
The beginning of wisdom is the definition of terms.
― Socrates
Accuracy, Fidelity, Resolution and Stability, Robustness, Reliability
These six words matter a lot in the discussion of numerical methods yet their meanings are quite poorly understood or even regularly conflict. Even worse they are poorly articulated in the literature despite their prominent importance in the character of numerical methods and their instantiation in code. Maybe I can make some progress toward rectifying this issue here. Consider this post to be a follow-on and compliment to the earlier post on improving CFD codes, https://williamjrider.wordpress.com/2015/07/10/cfd-codes-should-improve-but-wont-why/.
 One of the biggest issues in providing clarity in these matters is the ultimate inability of classical mathematics to provide clear guidance as we move from the abstract and ideal world to the real and messy reality. In using methods to solve problems with a lot of reality things that work well or even optimally in an idealized version of the World fall apart. In the ideal World very high-order approximations are wonderful, powerful and efficient. Reality tears this apart and all of these characteristics change to problematic, fragile and expensive. The failure to bridge methods over to the real world undermines progress and strands innovation behind.
One of the biggest issues in providing clarity in these matters is the ultimate inability of classical mathematics to provide clear guidance as we move from the abstract and ideal world to the real and messy reality. In using methods to solve problems with a lot of reality things that work well or even optimally in an idealized version of the World fall apart. In the ideal World very high-order approximations are wonderful, powerful and efficient. Reality tears this apart and all of these characteristics change to problematic, fragile and expensive. The failure to bridge methods over to the real world undermines progress and strands innovation behind.
Accuracy is a simple thing to define, the deviation of an approximation from reality. For an idealized mathematical representation this measurement is “easy”. The problem is measuring this for any real world circumstance is quite difficult to impossible. One way to define accuracy is related to the asymptotic rate of convergence as the degree of approximation is changed this is “order-of-accuracy”. The connection of order of accuracy, and numerical precision is rather ill defined and fuzzy. Moreover reality makes this even harder.
A clear way that the World becomes real is shock waves (and other similar nonlinear structures). A shock wave or similarly discontinuous solution renders most numerical methods first-order accurate at best. The current knowledge about how formal ideal high-order accuracy connects to measurable accuracy in the presence of discontinuities is sketchy. This manifests itself in having research in methods focus on high-order accuracy without any understanding of how this would translate to accuracy for real World problems. Today the efficacy of high-order methods is merely an article of faith.
We have alternative definitions of accuracy focus on the terms fidelity and resolution. Both of these terms are even more fuzzy that accuracy. These both get applied to methods that provide their value to (more) real World circumstances where formal accuracy is diminished. Thus important classes of methods are defined as “high-fidelity” or “high-resolution”. Both of these definitions are used to imply capability to provide good solutions when the ugliness of reality intrudes into our idealized reality.
 Peter Lax provided a definition of resolution in an unfortunately obscure source. There and in a fascinating interview with Lax by Phil Colella (http://history.siam.org/oralhistories/lax.htm) the concept was discussed with an astounding proposition, perhaps higher than second-order was too accurate and produced solutions that did not have enough “room” to capture true solutions. It is not a final answer, but it does yield a direction to thinking about such things.
Peter Lax provided a definition of resolution in an unfortunately obscure source. There and in a fascinating interview with Lax by Phil Colella (http://history.siam.org/oralhistories/lax.htm) the concept was discussed with an astounding proposition, perhaps higher than second-order was too accurate and produced solutions that did not have enough “room” to capture true solutions. It is not a final answer, but it does yield a direction to thinking about such things.
Here is the key passage on the topic of resolution:
“COLELLA: So you have shocks, why second-order? What were you thinking?
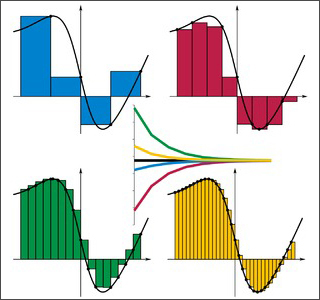
LAX: Well, you want greater accuracy, but even more you want greater resolution. I defined a concept of resolution. If you take a difference method and you consider a set of initial value problems of interest, which in practice could be some ball in L1-space, anything will do, and then you look at the states into which it develops after the unit-time, any given time, that’s another set. The first surprise is that this set is much smaller for nonlinear…for linear equations where time is reversible, the size of this set is roughly the same as the original set. For nonlinear equations, which are not reversible and where the wave information is actually destroyed, it’s a much smaller set. And the measure of the set that is relevant is what’s called entropy or capacity with respect to some given scale delta. So the first thing to look at is what is the capacity or entropy of this set of exact solutions. Then you take a numerical method, you start, you discretize the same set of initial data, then you look at what you get after time t goes to whatever the test time was. A method has a proper resolving power if the size of this set is comparable to the size of the exact solution; if it’s very much smaller it clearly cannot resolve. And first-order methods have resolution that is too low, and many details are just washed out. Second-order methods have better resolution. In fact, I was trying to – well, I want to bring up the question: could it be that methods that are even higher order (third, fourth) have perhaps too much resolution, more resolution than is needed? I just bring this up as a question.”
I might offer a bit of support for that concept in the case of genuinely nonlinear problems below. In a nutshell, the second-order methods with conservation form provide truncation error that matches important aspects of the true physics. Higher order methods will not capture this aspect of the physics. I’ll also note that Len Margolin and I have followed a similar, but different line of thinking looking at implicit large eddy simulation (ILES). ILES is an observation that high-resolution methods appear to provide effective turbulence modeling without the benefit of explicitly added subgrid modeling.
So let’s talk about the archetype of nonlinear, real World, messy computations, shock waves. In some ways shocks are really nice, they are inherently dissipative even in the case where the system is free of explicit molecular viscosity. Dissipation in the limit of zero viscosity is one of the most profound aspects of our mathematical description of reality. For physical systems with a quadratic nonlinearity including shocks and turbulence, this dissipation scales, 


 This form of nonlinear dissipation comes directly from the application of the conservation form to methods with second-order accuracy. For energy this term is precisely the form of the asymptotic law except for its connection to the discrete system. If the method achieves a formally higher than second-order accuracy this term disappears. For very simple second-order schemes there are truncation errors that compete with this fortuitous term, but if the linear accuracy of the method is higher order, this term is the leading and dominant truncation error. This may explain why schemes like PPM, and FCT methods produce high quality turbulence simulations without explicit modeling, but methods like minmod or WENO do not. The minmod scheme has a nonlinear truncation error that dominates the control volume term. For WENO method the higher order accuracy means the dissipation is dominated by a combination hyperviscous terms.
This form of nonlinear dissipation comes directly from the application of the conservation form to methods with second-order accuracy. For energy this term is precisely the form of the asymptotic law except for its connection to the discrete system. If the method achieves a formally higher than second-order accuracy this term disappears. For very simple second-order schemes there are truncation errors that compete with this fortuitous term, but if the linear accuracy of the method is higher order, this term is the leading and dominant truncation error. This may explain why schemes like PPM, and FCT methods produce high quality turbulence simulations without explicit modeling, but methods like minmod or WENO do not. The minmod scheme has a nonlinear truncation error that dominates the control volume term. For WENO method the higher order accuracy means the dissipation is dominated by a combination hyperviscous terms.
These deep philosophical implications are ignored by the literature for the most part, with shocks and turbulence defining a separation of focus. The connections between these topics are diffuse and unfocused. A direct connection would be a stunning breakthrough, but entrenched interests in both areas conspire against this. This remarkable similarity of the limiting dissipation in the absence of viscosity have been systematically ignored by scientists. I see it as utterly compelling or simply brutally obvious for a quadratic nonlinearity. Either way the similarity is meaningful. One of the key problems is that turbulence is almost completely grounded in the belief that it can be completely described by incompressible flow. No one seems to ever question this assumption.
Incompressibility is a physically limited approximation of reality, but not reality. It renders the equations to be intractable in some ways (see the Clay prize for proving the existence of solutions!). The unphysical nature of the equations is two-fold: sound speeds are infinite and thermodynamics are removed (especially harmful is the loss of the second law). Perhaps more problematically is the loss of the very nonlinearity known to be the source of dissipation without viscosity for shock waves, that is the steepening of arbitrary disturbances into discontinuous shock waves.
I’ve written before about stability and robustness with a focus on the commonality of their definition https://williamjrider.wordpress.com/2014/12/03/robustness-is-stability-stability-is-robustness-almost/. The default basic methodology for stability analysis was discussed too https://williamjrider.wordpress.com/2014/07/15/conducting-von-neumann-stability-analysis/. If we add the term “reliable” the situation is quite analogous to the issues with accuracy. We ultimately don’t have the right technical definitions for the useful character of practical reliability and robustness of numerical methods and their executable instantiation in code. Stability is necessary for robustness and reliable, but robustness and reliable imply even more. Typically the concept of robustness applies to practical computational methods used for real World (i.e., messy) problems.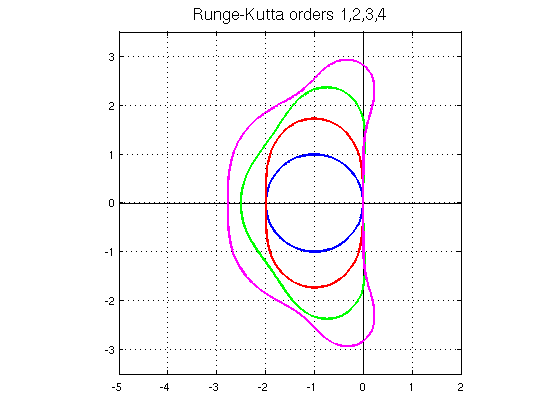
The key issue for high order methods is the inherently non-smoothness and lack of clean structure in the real world. This messiness renders high-order methods of questionable utility. Showing that high-order methods improve real world, practical, pragmatic calculation is challenge for the research community working in this area. Generally high-order methods show a benefit, but at a cost that makes their viability in production software questionable. In addition the high-order methods tend to be more fragile than their lower order cousins. The two questions of robustness in use and efficiency are the keys to progress.
Given all of these considerations, what is a path forward to improving existing production codes with higher order methods?
I will close with a set of proposals on how we might see our way clear to improving methods in codes by balancing requirements for high-order accuracy, high-resolution, robustness and stability. The goal is to improve the solution of “real” “practical” problems, not idealized problems associated with publishing research papers.
- For practical accuracy high-order only matters for linear modes in the problem. Therefore seek high-order only for the leading order terms in the expansion. Full nonlinear accuracy is a waste of effort. Full nonlinear accuracy only matters if the flow is fully resolved and the fields contain the level of smoothness equal to the scheme (they never do!). This would allow the quadratures usually invoked by formally high-order methods could be reduced along with the costs.
- For nonlinear structures, you just need second-order accuracy, which gives you a truncation error that matches the asymptotic structure of dissipation analytically. Removing this term may actually harm the solution rather than improve. The reasoning follows Lax’s comments above.
- Nonlinear stability is more important than linear stability in fact nonlinear stability will allow you to use methods that are locally linearly unstable. Extending useful nonlinear stability beyond monotonicity is one of the keys to improving codes.
- Developing nonlinear stability principles beyond monotonicity preservation is one of the keys to progress. A test of a good principle is its ability to allow the use of linearly unstable methods without catastrophe. The principle should not create too much dissipation outside of shocked regions (this is why ENO and WENO are not good enough principles). In a key way monotonicity-preserving methods naturally extended the linear monotone and first order methods. The next step beyond monotonicity preservation has not built upon this foundation, but rather introduced an entirely different concept. A more hierarchical approach may be needed to achieve something of more practical utility.
- The option of fully degrading the accuracy of the method to first-order accuracy must always be in play. This step is the key to robustness. Methods that do not allow this to happen will never be robust enough for production work. This is another reason why ENO and WENO don’t work for production codes.
Logically, all things are created by a combination of simpler less capable components
– Scott Adams (or the Dogbert Principle that applies to high resolution schemes in Laney, Culbert B. Computational gasdynamics. Cambridge University Press, 1998).
References
Lax, Peter D. “Accuracy and resolution in the computation of solutions of linear and nonlinear equations.” Selected Papers Volume I (2005): 184-194.
Margolin, Len G., and William J. Rider. “A rationale for implicit turbulence modelling.” International Journal for Numerical Methods in Fluids 39.9 (2002): 821-841.
Grinstein, Fernando F., Len G. Margolin, and William J. Rider, eds. Implicit large eddy simulation: computing turbulent fluid dynamics. Cambridge university press, 2007.
Rider, William J., Jeffrey A. Greenough, and James R. Kamm. “Accurate monotonicity-and extrema-preserving methods through adaptive nonlinear hybridizations.” Journal of Computational Physics 225.2 (2007): 1827-1848.
Broadwell, James E. “Shocks and energy dissipation in inviscid fluids: a question posed by Lord Rayleigh.” Journal of Fluid Mechanics 347 (1997): 375-380.
Bethe, Hans Albrecht. Report on” The Theory of Shock Waves for an Arbitrary Equation of State”… 1942.












 wheelhouse (along with all the hijinks that the child movie viewers will enjoy).
wheelhouse (along with all the hijinks that the child movie viewers will enjoy).



 methods in CFD codes. Methods that were introduced at that time remain at the core of CFD codes today. The reason was the development of new methods that were so unambiguously better than the previous alternatives that the change was a fait accompli. Codes produced results with the new methods that were impossible to achieve with previous methods. At that time a broad and important class of physical problems in fluid dynamics were suddenly open to successful simulation. Simulation results were more realistic and physically appealing and the artificial and unphysical results of the past were no longer a limitation.
methods in CFD codes. Methods that were introduced at that time remain at the core of CFD codes today. The reason was the development of new methods that were so unambiguously better than the previous alternatives that the change was a fait accompli. Codes produced results with the new methods that were impossible to achieve with previous methods. At that time a broad and important class of physical problems in fluid dynamics were suddenly open to successful simulation. Simulation results were more realistic and physically appealing and the artificial and unphysical results of the past were no longer a limitation. 
 virtually any conceivable standard. In addition, the new methods were not either overly complex or expensive to use. The principles associated with their approach to solving the equations combined the best, most appealing aspects of previous methods in a novel fashion. They became the standard method almost overnight.
virtually any conceivable standard. In addition, the new methods were not either overly complex or expensive to use. The principles associated with their approach to solving the equations combined the best, most appealing aspects of previous methods in a novel fashion. They became the standard method almost overnight. This was accomplished because the methods were nonlinear even for linear equations meaning that the domain of dependence for the approximation is a function of the solution itself. Earlier methods were linear meaning that the approximation was the same without regard for the solution. Before the high-resolution methods you had two choices either a low-order method that would wash out the solution, or a high-order solution that would have unphysical solutions. Theoretically the low-order solution is superior in a sense because the solution could be guaranteed to be physical. This happened because the solution was found using a great deal of numerical or artificial viscosity. The solutions were effectively laminar (meaning viscously dominated) thus not having energetic structures that make fluid dynamics so exciting, useful and beautiful.
This was accomplished because the methods were nonlinear even for linear equations meaning that the domain of dependence for the approximation is a function of the solution itself. Earlier methods were linear meaning that the approximation was the same without regard for the solution. Before the high-resolution methods you had two choices either a low-order method that would wash out the solution, or a high-order solution that would have unphysical solutions. Theoretically the low-order solution is superior in a sense because the solution could be guaranteed to be physical. This happened because the solution was found using a great deal of numerical or artificial viscosity. The solutions were effectively laminar (meaning viscously dominated) thus not having energetic structures that make fluid dynamics so exciting, useful and beautiful. safe to do so), and only use the lower accuracy, dissipative method when absolutely necessary. Making these choices on the fly is the core of the magic of these methods. The new methods alleviated the bulk of this viscosity, but did not entirely remove it. This is good and important because some viscosity in the solution is essential to connect the results to the real world. Real world flows all have some amount of viscous dissipation. This fact is essential for success in computing shock waves where having dissipation allows the selection of the correct solution.
safe to do so), and only use the lower accuracy, dissipative method when absolutely necessary. Making these choices on the fly is the core of the magic of these methods. The new methods alleviated the bulk of this viscosity, but did not entirely remove it. This is good and important because some viscosity in the solution is essential to connect the results to the real world. Real world flows all have some amount of viscous dissipation. This fact is essential for success in computing shock waves where having dissipation allows the selection of the correct solution. In the case of simple hyperbolic conservation laws that define the inertial part of fluid dynamics, the low order accuracy methods solve an equation with classical viscous terms that match those seen in reality although generally the magnitude of viscosity is much larger than the real world. Thus these methods produce laminar (syrupy) flows as a matter of course. This makes these methods unsuitable for simulating most conditions of interest to engineering and science. It also makes these methods very safe to use and virtually guarantee a physically reasonable (if inaccurate) solution.
In the case of simple hyperbolic conservation laws that define the inertial part of fluid dynamics, the low order accuracy methods solve an equation with classical viscous terms that match those seen in reality although generally the magnitude of viscosity is much larger than the real world. Thus these methods produce laminar (syrupy) flows as a matter of course. This makes these methods unsuitable for simulating most conditions of interest to engineering and science. It also makes these methods very safe to use and virtually guarantee a physically reasonable (if inaccurate) solution. The new methods get rid of these large viscous terms and replace it with a smaller viscosity that depends on the structure of the solution. The results with the new methods are stunningly different and produce the sort of rich nonlinear structures found in nature (or something closely related). Suddenly codes produced solutions that matched reality far more closely. It was a night and day difference in method performance, once you tried the new methods there was no going back.
The new methods get rid of these large viscous terms and replace it with a smaller viscosity that depends on the structure of the solution. The results with the new methods are stunningly different and produce the sort of rich nonlinear structures found in nature (or something closely related). Suddenly codes produced solutions that matched reality far more closely. It was a night and day difference in method performance, once you tried the new methods there was no going back.









 The publisher is the American Mathematical Society (AMS) and the book is a wonderfully technical and personal account of the fascinating and influential life of Peter Lax. Hersh’s account goes far beyond the obvious public and professional impact of Lax into his personal life and family although these are colored greatly by the greatest events of the 20th Century. Lax also has a deep connection to three themes in my own life: scientific computing, hyperbolic conservation laws and Los Alamos. He was a contributing member of the Manhattan Project despite being a corporal in the US Army and only 18 years old! Los Alamos and John von Neumann in particular had an immense influence on his life’s work with the fingerprints of that influence all over his greatest professional achievements.
The publisher is the American Mathematical Society (AMS) and the book is a wonderfully technical and personal account of the fascinating and influential life of Peter Lax. Hersh’s account goes far beyond the obvious public and professional impact of Lax into his personal life and family although these are colored greatly by the greatest events of the 20th Century. Lax also has a deep connection to three themes in my own life: scientific computing, hyperbolic conservation laws and Los Alamos. He was a contributing member of the Manhattan Project despite being a corporal in the US Army and only 18 years old! Los Alamos and John von Neumann in particular had an immense influence on his life’s work with the fingerprints of that influence all over his greatest professional achievements.

















 me ten years ago, I’d have thought aliens delivered the technology to humans.
me ten years ago, I’d have thought aliens delivered the technology to humans.
 In a sense the modern trajectory of supercomputing is quintessentially American, bigger and faster is better by fiat. Excess and waste are virtues rather than flaw. Except the modern supercomputer it is not better, and not just because they don’t hold a candle to the old Crays. These computers just suck in so many ways; they are soulless and devoid of character. Moreover they are already a massive pain in the ass to use, and plans are afoot to make them even worse. The unrelenting priority of speed over utility is crushing. Terrible is the only path to speed, and terrible is coming with a tremendous cost too. When a colleague recently quipped that she would like to see us get a computer we actually wanted to use, I’m convinced that she had the older generation of Crays firmly in mind.
In a sense the modern trajectory of supercomputing is quintessentially American, bigger and faster is better by fiat. Excess and waste are virtues rather than flaw. Except the modern supercomputer it is not better, and not just because they don’t hold a candle to the old Crays. These computers just suck in so many ways; they are soulless and devoid of character. Moreover they are already a massive pain in the ass to use, and plans are afoot to make them even worse. The unrelenting priority of speed over utility is crushing. Terrible is the only path to speed, and terrible is coming with a tremendous cost too. When a colleague recently quipped that she would like to see us get a computer we actually wanted to use, I’m convinced that she had the older generation of Crays firmly in mind. We have to go back to the mid-1990’s and the combination of computing and geopolitical issues that existed then. The path taken by the classic Cray supercomputers appeared to be running out of steam insofar as improving performance. The attack of the killer micros was defined as the path to continued growth in performance. Overall hardware functionality was effectively abandoned in favor of pure performance. The pure performance was only achieved in the case of benchmark problems that had little in common with actual applications. Performance on real application took a nosedive; a nosedive that the benchmark conveniently covered up. We still haven’t woken up to the reality.
We have to go back to the mid-1990’s and the combination of computing and geopolitical issues that existed then. The path taken by the classic Cray supercomputers appeared to be running out of steam insofar as improving performance. The attack of the killer micros was defined as the path to continued growth in performance. Overall hardware functionality was effectively abandoned in favor of pure performance. The pure performance was only achieved in the case of benchmark problems that had little in common with actual applications. Performance on real application took a nosedive; a nosedive that the benchmark conveniently covered up. We still haven’t woken up to the reality.

 In the past forty some odd years we have as a society lost the ability to take risks even when the opportunity available is huge. The consequence of failure has become greater than the opportunity for success. In computing this trend has been powered by Moore’s law, the exponential growth in computing power over the course of the last 50 years (its not a law, just an observation). Under Moore’s law you just have to let time pass and computer performance will grow. It is a low-risk path to success.
In the past forty some odd years we have as a society lost the ability to take risks even when the opportunity available is huge. The consequence of failure has become greater than the opportunity for success. In computing this trend has been powered by Moore’s law, the exponential growth in computing power over the course of the last 50 years (its not a law, just an observation). Under Moore’s law you just have to let time pass and computer performance will grow. It is a low-risk path to success. are also prone to failures where ideas simply don’t pan out. Without the failure you don’t have the breakthroughs hence the fatal nature of risk aversion. Integrated over decades of timid low-risk behavior we have the makings of a crisis. Our low-risk behavior has already created a fast immeasurable gulf in what we can do today versus what we should be doing today.
are also prone to failures where ideas simply don’t pan out. Without the failure you don’t have the breakthroughs hence the fatal nature of risk aversion. Integrated over decades of timid low-risk behavior we have the makings of a crisis. Our low-risk behavior has already created a fast immeasurable gulf in what we can do today versus what we should be doing today.
 come a new battleground for national supremacy. The United States will very likely soon commit to a new program for achieving progress in computing. This program by all accounts will be focused primarily on the computing hardware first, and then the system software that directly connects to this hardware. The goal will be the creation of a new generation of supercomputers that attempt to continue the growth of computing power into the next decade, and provide a path to “exascale”. I think it is past time to ask, “do we have the right priorities?” “Is this goal important and worthy of achieving?”
come a new battleground for national supremacy. The United States will very likely soon commit to a new program for achieving progress in computing. This program by all accounts will be focused primarily on the computing hardware first, and then the system software that directly connects to this hardware. The goal will be the creation of a new generation of supercomputers that attempt to continue the growth of computing power into the next decade, and provide a path to “exascale”. I think it is past time to ask, “do we have the right priorities?” “Is this goal important and worthy of achieving?” I’ll return to these two questions at the end, but first I’d like to touch on an essential concept in high performance computing, scaling. Scaling is a big deal, it measures success in computing, in a nutshell describes efficiency of solving problems particular with respect to changing problem size or computing resource. In scientific computing one of the primary assumptions is that bigger faster computers yield better, more accurate results that have greater relevance to the real world. The success of computing depends on scaling and breakthroughs in achieving it, defines the sort of problems that could be solved.
I’ll return to these two questions at the end, but first I’d like to touch on an essential concept in high performance computing, scaling. Scaling is a big deal, it measures success in computing, in a nutshell describes efficiency of solving problems particular with respect to changing problem size or computing resource. In scientific computing one of the primary assumptions is that bigger faster computers yield better, more accurate results that have greater relevance to the real world. The success of computing depends on scaling and breakthroughs in achieving it, defines the sort of problems that could be solved. veral types of scaling with distinctly different character. Lately the dominant scaling in computing has been associated with parallel computing performance. Originally the focus was on strong scaling, which is defined by the ability of greater computing resources to solve a problem of fixed size faster. In other words perfect strong scaling would result from solving a problem twice as fast with two CPUs than with one CPU.
veral types of scaling with distinctly different character. Lately the dominant scaling in computing has been associated with parallel computing performance. Originally the focus was on strong scaling, which is defined by the ability of greater computing resources to solve a problem of fixed size faster. In other words perfect strong scaling would result from solving a problem twice as fast with two CPUs than with one CPU.
 items long, it takes order
items long, it takes order  . Other high-grade algorithms like quicksort take order
. Other high-grade algorithms like quicksort take order  , but may carry a smaller constant. These can be faster for shorter lists. If one chooses very poorly the sorting can scale like
, but may carry a smaller constant. These can be faster for shorter lists. If one chooses very poorly the sorting can scale like  . There are also
. There are also aspects of the algorithm and it’s scaling that speak to the memory-storage needed and the complexity of the algorithm’s implementation. These themes carry on to a discussion of more esoteric computational science algorithms next.
aspects of the algorithm and it’s scaling that speak to the memory-storage needed and the complexity of the algorithm’s implementation. These themes carry on to a discussion of more esoteric computational science algorithms next.
 where
where  is the number of equations to be solved. This method is designed to solve a dense matrix where there are few non-zero entries. In scientific computing the matrices are typically “sparse” meaning most entries are zero. An algorithm specifically for sparse matrices lowers the scaling to
is the number of equations to be solved. This method is designed to solve a dense matrix where there are few non-zero entries. In scientific computing the matrices are typically “sparse” meaning most entries are zero. An algorithm specifically for sparse matrices lowers the scaling to 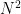 . These methods both produce “exact” solutions to the system (modulo poorly conditioned problems).
. These methods both produce “exact” solutions to the system (modulo poorly conditioned problems).
 g, and the constant gets larger as scaling gets better. Nonetheless it is easy to see that if you’re solving a billion unknowns the difference between
g, and the constant gets larger as scaling gets better. Nonetheless it is easy to see that if you’re solving a billion unknowns the difference between 
 . If one is interested in time-dependent problems, the number of time steps is usually proportional to
. If one is interested in time-dependent problems, the number of time steps is usually proportional to  degrees of freedom. For equivalent accuracy the high-order method would require
degrees of freedom. For equivalent accuracy the high-order method would require  cells and one-fourth of the degrees of freedom. It breaks even at four times the cost. In three dimensional time dependent problems, the scaling is
cells and one-fourth of the degrees of freedom. It breaks even at four times the cost. In three dimensional time dependent problems, the scaling is  and the break-even point is 16 in cost. This is imminently doable. Even larger improvements in accuracy would provide an even more insurmountable advantage.
and the break-even point is 16 in cost. This is imminently doable. Even larger improvements in accuracy would provide an even more insurmountable advantage. The counter-point to these methods is their computational cost and complexity. The second issue is their fragility, which can be recast as their robustness or stability in the face of real problems. Still their performance gains are sufficient to amortize the costs given the vast magnitude of the accuracy gains and effective scaling.
The counter-point to these methods is their computational cost and complexity. The second issue is their fragility, which can be recast as their robustness or stability in the face of real problems. Still their performance gains are sufficient to amortize the costs given the vast magnitude of the accuracy gains and effective scaling. The last issue to touch upon is the need to make algorithms robust, which is just another word for stable. Work on stability of algorithms is simply not happening these days. Part of the consequence is a lack of progress. For example one way to view the lack of ability of multigrid to dominate numerical linear algebra is its lack of robustness (stability). The same thing holds for high-order discretizations, which are typically not as robust or stable as low order ones. As a result low-order methods dominate scientific computing. For algorithms to prosper work on stability and robustness needs to be part of the recipe.
The last issue to touch upon is the need to make algorithms robust, which is just another word for stable. Work on stability of algorithms is simply not happening these days. Part of the consequence is a lack of progress. For example one way to view the lack of ability of multigrid to dominate numerical linear algebra is its lack of robustness (stability). The same thing holds for high-order discretizations, which are typically not as robust or stable as low order ones. As a result low-order methods dominate scientific computing. For algorithms to prosper work on stability and robustness needs to be part of the recipe. urrent program is so intellectually bankrupt as to be comical, and reflects a starkly superficial thinking that ignores the sort of facts staring them directly in the face such as the evidence of commercial computing. Computing matters because of how it impacts the real world we live it. This means the applications of computing matter most of all. In the approach to computing taken today the applications are taken completely for granted, and reality is a mere afterthought.
urrent program is so intellectually bankrupt as to be comical, and reflects a starkly superficial thinking that ignores the sort of facts staring them directly in the face such as the evidence of commercial computing. Computing matters because of how it impacts the real world we live it. This means the applications of computing matter most of all. In the approach to computing taken today the applications are taken completely for granted, and reality is a mere afterthought.