calibrating parts of the model to compensate. Unbiased uncertainty is common in measurement error and ends up dominating the approach to UQ in simulations. The result is a mismatch between the dominant mode of uncertainty and how it is modeled. Coming up with a more nuanced and appropriate model that acknowledges and deals with bias appropriately would be great progress. ociated with lack of computational resolution. The computational mesh is always far too coarse for comfort, and the numerical errors are significant. There are also issues associated with initial conditions, energy balance and representing physics at and below the level of the grid. In both cases the models are invariably calibrated heavily. This calibration compensates for the lack of mesh resolution, lack of knowledge of initial data and physics as well as problems with representing the energy balance essential to the simulation (especially climate). A serious modeling deficiency is the merging of all of these uncertainties into the calibration with an associated loss of information.
ociated with lack of computational resolution. The computational mesh is always far too coarse for comfort, and the numerical errors are significant. There are also issues associated with initial conditions, energy balance and representing physics at and below the level of the grid. In both cases the models are invariably calibrated heavily. This calibration compensates for the lack of mesh resolution, lack of knowledge of initial data and physics as well as problems with representing the energy balance essential to the simulation (especially climate). A serious modeling deficiency is the merging of all of these uncertainties into the calibration with an associated loss of information. The issues with calibration are profound. Without calibration the models are effectively useless. For these models to contribute to our societal knowledge and decision-making or raw scientific investigation, the calibration is an absolute necessity. Calibration depends entirely on existing data, and this carries a burden of applicability. How valid is the calibration when the simulation is probing outside the range of the data used to calibrate? We commonly include the intrinsic numerical bias in the calibration, and most commonly a turbulence or mixing model is adjusted to account for the numerical bias. A colleague familiar with ocean models quipped that if the ocean were as viscous as we modeled it, one could drive to London from New York. It is well known that numerical viscosity stabilizes calculation, and we can use numerical methods to model turbulence (implicit large eddy simulation), but this practice should at the very least make people uncomfortable. We are also left with the difficult matter of how to validate models that have been calibrated.
The issues with calibration are profound. Without calibration the models are effectively useless. For these models to contribute to our societal knowledge and decision-making or raw scientific investigation, the calibration is an absolute necessity. Calibration depends entirely on existing data, and this carries a burden of applicability. How valid is the calibration when the simulation is probing outside the range of the data used to calibrate? We commonly include the intrinsic numerical bias in the calibration, and most commonly a turbulence or mixing model is adjusted to account for the numerical bias. A colleague familiar with ocean models quipped that if the ocean were as viscous as we modeled it, one could drive to London from New York. It is well known that numerical viscosity stabilizes calculation, and we can use numerical methods to model turbulence (implicit large eddy simulation), but this practice should at the very least make people uncomfortable. We are also left with the difficult matter of how to validate models that have been calibrated. some part of the model. This issue plays out in weather and climate modeling where the mesh is part of the model rather than independent aspect of it. It should surprise no one that LES was born from weather-climate modeling (at the time where the distinction didn’t exist). In other words the chosen mesh and the model are intimately linked. If the mesh is modified, the modeling must also be modified (recalibrated) to get the balancing of the solution correct. This tends to happen in simulations where an intimate balance is essential to the phenomena. In these cases there is a system that in one respect or another is in a nearly equilibrium state, and the deviations from this equilibrium are essential. Aspects of the modeling related to the scales of interest including the grid itself impact the equilibrium to a degree that an un-calibrated model is nearly useless.
some part of the model. This issue plays out in weather and climate modeling where the mesh is part of the model rather than independent aspect of it. It should surprise no one that LES was born from weather-climate modeling (at the time where the distinction didn’t exist). In other words the chosen mesh and the model are intimately linked. If the mesh is modified, the modeling must also be modified (recalibrated) to get the balancing of the solution correct. This tends to happen in simulations where an intimate balance is essential to the phenomena. In these cases there is a system that in one respect or another is in a nearly equilibrium state, and the deviations from this equilibrium are essential. Aspects of the modeling related to the scales of interest including the grid itself impact the equilibrium to a degree that an un-calibrated model is nearly useless.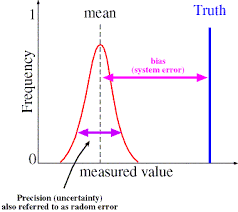 h to a value (assuming the rest of the model is held fixed) then the error is well behaved. The sequence of solutions on the meshes can then be used to estimate the solution to the mathematical problem, that is the solution where the mesh resolution is infinite (absurd as it might be). Along with this estimate of the “perfect” solution, the error can be estimated for any of the meshes. For this well-behaved case the error is one sided, a bias between the ideal solution and the one with a mesh. Any fuzz in the estimate would be applied to the bias. In other words any uncertainty in the error estimate is centered about the extrapolated “perfect” solution, not the finite grid solutions. The problem with the current accepted methodology is that the error is given as a standard two-sided error bar that is appropriate for statistical errors. In other words we use a two-sided accounting for this error even though there is no evidence for it. This is a problem that should be corrected. I should note that many models (i.e., like climate or weather) invariably recalibrate after all mesh changes, which invalidates the entire verification exercise where the model aside from the grid should be fixed across the mesh sequence.
h to a value (assuming the rest of the model is held fixed) then the error is well behaved. The sequence of solutions on the meshes can then be used to estimate the solution to the mathematical problem, that is the solution where the mesh resolution is infinite (absurd as it might be). Along with this estimate of the “perfect” solution, the error can be estimated for any of the meshes. For this well-behaved case the error is one sided, a bias between the ideal solution and the one with a mesh. Any fuzz in the estimate would be applied to the bias. In other words any uncertainty in the error estimate is centered about the extrapolated “perfect” solution, not the finite grid solutions. The problem with the current accepted methodology is that the error is given as a standard two-sided error bar that is appropriate for statistical errors. In other words we use a two-sided accounting for this error even though there is no evidence for it. This is a problem that should be corrected. I should note that many models (i.e., like climate or weather) invariably recalibrate after all mesh changes, which invalidates the entire verification exercise where the model aside from the grid should be fixed across the mesh sequence.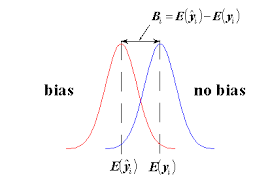 quantities that cannot be measured. In this case the uncertainty must be approached carefully. The uncertainty in these values must almost invariably be larger than the quantities used for calibration. One needs to look at the modeling connections for these values and attack a reasonable approach to treating the quantities with an appropriate “grain of salt”. This includes numerical error, which I talked about above too. In the best case there is data available that was not used to calibrate the model. Maybe these are values that are not as highly prized or as important as those used to calibrate. The uncertainty between these measured data values and the simulation gives very strong indications regarding the uncertainty in the simulation. In other cases some of the data potentially available for calibration has been left out, and can be used for validating the calibrated model. This assumes that the hold-out data is sufficiently independent of the data used.
quantities that cannot be measured. In this case the uncertainty must be approached carefully. The uncertainty in these values must almost invariably be larger than the quantities used for calibration. One needs to look at the modeling connections for these values and attack a reasonable approach to treating the quantities with an appropriate “grain of salt”. This includes numerical error, which I talked about above too. In the best case there is data available that was not used to calibrate the model. Maybe these are values that are not as highly prized or as important as those used to calibrate. The uncertainty between these measured data values and the simulation gives very strong indications regarding the uncertainty in the simulation. In other cases some of the data potentially available for calibration has been left out, and can be used for validating the calibrated model. This assumes that the hold-out data is sufficiently independent of the data used. certainty is to apply significant variation to the parameters used to calibrate the model. In addition we should include the numerical error in the uncertainty. In the case of deeply calibrated models these sources of uncertainty can be quite large and generally paint an overly pessimistic picture of the uncertainty. Conversely we have an extremely optimistic picture of uncertainty with calibration. The hope and best possible outcome is that these two views bound reality, and the true uncertainty lies between these extremes. For decision-making using simulation this bounding approach to uncertainty quantification should serve us well.
certainty is to apply significant variation to the parameters used to calibrate the model. In addition we should include the numerical error in the uncertainty. In the case of deeply calibrated models these sources of uncertainty can be quite large and generally paint an overly pessimistic picture of the uncertainty. Conversely we have an extremely optimistic picture of uncertainty with calibration. The hope and best possible outcome is that these two views bound reality, and the true uncertainty lies between these extremes. For decision-making using simulation this bounding approach to uncertainty quantification should serve us well.
 rd Business Review (HBR). I know my managers read many of the same things I do. They also read business books, sometimes in a faddish manner. Among these is Daniel Pink’s excellent “Drive”. When I read HBR I feel inspired, and hopeful (Seth Godin’s books are another source of frustration and inspiration). When I read Drive I was left yearning for a workplace that operated on the principles expressed there. Yet when I return to the reality of work these pieces of literature seem fictional, even more like science fiction. The reality of work today is almost completely orthogonal to these aspirational writings. How can my managers read these things, then turn around and operate the way they do? No one seems to actually think through what implementation of these ideas would look like in the workplace. With each passing year we fall further from the ideal, more toward a workplace that crushes dreams, and simply drives people into some sort of cardboard cutout variety of behavior without any real soul.
rd Business Review (HBR). I know my managers read many of the same things I do. They also read business books, sometimes in a faddish manner. Among these is Daniel Pink’s excellent “Drive”. When I read HBR I feel inspired, and hopeful (Seth Godin’s books are another source of frustration and inspiration). When I read Drive I was left yearning for a workplace that operated on the principles expressed there. Yet when I return to the reality of work these pieces of literature seem fictional, even more like science fiction. The reality of work today is almost completely orthogonal to these aspirational writings. How can my managers read these things, then turn around and operate the way they do? No one seems to actually think through what implementation of these ideas would look like in the workplace. With each passing year we fall further from the ideal, more toward a workplace that crushes dreams, and simply drives people into some sort of cardboard cutout variety of behavior without any real soul. While work is the focus of my adult world, similar trends are at work on our children. School has become a similarly structured training ground for compliance and squalid mediocrity. Standardized testing is one route to this outcome where children are trained to take tests and no solve problems. Standardized testing becomes the perfect rubric for the soulless workplace that awaits them in the adult world. The rejection of fact and science by society as a whole is another way. We have a large segment of society who is suspicious of intellect. Too many people now view educated intellectuals as dangerous and their knowledge and facts are rejected whenever they disagree with the politically chosen philosophy. This attitude is a direct threat to the value of an educated populace. Under a system where intellect is devalued, education transforms into a means of training the population to obey authority and fall into line. The workplace is subject to the same trends, compliance and authority is prized along with predictability of results. The lack of value for intellect is also present within the sort of research institutions I work at. This is because it threatens predictability of results. As a result out of the box thinking is discouraged, and the entire system is geared to keep everyone in the box. We create systems oriented toward control and safety without realizing the price paid for rejecting exploration and risk. We all live a life less rich and less rewarding as a result, and by accumulating this over society, a broad-based diminishment of results.
While work is the focus of my adult world, similar trends are at work on our children. School has become a similarly structured training ground for compliance and squalid mediocrity. Standardized testing is one route to this outcome where children are trained to take tests and no solve problems. Standardized testing becomes the perfect rubric for the soulless workplace that awaits them in the adult world. The rejection of fact and science by society as a whole is another way. We have a large segment of society who is suspicious of intellect. Too many people now view educated intellectuals as dangerous and their knowledge and facts are rejected whenever they disagree with the politically chosen philosophy. This attitude is a direct threat to the value of an educated populace. Under a system where intellect is devalued, education transforms into a means of training the population to obey authority and fall into line. The workplace is subject to the same trends, compliance and authority is prized along with predictability of results. The lack of value for intellect is also present within the sort of research institutions I work at. This is because it threatens predictability of results. As a result out of the box thinking is discouraged, and the entire system is geared to keep everyone in the box. We create systems oriented toward control and safety without realizing the price paid for rejecting exploration and risk. We all live a life less rich and less rewarding as a result, and by accumulating this over society, a broad-based diminishment of results. o massive structures of control and societal safety. It also creates an apparatus for big brother to come to fruition in a way that makes Orwell more prescient than ever. The counter to such widespread safety and control is the diminished richness of life that is sacrificed to achieve it. Lives well-lived and bold outcomes are reduced in achieving safety. I’ve gotten to the point where this trade no longer seems worth it. What am I staying safe for? I am risking living a pathetic and empty life in trade for safety and security, so that I can die quietly. This is life in the box, and I want to live out of the box. I want to work out of the box too.
o massive structures of control and societal safety. It also creates an apparatus for big brother to come to fruition in a way that makes Orwell more prescient than ever. The counter to such widespread safety and control is the diminished richness of life that is sacrificed to achieve it. Lives well-lived and bold outcomes are reduced in achieving safety. I’ve gotten to the point where this trade no longer seems worth it. What am I staying safe for? I am risking living a pathetic and empty life in trade for safety and security, so that I can die quietly. This is life in the box, and I want to live out of the box. I want to work out of the box too. authority. The ruling business class and wealthy elite enjoy power through subtle subjugation of the vast populace. The populace accepts their subjugation in trade for promises of safety and security through the control of risk and danger.
authority. The ruling business class and wealthy elite enjoy power through subtle subjugation of the vast populace. The populace accepts their subjugation in trade for promises of safety and security through the control of risk and danger. than later. As long as we continue to prize safety and security over possibility and potential, we can expect to be disempowered.
than later. As long as we continue to prize safety and security over possibility and potential, we can expect to be disempowered.
 of science differently. First and foremost modeling and simulation enhances our ability to make predictions and test theories. As with any tool, it needs to be used with care and skill. My proposition is that the modeling and simulation practice of verification and validation combined with uncertainty quantification (VVUQ) defines this care and skill. Moreover VVUQ provides an instantiation of the scientific method for modeling and simulation. An absence of emphasis on VVUQ in modeling and simulation programs should bring doubt and scrutiny on the level of scientific discourse involved. In order to see this one needs to examine the scientific method in a bit more detail.
of science differently. First and foremost modeling and simulation enhances our ability to make predictions and test theories. As with any tool, it needs to be used with care and skill. My proposition is that the modeling and simulation practice of verification and validation combined with uncertainty quantification (VVUQ) defines this care and skill. Moreover VVUQ provides an instantiation of the scientific method for modeling and simulation. An absence of emphasis on VVUQ in modeling and simulation programs should bring doubt and scrutiny on the level of scientific discourse involved. In order to see this one needs to examine the scientific method in a bit more detail. ce elaborate and complex mathematical models, which are difficult to solve and inhibit the effective scope of predictions. Scientific computing relaxes this limitations significantly, but only if sufficient care is taken with assuring the credibility of the simulations. The entire process of VVUQ serves to provide the assessment of the simulation so that they may confidently be used in the scientific process. Nothing about modeling and simulation changes the process of posing questions and accumulating evidence in favor of a hypothesis. It does change how that relaxing limitations on the testing of theory arrives at evidence. Theories that were not fully testable are now open to far more complete examination as they now may make broader predictions than classical approaches allowed.
ce elaborate and complex mathematical models, which are difficult to solve and inhibit the effective scope of predictions. Scientific computing relaxes this limitations significantly, but only if sufficient care is taken with assuring the credibility of the simulations. The entire process of VVUQ serves to provide the assessment of the simulation so that they may confidently be used in the scientific process. Nothing about modeling and simulation changes the process of posing questions and accumulating evidence in favor of a hypothesis. It does change how that relaxing limitations on the testing of theory arrives at evidence. Theories that were not fully testable are now open to far more complete examination as they now may make broader predictions than classical approaches allowed. nd simulation where the degree of approximate accuracy is rarely included in the overall assessment. In many cases the level of error is never addressed and studied as part of the uncertainty assessment. Thus verification plays two key roles in the scientific study using modeling and simulation. Verification acts to define the credibility of the approximate solution to the theory being tested, and an estimation of the approximation quality. Without an estimate of the numerical approximation, we possibly suffer from conflating this error with modeling imperfections, and obscuring the assessment of the validity of the model. One should be aware of the pernicious practice of simply avoiding error estimation by declarative statements of being mesh-converged. This declaration should be coupled with direct evidence of mesh convergence, and the explicit capacity to provide estimates of actual numerical error. Without such evidence the declaration should be rejected.
nd simulation where the degree of approximate accuracy is rarely included in the overall assessment. In many cases the level of error is never addressed and studied as part of the uncertainty assessment. Thus verification plays two key roles in the scientific study using modeling and simulation. Verification acts to define the credibility of the approximate solution to the theory being tested, and an estimation of the approximation quality. Without an estimate of the numerical approximation, we possibly suffer from conflating this error with modeling imperfections, and obscuring the assessment of the validity of the model. One should be aware of the pernicious practice of simply avoiding error estimation by declarative statements of being mesh-converged. This declaration should be coupled with direct evidence of mesh convergence, and the explicit capacity to provide estimates of actual numerical error. Without such evidence the declaration should be rejected. experiments or observation of the natural world. In keeping with the theme an important element of the data in the context of validation is its quality and a proper uncertainty assessment. Again this assessment is vital for its ability to put the whole comparison with simulations in context, and help define what a good or bad comparison might be. Data with small uncertainty demands a completely different comparison than large uncertainty. Similarly for the simulations where the level of uncertainty has a large impact on how to view results. When the uncertainty is unspecified either data or simulation are untethered and scientific conclusions or engineering judgments are threatened.
experiments or observation of the natural world. In keeping with the theme an important element of the data in the context of validation is its quality and a proper uncertainty assessment. Again this assessment is vital for its ability to put the whole comparison with simulations in context, and help define what a good or bad comparison might be. Data with small uncertainty demands a completely different comparison than large uncertainty. Similarly for the simulations where the level of uncertainty has a large impact on how to view results. When the uncertainty is unspecified either data or simulation are untethered and scientific conclusions or engineering judgments are threatened. perceived as vulnerability. Stating weaknesses or limitations to anything cannot be tolerated in today’s political environment, and risks project existence because it is perceived as failure. Instead of an honest assessment of the state of knowledge and level of theoretical predictivity, today’s science prefers to make over-inflated claims and publish via press release. VVUQ runs counter to this practice if done correctly. Done properly VVUQ provides people using modeling and simulation for scientific or engineering work with a detailed assessment of credibility and fitness for purpose.
perceived as vulnerability. Stating weaknesses or limitations to anything cannot be tolerated in today’s political environment, and risks project existence because it is perceived as failure. Instead of an honest assessment of the state of knowledge and level of theoretical predictivity, today’s science prefers to make over-inflated claims and publish via press release. VVUQ runs counter to this practice if done correctly. Done properly VVUQ provides people using modeling and simulation for scientific or engineering work with a detailed assessment of credibility and fitness for purpose. claration of intent by the program to seek results associated with spin and BS instead of a serious scientific or engineering effort. This end state is signaled by far more than merely a lack of VVUQ, but also the lack of serious application and modeling support. This simply compounds the lack of method and algorithm support that also plagues the program. The most cynical part of all of this is the centrality of application impact to the case made for the HPC programs. The pitch to the nation or the World is the utility of modeling and simulation to economic or physical security, yet the programs are structured to make sure this cannot happen, and will not be a viable outcome.
claration of intent by the program to seek results associated with spin and BS instead of a serious scientific or engineering effort. This end state is signaled by far more than merely a lack of VVUQ, but also the lack of serious application and modeling support. This simply compounds the lack of method and algorithm support that also plagues the program. The most cynical part of all of this is the centrality of application impact to the case made for the HPC programs. The pitch to the nation or the World is the utility of modeling and simulation to economic or physical security, yet the programs are structured to make sure this cannot happen, and will not be a viable outcome. of a solid from a molecular dynamics simulation.
of a solid from a molecular dynamics simulation. om using applications to superficially market the computers, the efforts are proportional to their proximity to the computer hardware. As a result large parts of the vital middle ground are languishing without effective support. Again we lose the middle ground that is the source of efficiency and enables the quality of the overall modeling and simulation. The creation of powerful models, solution methods, algorithms, and their instantiation in software all lack sufficient support. Each of these activities has vastly more potential than hardware to unleash capability, yet it remains without effective support. When one makes are careful examination of the program all the complexity and sophistication is centered on the hardware. The result has a simpler is better philosophy for the entire middle ground and those applications drawn into the marketing ploy.
om using applications to superficially market the computers, the efforts are proportional to their proximity to the computer hardware. As a result large parts of the vital middle ground are languishing without effective support. Again we lose the middle ground that is the source of efficiency and enables the quality of the overall modeling and simulation. The creation of powerful models, solution methods, algorithms, and their instantiation in software all lack sufficient support. Each of these activities has vastly more potential than hardware to unleash capability, yet it remains without effective support. When one makes are careful examination of the program all the complexity and sophistication is centered on the hardware. The result has a simpler is better philosophy for the entire middle ground and those applications drawn into the marketing ploy. l and complicated numerical method run with relatively simple models and simple meshes. DNS uses vast amounts of computer power on leading edge machines, but uses no model at all aside from the governing equations and very simple (albeit high-order) methods. As demands for credible simulations grow we need to embrace complexity in several directions for progress to be made.
l and complicated numerical method run with relatively simple models and simple meshes. DNS uses vast amounts of computer power on leading edge machines, but uses no model at all aside from the governing equations and very simple (albeit high-order) methods. As demands for credible simulations grow we need to embrace complexity in several directions for progress to be made. modeling and simulation. For the sophisticated and knowledgeable person, the computer is merely a tool, and the real product is the complete and assessed calculation tied to a full V&V pedigree.
modeling and simulation. For the sophisticated and knowledgeable person, the computer is merely a tool, and the real product is the complete and assessed calculation tied to a full V&V pedigree. I’m an unrelenting progressive. This holds true for politics, work and science where I always see a way for things to get better. I’m very uncomfortable with just sitting back and appreciating how things are. Many who I encounter see this as a degree of pessimism since I see the shortcomings in almost everything. I keenly disagree with this assessment. I see my point-of-view as optimism. It is optimism because I know things can always get better, always improve and constantly achieve a better end state. The people who I rub the wrong way are the proponents of the status quo, who see the current state of affairs as just fine. The difference in worldview is really between my deep reaching desires for a better world versus a world that is good enough already. Often the greatest enemy of getting to a better world is a culture that is a key element of the world, as it exists. Change comes whether culture wants it or not, and problems arise when the prevailing culture is unfit for these changes. Overcoming culture is the hardest part of change, and even when the culture is utterly toxic, it opposes changes that would make things better.
I’m an unrelenting progressive. This holds true for politics, work and science where I always see a way for things to get better. I’m very uncomfortable with just sitting back and appreciating how things are. Many who I encounter see this as a degree of pessimism since I see the shortcomings in almost everything. I keenly disagree with this assessment. I see my point-of-view as optimism. It is optimism because I know things can always get better, always improve and constantly achieve a better end state. The people who I rub the wrong way are the proponents of the status quo, who see the current state of affairs as just fine. The difference in worldview is really between my deep reaching desires for a better world versus a world that is good enough already. Often the greatest enemy of getting to a better world is a culture that is a key element of the world, as it exists. Change comes whether culture wants it or not, and problems arise when the prevailing culture is unfit for these changes. Overcoming culture is the hardest part of change, and even when the culture is utterly toxic, it opposes changes that would make things better.


 failed presidency because of the toxic political culture in general. We have reaped this entire legacy by allowing the public and political institutions to whither for decades. It is arguable that this erosion is the willful effort of those charged by the public with governing us. Among the institutions that are under siege and damaged in our current era are the research institutions where I work. These institutions have cultures from a bygone era, completely unfit for the modern world yet unmoving and not evolved in the face of new challenges.
failed presidency because of the toxic political culture in general. We have reaped this entire legacy by allowing the public and political institutions to whither for decades. It is arguable that this erosion is the willful effort of those charged by the public with governing us. Among the institutions that are under siege and damaged in our current era are the research institutions where I work. These institutions have cultures from a bygone era, completely unfit for the modern world yet unmoving and not evolved in the face of new challenges. disempowerment of employees. Increasingly the people working in the trenches are merely cannon fodder, and everything important to work happens with managers. Where I work the toxicity of the workplace and politics collide to produce a double whammy. We are under siege from a political climate that undermines institutions and a business-management culture that undermines the power of the worker.
disempowerment of employees. Increasingly the people working in the trenches are merely cannon fodder, and everything important to work happens with managers. Where I work the toxicity of the workplace and politics collide to produce a double whammy. We are under siege from a political climate that undermines institutions and a business-management culture that undermines the power of the worker. ng the barriers to their actual reality would be a welcome remedy to the normal cynical response. Instead the reality is completely ignored and the fantasy of living to such values is promoted. It is not clear whether the manager knows the promoted values are fiction, or simply exists in a disconnected fantasy world. Either situation is utterly damning. The manager either knows the values are fiction, or they are so disconnected from reality that they believe the fiction. The end result is the same, no actions to remove the toxic culture are ever taken and the culture’s role in undermining values is not acknowledged.
ng the barriers to their actual reality would be a welcome remedy to the normal cynical response. Instead the reality is completely ignored and the fantasy of living to such values is promoted. It is not clear whether the manager knows the promoted values are fiction, or simply exists in a disconnected fantasy world. Either situation is utterly damning. The manager either knows the values are fiction, or they are so disconnected from reality that they believe the fiction. The end result is the same, no actions to remove the toxic culture are ever taken and the culture’s role in undermining values is not acknowledged. es resulting directly from the toxic culture playing out. The election of a thoroughly toxic human being as President is a great exemplar of the degree of dysfunction today. Our toxic culture is spilling over into societal decisions that may have grave implications for our combined future. One outcome of the toxic societal choice could be a sequence of events that will induce a crisis of monumental proportions. Such crises can be useful in fixing problems and destroying the toxic culture, and allowing its replacement by something better. Unfortunately such crises are painful, destructive and expensive. People are killed. Lives are ruined and pain is inflicted broadly. Perhaps this is the cost we must bear in the wake of allowing a toxic culture to fester and grow in our midst.
es resulting directly from the toxic culture playing out. The election of a thoroughly toxic human being as President is a great exemplar of the degree of dysfunction today. Our toxic culture is spilling over into societal decisions that may have grave implications for our combined future. One outcome of the toxic societal choice could be a sequence of events that will induce a crisis of monumental proportions. Such crises can be useful in fixing problems and destroying the toxic culture, and allowing its replacement by something better. Unfortunately such crises are painful, destructive and expensive. People are killed. Lives are ruined and pain is inflicted broadly. Perhaps this is the cost we must bear in the wake of allowing a toxic culture to fester and grow in our midst. t of challenges for older cultures, which these older cultures are unfit to manage. Seemingly we are being plunged headlong toward a crisis necessary to resolve the cultural inadequacies. The problem is that the crisis will be an immensely painful and horrible circumstance. We may simply have no choice, but to go through it, and hope we have the wisdom and strength to get to the other side of the abyss.
t of challenges for older cultures, which these older cultures are unfit to manage. Seemingly we are being plunged headlong toward a crisis necessary to resolve the cultural inadequacies. The problem is that the crisis will be an immensely painful and horrible circumstance. We may simply have no choice, but to go through it, and hope we have the wisdom and strength to get to the other side of the abyss. reatures whose success has been predicated on the toxic culture. These people are almost completely incapable of making the necessary decisions for avoiding the sorts of disasters that characterize a crisis. The toxic culture and those who succeed in them are unfit to resolve crises successfully. Our leaders are the most successful people in the toxic culture and act to defend such cultures in the face of overwhelming evidence that the culture is toxic. As such they do nothing to avoid the crisis even when it is obvious and make the eventual disaster inevitable.
reatures whose success has been predicated on the toxic culture. These people are almost completely incapable of making the necessary decisions for avoiding the sorts of disasters that characterize a crisis. The toxic culture and those who succeed in them are unfit to resolve crises successfully. Our leaders are the most successful people in the toxic culture and act to defend such cultures in the face of overwhelming evidence that the culture is toxic. As such they do nothing to avoid the crisis even when it is obvious and make the eventual disaster inevitable. eries of basic scientific principles combined with overwhelming need in the socio-political worlds. At the end of the 19th century and beginning of the 20th century a massive revolution occurred in physics fundamentally changing our knowledge of the universe. The needs of global conflict pushed us to harness this knowledge to unleash the power of the atom. Ultimately the technology of atomic energy became a transformative political force probably stabilizing the world against massive conflict. More recently, computer technology has seen a similar set of events play out in a transformative way first scientifically, then in engineering and finally in profound societal impact we are just beginning to see unfold.
eries of basic scientific principles combined with overwhelming need in the socio-political worlds. At the end of the 19th century and beginning of the 20th century a massive revolution occurred in physics fundamentally changing our knowledge of the universe. The needs of global conflict pushed us to harness this knowledge to unleash the power of the atom. Ultimately the technology of atomic energy became a transformative political force probably stabilizing the world against massive conflict. More recently, computer technology has seen a similar set of events play out in a transformative way first scientifically, then in engineering and finally in profound societal impact we are just beginning to see unfold. If we pull our focus into the ability of computational power to transform science, we can easily see the failure to recognize these elements in current ideas. We remain utterly tied to the pursuit of Moore’s law even as it lies in the morgue. Rather than examine the needs of progress, we remain tied to the route taken in the past. The focus of work has become ever more computer (machine) directed, and other more important and beneficial activities have withered from lack of attention. In the past I’ve pointed out the greater importance of modeling, methods, and algorithms in comparison to machines. Today we can look at another angle on this, the time it takes to produce useful computational results, or workflow.
If we pull our focus into the ability of computational power to transform science, we can easily see the failure to recognize these elements in current ideas. We remain utterly tied to the pursuit of Moore’s law even as it lies in the morgue. Rather than examine the needs of progress, we remain tied to the route taken in the past. The focus of work has become ever more computer (machine) directed, and other more important and beneficial activities have withered from lack of attention. In the past I’ve pointed out the greater importance of modeling, methods, and algorithms in comparison to machines. Today we can look at another angle on this, the time it takes to produce useful computational results, or workflow. be the simplest and clearest example of the overwhelmingly transparent superficiality of current research. Visualization is useful for marketing science, but produces stunningly little actual science or engineering. We are more interested in funding tools for marketing work than actually doing work. Tools for extracting useful engineering or scientific data from calculation usually languish. They have little “sex appeal” compared to flashy visualization, but carry all the impact on the results that matter. If one is really serious about V&V all of these issues are compounded dramatically. For doing hard-nosed V&V visualization has almost no value whatsoever.
be the simplest and clearest example of the overwhelmingly transparent superficiality of current research. Visualization is useful for marketing science, but produces stunningly little actual science or engineering. We are more interested in funding tools for marketing work than actually doing work. Tools for extracting useful engineering or scientific data from calculation usually languish. They have little “sex appeal” compared to flashy visualization, but carry all the impact on the results that matter. If one is really serious about V&V all of these issues are compounded dramatically. For doing hard-nosed V&V visualization has almost no value whatsoever. Too often in seeing discourse about numerical methods, one gets the impression that dissipation is something to be avoided at all costs. Calculations are constantly under attack for being too dissipative. Rarely does one ever hear about calculations that are not dissipative enough. A reason for this is the tendency for too little dissipation to cause outright instability contrasted with too much dissipation with low-order methods. In between too little dissipation and instability are a wealth of unphysical solutions, oscillations and terrible computational results. These results may be all too common because of people’s standard disposition toward dissipation. The problem is that too few among the computational cognoscenti recognize that too little dissipation is as poisonous to results as too much (maybe more).
Too often in seeing discourse about numerical methods, one gets the impression that dissipation is something to be avoided at all costs. Calculations are constantly under attack for being too dissipative. Rarely does one ever hear about calculations that are not dissipative enough. A reason for this is the tendency for too little dissipation to cause outright instability contrasted with too much dissipation with low-order methods. In between too little dissipation and instability are a wealth of unphysical solutions, oscillations and terrible computational results. These results may be all too common because of people’s standard disposition toward dissipation. The problem is that too few among the computational cognoscenti recognize that too little dissipation is as poisonous to results as too much (maybe more). . Implicit in the thinking about the satisfaction of the entropy inequality is a view that approaching the limit of $latex d S / d t = 0$ as viscosity becomes negligible (i.e., inviscid) is desirable. This is
. Implicit in the thinking about the satisfaction of the entropy inequality is a view that approaching the limit of $latex d S / d t = 0$ as viscosity becomes negligible (i.e., inviscid) is desirable. This is a grave error in thinking about the physical laws of direct interest, as the solution of conservation laws does not satisfy this limit when flows are inviscid. Instead the solutions of interest (i.e., weak solutions with discontinuities) in the inviscid limit approach a solution where the entropy production is proportional to variation in the large scale solution cubed,
a grave error in thinking about the physical laws of direct interest, as the solution of conservation laws does not satisfy this limit when flows are inviscid. Instead the solutions of interest (i.e., weak solutions with discontinuities) in the inviscid limit approach a solution where the entropy production is proportional to variation in the large scale solution cubed,  . This scaling appears over and over in the solution of conservation laws including Burgers’ equation, the equations of compressible flow, MHD, and incompressible turbulence (Margolin & Rider, 2001). The seeming universality of these relations and their implications for numerical methods are discussed below in more detail, but follow the profound implications turbulence modelling are explored in detail for implicit LES modelling (our book edited by Grinstein, Margolin & Rider, 2007). Valid solutions will invariably produce the inequality, but the route to achievement varies greatly.
. This scaling appears over and over in the solution of conservation laws including Burgers’ equation, the equations of compressible flow, MHD, and incompressible turbulence (Margolin & Rider, 2001). The seeming universality of these relations and their implications for numerical methods are discussed below in more detail, but follow the profound implications turbulence modelling are explored in detail for implicit LES modelling (our book edited by Grinstein, Margolin & Rider, 2007). Valid solutions will invariably produce the inequality, but the route to achievement varies greatly. , which integrates to replicate inviscid dissipation as a residual term in the “energy” equation,
, which integrates to replicate inviscid dissipation as a residual term in the “energy” equation,  . This term comes directly from being in conservation form and disappears when the approximation is in non-conservative from. In large part the overly large success of these second-order methods is related to this character.
. This term comes directly from being in conservation form and disappears when the approximation is in non-conservative from. In large part the overly large success of these second-order methods is related to this character. s in the flow, the characteristic speed is a function of the solution, which induces a set of entropy considerations. The simplest and most elegant condition is due to Lax, which says that the characteristics dictate that information flows into a shock. In a Lagrangian frame of reference for a right running shock this would look like,
s in the flow, the characteristic speed is a function of the solution, which induces a set of entropy considerations. The simplest and most elegant condition is due to Lax, which says that the characteristics dictate that information flows into a shock. In a Lagrangian frame of reference for a right running shock this would look like,  with
with  being the sound speed. It has a less clear, but equivalent form through a nonlinear sound speed,
being the sound speed. It has a less clear, but equivalent form through a nonlinear sound speed,  . The differential term describes the fundamental derivative, which describes the nonlinear response of the sound speed to the solution itself. This same condition can be seen in a differential form and dictates some essential sign conventions in flows. The key is that these conditions have a degree of equivalence. The beauty is that the differential form lacks the simplicity of Lax’s condition, but establishes a clear connection to artificial viscosity.
. The differential term describes the fundamental derivative, which describes the nonlinear response of the sound speed to the solution itself. This same condition can be seen in a differential form and dictates some essential sign conventions in flows. The key is that these conditions have a degree of equivalence. The beauty is that the differential form lacks the simplicity of Lax’s condition, but establishes a clear connection to artificial viscosity.