
There are two standard ways of thinking about differential equations, the strong and the weak form. The strong form is usually the most familiar involving derivatives that all exist. By the same token it is less useful because derivatives don’t always exist, or a least not in a form that is familiar (i.e., singularities form or exist and evolve). The weak form is less familiar, but more general and more generally useful. The weak form involves integrals of the strong form differential equations, and describes solutions that are more general because of this. This is because we can integrate across the areas that undermine the strong solutions and access the underlying well-behaved solution. Functions that have derivatives that are undefined have perfectly well defined integral. One of the keys to the utility of the weak form is the existence of many more solutions for the weak form than the associated strong form. With these many solutions we have additional burden to find solutions that are meaningful. By meaningful I mean physical, or more plainly those that can be found in the natural universe.*
Just as the differential equations can be cast in the strong and weak form, initial and boundary conditions can do the same. Just as with the differential equations these differences are consequential in how the solutions to differential equations perform. I have found that both ideas are useful in the context of successfully running problems. If you run problems then you have to deal with boundary conditions and boundary conditions are essential, and essentially ignored in most discussions. Perhaps not conincidently the boundary conditions are the ugliest and kludgiest part of most codes. If you want to look at bad code, look at how boundary conditions are implemented.
The classic approach for setting boundary conditions in a finite volume code is the use of “ghost” cells. These ghost cells are added onto the grid in layers outside the domain where the solution is obtained. The values in the ghost cells is set in order to achieve the boundary effect when the stencil is applied to the entire method (i.e., the finite difference method). For a finite volume method, the values in the cells are updated through the application of fluxes in and out of each of the cells. This step is where issues occur namely that the fluxes are not necessarily the same fluxes one would get by applying the boundary condition correctly. Ghost cells use the strong form of the PDE in their mindset. This is the imposition of the continuously differentiable equation outside the domain. One proviso is that a control volume method is inherently a weak form of the PDE concept, so there is a sort of mixed boundary condition once you decide how to compute the flux at the boundary.
Fluxing is where the weak boundary condition comes in. In the weak boundary condition, the flux itself or the process of the flux calculation is used to impose the boundary condition. If one is using a solver based upon a Riemann solver then the state going into the Riemann solution on the boundary from outside the domain imposes the boundary condition. The best thing about this approach is that the update to the values in the cells is updated in a manner that is consistent with the boundary condition.
If you are using a first-order method for integrating the equations of motion, the weak boundary condition is the only one that matters. For most modern shock capturing methods, the first-order method is essential for producing quality results. In this case the weak boundary condition determines the wave interaction at the boundary because it defines the state of the fluid at the boundary on the outside of the domain.
Just to be more concrete regarding the discussion I will provide a bit of detail on one particular boundary condition, a reflection (or inviscid wall). At a wall the normal velocity is zero, but the velocity extrapolated to the boundary from cell-centeres is rarely identically zero. The other variables all have a zero gradient. The normal velocity outside the boundary in the ghost cell is the mirror of the cells internal, thus taking on a value of negative the value on the physical grid cells. By the same token, the other variables take identical values to those inside the domain. More particularly for the strong boundary conditions, the first ghost cell takes the same value as the first interior cell except for normal velocity where the value is negative the interior value. If you have a second ghost cell then the same is applied to values taken from the second interior cell, and so on. For the weak boundary condition, the same procedure is taken, but applied to the values at the boundary extrapolated from the last interior cell.
In practice, I use both strong and weak boundary conditions to minimize problems in each step of the finite volume method. In this manner the boundary conditions are reinforced by each step and the solution is more consistent with the desired conditions. This is clearest when a scheme with a wide stencil is used where non-boundary cells access ghost cells. In practice the discrepancy between the strongly and weakly imposed boundary conditions is small; however, when limiters and other nonlinear numerical mechanisms are used in a solver these differences can become substantial.
If you want to read more I would suggest the chapter on boundary conditions from Culbert Laney’s excellent “Computational Gasdynamics” that touches upon some of these issues.
* Mathematicians can be interested in more general unphysical solutions and do lots of beautiful mathematics. The utility of this work is may be questionable, or at least scrutized more than it often is. The beauty of it is a matter of aesthetics, much like art. An example would be the existence of solutions to the incompressible Euler equations where the lack of connection to the physical world is two fold**: incompressibility isn’t entirely physical (infinite sound speeds! No thermodynamics) and setting viscosity equal to zero isn’t physical either (physical solutions come from viscosity being positive definite, which is a different limiting process). These distinctions seem to be lost in some math papers.
**Remarkably the lack of connection to the physical World doesn’t limit things to being useless. For many applications the unphysical approximation of incompressibility is useful. Many engineering applications profitably use incompressible flow because it gets rid of sound waves that are not particularly important or useful to get right. The same is true for inviscid flows such as potential flow, which can be used for aircraft design at a basic level. The place where this lack of physical connection should be more worrisome is in physics. Take turbulent flow, which is thought of as a great-unsolved physics problem. The fact that turbulence is believed to be associated with the mathematics of incompressible flows, yet remains largely unsolved should come as no surprise. I might posit that the ability to make progress on physical problems with unphysical approximation might be dubious.
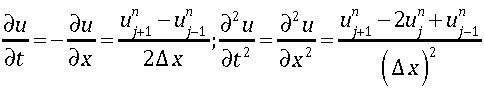
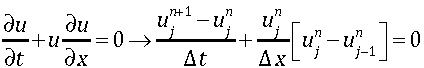
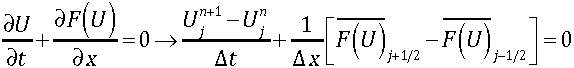
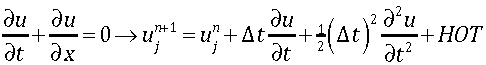
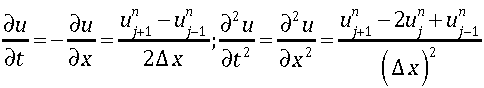
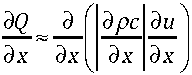
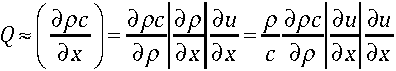
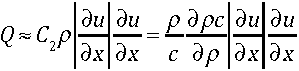
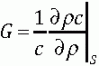 , (9)
, (9)


