
I spent the week at a relatively massive conference (3000 attendees) in Barcelona Spain, the World Congress on Computational Mechanics. The meeting was large enough that I was constantly missing talks that I wanted to see because other talks were even more interesting. Originally I wanted to give four talks, but the organizers allowed only one so I was attending more talks and giving far less. Nonetheless such meetings are great opportunities to learn about what is going on around the World, get lots of new ideas, meet old friends and make new ones. It is exactly what I wrote about a few weeks ago, giving a talk is second, third or even fourth on the list of reasons to attend such a meeting.
are great opportunities to learn about what is going on around the World, get lots of new ideas, meet old friends and make new ones. It is exactly what I wrote about a few weeks ago, giving a talk is second, third or even fourth on the list of reasons to attend such a meeting.
The span and scope of the Congress is truly impressive. Computational modeling has become a pervasive aspect of modern science and engineering. The array of application is vast and impressively international in flavor. While all of this is impressive, such venues offer an opportunity to take stock of where I am, and where the United States and the rest of the World stand. All of this provides a tremendously valuable opportunity to gain much needed perspective.
An honest assessment is complex. On the one hand, the basic technical and scientific progress is immense, on the other hand there are concerns lurking around every corner. While the United States probably remain in a preeminent state for computational science and engineering, the case against this is getting stronger every day. Europe and Asia are catching up quickly if not having overtaken the USA in many subfields. Across the board there are signs of problems and stagnation in the field. It would seem clear that people know this and it isn’t clear whether there is any action to address problems. Among these issues is the increased use of a narrow set of software tools either commercial or open source computational tools with a requisite lack of knowledge and expertise in the core methods and algorithms used inside them. In addition, the nature of professional education and the state of professionalism is under assault by societal forces,
 Despite the massive size of the meeting there are substantial signs that support for research in the field is declining in size and changing in character. It was extremely difficult to see “big” things happening in the field. The question is whether this is the sign of a mature field where slow progress is happening, or the broad lack of support for truly game-changing work. It could also be a sign that the creative energy in science has moved to other areas that are “hotter” such biology, medicine, materials, … There was a notable lack of exciting keynote lectures at the meeting. There didn’t seem to be any “buzz” with any of them. This was perhaps the single most disappointing aspect of the conference.
Despite the massive size of the meeting there are substantial signs that support for research in the field is declining in size and changing in character. It was extremely difficult to see “big” things happening in the field. The question is whether this is the sign of a mature field where slow progress is happening, or the broad lack of support for truly game-changing work. It could also be a sign that the creative energy in science has moved to other areas that are “hotter” such biology, medicine, materials, … There was a notable lack of exciting keynote lectures at the meeting. There didn’t seem to be any “buzz” with any of them. This was perhaps the single most disappointing aspect of the conference.
A couple of things are clear in the United States and Europe the research environment is in crisis under assault from short-term thinking, funding shortfalls (after making funding the end-all and be-all), and educational malaise. For example, I was horrified that Europeans are looking to the USA for guidance on improving their education. This comes on top of my increasing concern about the nature of professional development at the sort of Labs where I work, and the general lack of educational vitality at universities. More and more it is clear that the chief measure of academic success for professors in monetary. The claims of research quality are measured in dollars and the publish or perish mentality that has ravaged the scientific literature. It is a system in dire need of focused reform and should not be the blueprint for anything but failure. The monetary drive comes from the lack of support that education is receiving from the government, which has driven tuition higher at a stunning pace. At the same time the monetary objective of research funding is hollowing out the educational focus universities should possess. The research itself has a short-term focus, and the lack of emphasis or priority for developing people be they students or professionals shares the short sighted outcome. We are draining our system of the vital engine of innovation that has been the key to our recent economic successes.
Another clear trend that resonates with my attendance at the SIAM annual meeting a few weeks ago is the increasing divide between applied mathematic (or theoretical mechanics) and applications. The disparity in focus between the theoretically minded scientists and the application-focused scientist-engineer is growing to the detriment of the community. The application side of things is increasingly using commercial codes that tend to reflect a deep stagnation in capability (aside from the user interface). The theoretical side is focused on idealized problems stripped of real features that complicate the results making for lots of results that no one on the applied side cares about or can use. The divide is only growing with fewer and fewer reaching across the chasm to connect theory to application.
The push from applications has in the past spurred the theoretical side to advance by attacking more difficult problems. Those days appear to be gone. I might blame the prevalence of the sort of short-term thinking investing other areas for this. Both sides of this divide seem to be driven to take few chances and place their efforts into the safe and sure category of work. The theoretical side is working on problems where results can surely be produced (with the requisite publications). By the same token the applied side uses tried and true methods to get some results without having to wait or hope for a breakthrough. The result is a deep sense of abandonment of progress on many fronts.
The increasing dominance of a small number of codes either commercial or open source would be another deep concern. Part of the problem is a reality (or perception) of extensive costs associated with the development of software. People choose to use these off-the-shelf systems because they cannot afford to build their own. On the other hand, by making these choices they and their students or staff are denied the hands on knowledge of the methodology that leads to deep expertise. This is all part of this short-term focus that is bleeding the entire community of deep expertise development necessary for excellence. The same attitudes and approach happen at large laboratories that should seemingly not have the sort of financial and time pressures operating in academia. This whole issue is exacerbated by the theoretical versus applied divide. So far we haven’t made scientific and engineering software modular or componentized. Further the leading edge efforts with “modules” often are so divorced from real problems that they can’t really be relied upon for hard-core applications. Again we have problems with adapting to the modern world confounded with the short-term focus, and success measures that do not measure success.
Perhaps what I’m seeing is a veritable mid-life crisis. The field of computational science and engineering has become mature. It is remarkably broad and making inroads into new areas and considered a full partner with traditional activities in most high-tech industries. At the same time there is a stunning lack of self-awareness, and a loss of knowledge and perspective on the history of the past fifty to seventy years that led to this point. Larger societal pressures and trends are pushing the field in directions that are counter-productive and work actively to undermine the potential of the future. All of this is happening at the same time that computer hardware is either undergoing a crisis or phase transition to a different state. Together we are entering an exciting, but dangerous time that will require great wisdom to navigate. I truly fear that the necessary wisdom while available will not be called upon. If we continue to choose the shortsighted path and avoid doing some difficult things, the outcome could be quite damaging.
 A couple of notes about the venue should be made. Barcelona is a truly beautiful city with wonderful weather, people, architecture food, mass transit, I really enjoyed the visit, and there is plenty to comment on. Too few Americans have visited other countries to put their own country in perspective. After a short time you start to hone in on the differences between where you visit and where you live. Coming from America and hearing about the Spanish economy I expected far more homelessness and obvious poverty. I saw very little of either societal ill during my visit. If this is what economic disaster looks like, then it’s hard to see it as a
A couple of notes about the venue should be made. Barcelona is a truly beautiful city with wonderful weather, people, architecture food, mass transit, I really enjoyed the visit, and there is plenty to comment on. Too few Americans have visited other countries to put their own country in perspective. After a short time you start to hone in on the differences between where you visit and where you live. Coming from America and hearing about the Spanish economy I expected far more homelessness and obvious poverty. I saw very little of either societal ill during my visit. If this is what economic disaster looks like, then it’s hard to see it as a n actual disaster. Frankly, the USA looks much worse by comparison with a supposedly recovering economy. There are private security guards everywhere. The amount of security and the meeting was actually a bit distressing. In contrast to this in a week, at a hotel across the street from the hospital, I heard exactly one siren, amazing. As usual getting away from my standard environment is thought provoking, which is always a great thing.
n actual disaster. Frankly, the USA looks much worse by comparison with a supposedly recovering economy. There are private security guards everywhere. The amount of security and the meeting was actually a bit distressing. In contrast to this in a week, at a hotel across the street from the hospital, I heard exactly one siren, amazing. As usual getting away from my standard environment is thought provoking, which is always a great thing.
 , where the subscript denotes differentiation with respect to the variable. This equation is about as simple as PDEs get, but it is notoriously difficult to solve numerically.
, where the subscript denotes differentiation with respect to the variable. This equation is about as simple as PDEs get, but it is notoriously difficult to solve numerically. . This means that the temporal solution is simply defined by the initial condition translated by the velocity (which is one in this case) and time. Nothing changes it simply moves in space. This is a very simple form of space-time self-similarity. If we are solving this equation numerically, any change in the waveform is an error. We can also note that the integral of the value is preserved (of course) making this a “conservation law”. Later when you’d like to solve harder problems this property is exceedingly important.
. This means that the temporal solution is simply defined by the initial condition translated by the velocity (which is one in this case) and time. Nothing changes it simply moves in space. This is a very simple form of space-time self-similarity. If we are solving this equation numerically, any change in the waveform is an error. We can also note that the integral of the value is preserved (of course) making this a “conservation law”. Later when you’d like to solve harder problems this property is exceedingly important. , where
, where  is the grid index of our discretized function, and
is the grid index of our discretized function, and  is the angle parameterizing frequency of the waveform. The analysis then proceeds much as in the style as the ODE work from last week, one substitutes this function into the numerical scheme and works out the modification of the waveform by the numerical method. We then take this modification to be the symbol of the operator
is the angle parameterizing frequency of the waveform. The analysis then proceeds much as in the style as the ODE work from last week, one substitutes this function into the numerical scheme and works out the modification of the waveform by the numerical method. We then take this modification to be the symbol of the operator  . In this form we have divided the symbol into two effects its amplitude and its modulation of the waveform or phase. Finishing our conceptual toolbox is the expression of the exact solution as
. In this form we have divided the symbol into two effects its amplitude and its modulation of the waveform or phase. Finishing our conceptual toolbox is the expression of the exact solution as  .
. where
where  is the Courant or CFL number and
is the Courant or CFL number and  is the upwind edge value. The CFL number is the similarity variable (dimensionless) of greatest important for numerical schemes for hyperbolic PDEs. Now we plug our Fourier function into the grid values in the scheme and evaluate for a single grid point
is the upwind edge value. The CFL number is the similarity variable (dimensionless) of greatest important for numerical schemes for hyperbolic PDEs. Now we plug our Fourier function into the grid values in the scheme and evaluate for a single grid point  . Without showing the trivial algebraic steps this gives
. Without showing the trivial algebraic steps this gives  . We can make the substitution of the trigonometric functions for the complex exponential, $\exp\left(-\imath \theta\right) = \cos\left(\theta\right) – \imath \sin\left(\theta\right)$.
. We can make the substitution of the trigonometric functions for the complex exponential, $\exp\left(-\imath \theta\right) = \cos\left(\theta\right) – \imath \sin\left(\theta\right)$. . The exact solution has amplitude of one, and a phase of
. The exact solution has amplitude of one, and a phase of  . Once we have separated the symbol into its pieces we can then examine the formal truncation error of the method (as
. Once we have separated the symbol into its pieces we can then examine the formal truncation error of the method (as  is equivalent to
is equivalent to  ) in a straightforward manner.
) in a straightforward manner.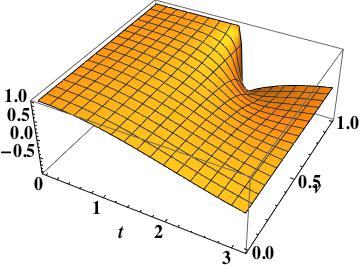
 . The phase error can be similarly treated,
. The phase error can be similarly treated,  . Please note that the phase error is actually one order higher than I’ve written because of its definition where I have divided
. Please note that the phase error is actually one order higher than I’ve written because of its definition where I have divided through by
through by  . The last bit of analysis we conduct is to make an estimate of the rate of convergence as a function of the mesh spacing and CFL number. Given the symbol we can compute the error
. The last bit of analysis we conduct is to make an estimate of the rate of convergence as a function of the mesh spacing and CFL number. Given the symbol we can compute the error  . We then compute the error with a refined grid by a factor of two and note that it must applied twice to get the solution to the same point in time. The error for the refined calculation is
. We then compute the error with a refined grid by a factor of two and note that it must applied twice to get the solution to the same point in time. The error for the refined calculation is  , which is squared to account for two time steps being taken to get to the same simulation time,
, which is squared to account for two time steps being taken to get to the same simulation time,  .Given these errors the local rate of convergence is simple,
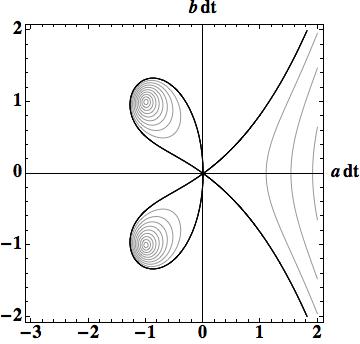
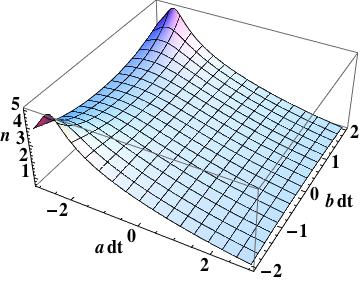
.Given these errors the local rate of convergence is simple,  . We can then plot the function where we see that the convergence rate deviates significantly from one (the expected value) for finite values of
. We can then plot the function where we see that the convergence rate deviates significantly from one (the expected value) for finite values of  .
. We can now apply the same machinery to more complex schemes. Our first example is the time-space coupled version of Fromm’s scheme, which is a second-order method. Conducting the analysis is largely a function of writing the numerical scheme in Mathematica much in the same fashion we would use to write the method into a computer code.
We can now apply the same machinery to more complex schemes. Our first example is the time-space coupled version of Fromm’s scheme, which is a second-order method. Conducting the analysis is largely a function of writing the numerical scheme in Mathematica much in the same fashion we would use to write the method into a computer code. and then use this to define a edge-centered, time-centered value,
and then use this to define a edge-centered, time-centered value,  . This choice has a “build-in” upwind bias. If the velocity in the equation were oriented oppositely, this choice would be
. This choice has a “build-in” upwind bias. If the velocity in the equation were oriented oppositely, this choice would be  instead (
instead ( ). Now we can write the update for the cell-centered variables as
). Now we can write the update for the cell-centered variables as  , substitute in the Fourier transform and apply all the same rules as for the first-order upwind method.
, substitute in the Fourier transform and apply all the same rules as for the first-order upwind method.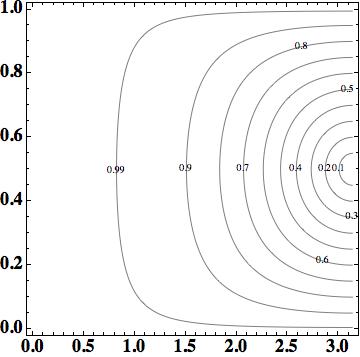
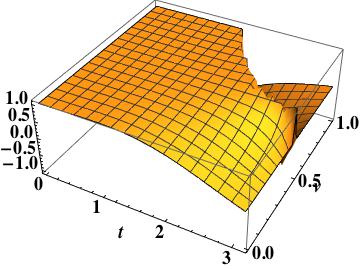
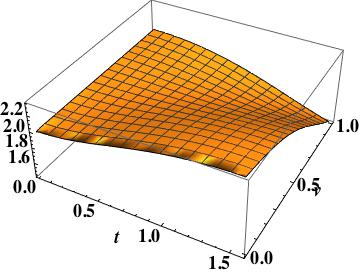
 . The phase error is smaller than the upwind scheme, but the same order,
. The phase error is smaller than the upwind scheme, but the same order,  . This is the leading order error in Fromm’s scheme.
. This is the leading order error in Fromm’s scheme. , as simply
, as simply  . We take the right hand side
. We take the right hand side  , and do some algebra. We have several principal goals, establish conditions for stability, accuracy, and overall behavior of the method.
, and do some algebra. We have several principal goals, establish conditions for stability, accuracy, and overall behavior of the method. , we remove the variable and call the result the “symbol’’ of the integrator,
, we remove the variable and call the result the “symbol’’ of the integrator,  , we then solve for
, we then solve for  then take its magnitude,
then take its magnitude,  , being less than one for stability. We can write down this answer explicitly
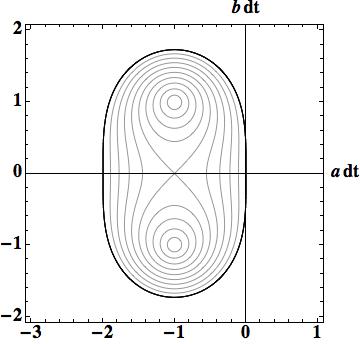
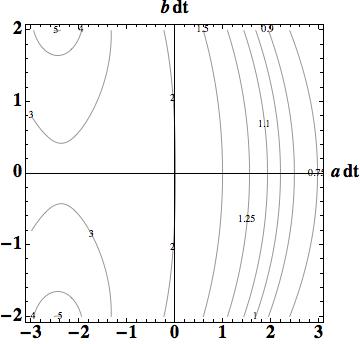
, being less than one for stability. We can write down this answer explicitly  . We can also plot this result easily (see the commands I used in Mathematica at the end of the post). On all the plots the horizontal axis is the real values
. We can also plot this result easily (see the commands I used in Mathematica at the end of the post). On all the plots the horizontal axis is the real values  and the vertical axis is the imaginary values
and the vertical axis is the imaginary values  .
.
 , and the Taylor series expansion is classical,
, and the Taylor series expansion is classical,  . We simply subtract this Taylor series from the symbol of the operator and look at the remainder, $\latex E= \frac{1}{2}(\lambda \Delta t)^2+ O(\Delta t^3)$, where the time has been replaced by the time step size.
. We simply subtract this Taylor series from the symbol of the operator and look at the remainder, $\latex E= \frac{1}{2}(\lambda \Delta t)^2+ O(\Delta t^3)$, where the time has been replaced by the time step size.
 ,
,  for two time steps (so that the time ends up at the same place as you get for a single step with
for two time steps (so that the time ends up at the same place as you get for a single step with 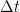 . This is simply the square of the operator at the smaller time step size. To get the order of accuracy you take the operators and subtract the exact solution, take the absolute value of the result, then compute the order of accuracy like usual verification,
. This is simply the square of the operator at the smaller time step size. To get the order of accuracy you take the operators and subtract the exact solution, take the absolute value of the result, then compute the order of accuracy like usual verification,

 Look for
Look for for the predictor, and
for the predictor, and  . The symbol is computed as before giving
. The symbol is computed as before giving  . Getting the full properties of the method now just requires “turning the crank’’ as we did for the forward Euler scheme.
. Getting the full properties of the method now just requires “turning the crank’’ as we did for the forward Euler scheme. .
.
 , and the amplification is now a quadratic equation,
, and the amplification is now a quadratic equation,  with two roots. One of these roots will have a Taylor series expansion that demonstrates second-order accuracy for the scheme, the other will not. The inaccurate root must still be stable for the scheme to be stable. The accurate root is
with two roots. One of these roots will have a Taylor series expansion that demonstrates second-order accuracy for the scheme, the other will not. The inaccurate root must still be stable for the scheme to be stable. The accurate root is
 .
.
 .
.

 ieved by using symbolic or numerical packages such as Mathematica. Below I’ve included the Mathematica code used for the analyses given above.
ieved by using symbolic or numerical packages such as Mathematica. Below I’ve included the Mathematica code used for the analyses given above. he Palmer House, which is absolutely stunning venue swimming in old-fashioned style and grandeur. It is right around the corner from Millennium Park, which is one of the greatest Urban green spaces in existence, which itself is across the street from the Art Institute. What an inspiring setting to hold a meeting. Chicago itself is one of the great American cities with a vibrant downtown and numerous World-class sites.
he Palmer House, which is absolutely stunning venue swimming in old-fashioned style and grandeur. It is right around the corner from Millennium Park, which is one of the greatest Urban green spaces in existence, which itself is across the street from the Art Institute. What an inspiring setting to hold a meeting. Chicago itself is one of the great American cities with a vibrant downtown and numerous World-class sites. ortance to the overall scientific enterprise, and applied mathematics is suffering likewise. This isn’t merely the issue of funding, which is relatively dismal, but overall direction and priority. In total, we aren’t asking nearly enough from science, and mathematics is no different. The fear of failure is keeping us from collectively attacking society’s most important problems. The distressing part of all of this is the importance and power of applied mathematics and the rigor it brings to science as a whole. We desperately need some vision moving forward.
ortance to the overall scientific enterprise, and applied mathematics is suffering likewise. This isn’t merely the issue of funding, which is relatively dismal, but overall direction and priority. In total, we aren’t asking nearly enough from science, and mathematics is no different. The fear of failure is keeping us from collectively attacking society’s most important problems. The distressing part of all of this is the importance and power of applied mathematics and the rigor it brings to science as a whole. We desperately need some vision moving forward.
 the work of Peter Lax on hyperbolic conservation laws. He laid the groundwork for stunning progress in modeling and simulating with confidence and rigor. There are other examples such as the mathematical order and confidence of the total variation diminishing theory of Harten to power the penetration of high-resolution methods into broad usage for solving hyperbolic PDEs. Another example is the relative power and confidence brought to the solution of ordinary differential equations, or numerical linear algebra by the mathematical rigor underlying the development of software. These are examples where the presence of applied mathematics makes a consequential and significant difference in the delivery of results with confidence and rigor. Each of these is an example of how mathematics can unleash a capability in truly “game-changing” ways. A real concern is why this isn’t happening more broadly or in targeted manner.
the work of Peter Lax on hyperbolic conservation laws. He laid the groundwork for stunning progress in modeling and simulating with confidence and rigor. There are other examples such as the mathematical order and confidence of the total variation diminishing theory of Harten to power the penetration of high-resolution methods into broad usage for solving hyperbolic PDEs. Another example is the relative power and confidence brought to the solution of ordinary differential equations, or numerical linear algebra by the mathematical rigor underlying the development of software. These are examples where the presence of applied mathematics makes a consequential and significant difference in the delivery of results with confidence and rigor. Each of these is an example of how mathematics can unleash a capability in truly “game-changing” ways. A real concern is why this isn’t happening more broadly or in targeted manner.



 rather hyperbolic, and it is. The issue is that the leadership of the nation is constantly stoking the fires of irrational fear as a tool to drive political goals. By failing to aspire toward a spirit of shared sacrifice and duty, we are creating a society that looks to avoid anything remotely dangerous or risky. The consequences of this cynical form of gamesmanship are slowly ravaging the United States’ ability to be a dynamic force for anything good. In the process we are sapping the vitality that once brought the nation to the head of the international order. In some ways this trend is symptomatic of our largess as the sole military and economic superpower of the last half of the 20th Century. The fear is drawn from the societal memory of our fading roll in the World, and the evolution away from the mono-polar power we once represented.
rather hyperbolic, and it is. The issue is that the leadership of the nation is constantly stoking the fires of irrational fear as a tool to drive political goals. By failing to aspire toward a spirit of shared sacrifice and duty, we are creating a society that looks to avoid anything remotely dangerous or risky. The consequences of this cynical form of gamesmanship are slowly ravaging the United States’ ability to be a dynamic force for anything good. In the process we are sapping the vitality that once brought the nation to the head of the international order. In some ways this trend is symptomatic of our largess as the sole military and economic superpower of the last half of the 20th Century. The fear is drawn from the societal memory of our fading roll in the World, and the evolution away from the mono-polar power we once represented. ctions in the region has coupled this. Supposedly ISIS is worse than Al Qaeda, and we should be afraid. You are so afraid that you will demand action. In fact that hamburger you are stuffing into your face is a much larger danger to your well being than ISIS will ever be. Worse yet, we put up with the fear-mongers whose fear baiting is aided and abetted by the new media because they see ratings. When we add up the costs, this chorus of fear is savaging us and it is hurting our Country deeply.
ctions in the region has coupled this. Supposedly ISIS is worse than Al Qaeda, and we should be afraid. You are so afraid that you will demand action. In fact that hamburger you are stuffing into your face is a much larger danger to your well being than ISIS will ever be. Worse yet, we put up with the fear-mongers whose fear baiting is aided and abetted by the new media because they see ratings. When we add up the costs, this chorus of fear is savaging us and it is hurting our Country deeply. United States is now more arduous than entering the former Soviet Union (Russia). This fact ought to absolutely be appalling to the American psyche. Meanwhile, numerous bigger threats go completely untouched by action or effort to mitigate their impact.
United States is now more arduous than entering the former Soviet Union (Russia). This fact ought to absolutely be appalling to the American psyche. Meanwhile, numerous bigger threats go completely untouched by action or effort to mitigate their impact. When did all this start? I tend to think that the tipping point was the mid-1970’s. This era was extremely important for the United States with a number of psychically jarring events taking center stage. The upheaval of the 1960’s had turned society on its head with deep changes in racial and sexual politics. The Vietnam War had undermined the Nation’s innate sense of supremacy while scandal ripped through the government. Faith and trust in the United States took a major hit. At the same time it marked the apex of economic equality with the beginnings of the trends that have undermined it ever since. This underlying lack of faith and trust in institutions has played a key roll in powering our decline. The anti-tax movement that set in motion public policy that drives the growing inequality in income and wealth began then arising from these very forces. These coupled to the insecurities of national defense, gender and race to form the foundation of the modern conservative movement. These fears have been used over and over to drive money and power into the military-intelligence-industrial-complex at a completely irrational rate.
When did all this start? I tend to think that the tipping point was the mid-1970’s. This era was extremely important for the United States with a number of psychically jarring events taking center stage. The upheaval of the 1960’s had turned society on its head with deep changes in racial and sexual politics. The Vietnam War had undermined the Nation’s innate sense of supremacy while scandal ripped through the government. Faith and trust in the United States took a major hit. At the same time it marked the apex of economic equality with the beginnings of the trends that have undermined it ever since. This underlying lack of faith and trust in institutions has played a key roll in powering our decline. The anti-tax movement that set in motion public policy that drives the growing inequality in income and wealth began then arising from these very forces. These coupled to the insecurities of national defense, gender and race to form the foundation of the modern conservative movement. These fears have been used over and over to drive money and power into the military-intelligence-industrial-complex at a completely irrational rate.


 There is a gap, but it isn’t measured in terms of FLOPS, CPUs, memory, it is measured in terms of our practice. Our supercomputers have lost touch with reality. Supercomputing needs to be connected to a real tangible activity where the modeling assists experiments, observations and design in producing something that services a societal need. These societal needs could be anything from national defense, cyber-security, space exploration, to designing better more fuel-efficient aircraft, or safer more efficient energy production. The reality we are seeing is that each of these has become secondary to the need for the fastest supercomputer.
There is a gap, but it isn’t measured in terms of FLOPS, CPUs, memory, it is measured in terms of our practice. Our supercomputers have lost touch with reality. Supercomputing needs to be connected to a real tangible activity where the modeling assists experiments, observations and design in producing something that services a societal need. These societal needs could be anything from national defense, cyber-security, space exploration, to designing better more fuel-efficient aircraft, or safer more efficient energy production. The reality we are seeing is that each of these has become secondary to the need for the fastest supercomputer.

 s become the focus. This has led to a diminishment in the focus on algorithms and methods, which has actually a better track record than Moore’s law for improving computational problem solving capability. The consequence of this misguided focus is a real diminishment in our actual capability to solve problems with supercomputers. In other words, our quest for the fastest computer is ironically undermining our ability to use computers effectively as possible.
s become the focus. This has led to a diminishment in the focus on algorithms and methods, which has actually a better track record than Moore’s law for improving computational problem solving capability. The consequence of this misguided focus is a real diminishment in our actual capability to solve problems with supercomputers. In other words, our quest for the fastest computer is ironically undermining our ability to use computers effectively as possible.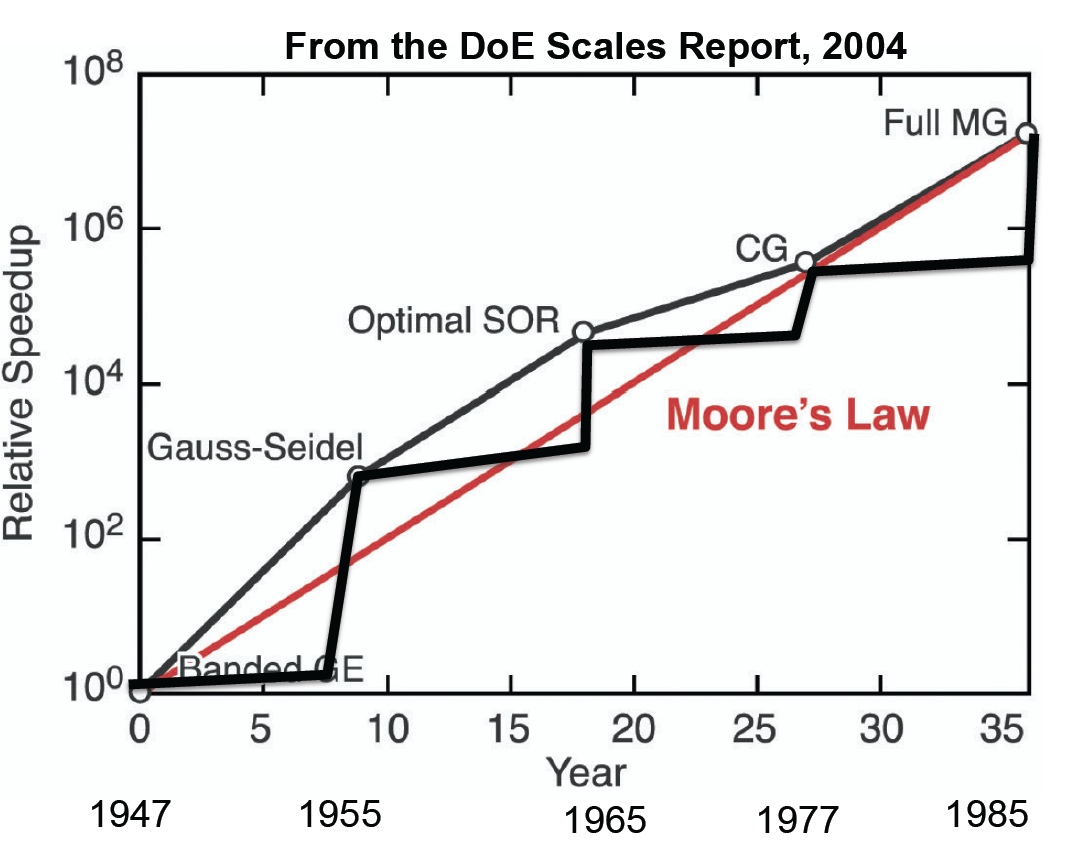
 We should work steadfastly to restore the necessary balance and perspective for success. We need to allow risk to enter into our research agenda and set more aggressive goals. Requisite with this risk we should provide greater freedom and autonomy to those striving for the goals. Supercomputing should recognize that the core of its utility is computing as a problem solving approach that relies upon computing hardware for success. There is an unfortunate tendency to simply state supercomputing as a national security resource regardless of the actual utility of the computer for problem solving. These claims border on being unethical. We need computers that are primarily designed to solve important problems. Problems don’t become important because a computer can solve them.
We should work steadfastly to restore the necessary balance and perspective for success. We need to allow risk to enter into our research agenda and set more aggressive goals. Requisite with this risk we should provide greater freedom and autonomy to those striving for the goals. Supercomputing should recognize that the core of its utility is computing as a problem solving approach that relies upon computing hardware for success. There is an unfortunate tendency to simply state supercomputing as a national security resource regardless of the actual utility of the computer for problem solving. These claims border on being unethical. We need computers that are primarily designed to solve important problems. Problems don’t become important because a computer can solve them.



 I’ve quipped that we should have a special conference center is some awful place where no one would want to go. That way the Congress and public would know that we go to the conferences to engage in technical work. On the other hand, part of going to conferences involves getting inspired to do better work. Why not go to some place that is inspiring? Why not go to some place that has great restaurants so that the sharing of the meal can be memorable on multiple levels? Why not make the entire event memorable and worthwhile and enriching at a personal level? At the core of the attitude of many in government is a sense that life should be suffered with work being the most unpleasant aspect of them all. It is a rather pathetic point of view that leads to nothing positive. We shouldn’t be punished for working in the public sphere, yet punishment seems to be the objective.
I’ve quipped that we should have a special conference center is some awful place where no one would want to go. That way the Congress and public would know that we go to the conferences to engage in technical work. On the other hand, part of going to conferences involves getting inspired to do better work. Why not go to some place that is inspiring? Why not go to some place that has great restaurants so that the sharing of the meal can be memorable on multiple levels? Why not make the entire event memorable and worthwhile and enriching at a personal level? At the core of the attitude of many in government is a sense that life should be suffered with work being the most unpleasant aspect of them all. It is a rather pathetic point of view that leads to nothing positive. We shouldn’t be punished for working in the public sphere, yet punishment seems to be the objective.











 common and not unlike other innovations such as the Internet (started by DoD/DARPA but perfected outside the defense industry). While Los Alamos was a hotbed of development for CFD methods, over time, it ceased to be the source of innovation. This state of affairs was a constant source of consternation on my part while I worked at the Lab. Ultimately computation had a very utilitarian role there, and once they were functional, innovation wasn’t necessary.
common and not unlike other innovations such as the Internet (started by DoD/DARPA but perfected outside the defense industry). While Los Alamos was a hotbed of development for CFD methods, over time, it ceased to be the source of innovation. This state of affairs was a constant source of consternation on my part while I worked at the Lab. Ultimately computation had a very utilitarian role there, and once they were functional, innovation wasn’t necessary.


