tl;dr
This story has been 13 years in the making. Key facts and aspects remain untold.. Now it can be with important details. I wrote this blog from 2013-2018, consistently. I was stopped by the threat of punishment by the Lab (management). I started up again in 2024. In 2025, I was forced to stop in a similar, but worse manner. The reasons come down to control and fear on the part of my management. This sort of control by management and power seems widespread and common in society. It is almost expected today. It is a characteristic of our leadership across the nation. They use their power to threaten and punish the voice of the rank and file. It is the beating heart of inequality in society today. In my case, science and national security suffer. More broadly, this power undermines trust and protects corruption and incompetence.
“There must be no barriers to freedom of inquiry… There is no place for dogma in science. The scientist is free, and must be free to ask any question, to doubt any assertion, to seek for any evidence, to correct any errors.”
– Dr. J. Robert Oppenheimer.

Prolog
I retired because Sandia became intolerable for me. It was clear that I was simplywasting my time there. As you get older, you realize that time is the most precious thing you have. It was a privilege to work there. I have always believed deeplyin the responsibility of the Lab’s work. The work needed to be donewith quality and care. That isn’t what is happening. Management wants control. Quality work and experts are a threat to that control. Their actions became incompatible with my values. I had to leave.
A key part of this discussion is going to explain my complaints about declaring Sandia’s Shock Physics work to be “world-class.” This is an utterlydelusional statement. At least the current state of it, there, and the nature of the leadership. The impediments to being world-class will become obvious in the discussion to follow. Instead, I will show how opposed the leadership is to anything that would be considered technical excellence.
I note with work, guided efforts, and development of young staff, the Sandia Shock Physics effort could become world-class. This would require senior staff to guide and mentor the work. Unfortunately, current leadership is utterly and completely overmatched in achieving that. What I hope will be clear by the end of this essay is that current leadership is actually orthogonal to the goal of being world-class. They actually are managing towards a state of mediocrity. Mediocre is a fair assessment of the current capability. Yet, management bullshits everyone about how great they are. What you learn by the end of this piece is why that declaration of being world-class so completely disgusted me.
I’m fairly sure the managers think that declaring the group to be world-class is some sort of pep talk or stroking of ego needed for the individuals. Instead, they need leadership that tells the people that we need to be better. We need to work harder. We need to do the things that raise our game so that we can be world-class. We have leadership existing with incentives that allows to encouraging bad behavior. It also allows a variety of inept, incompetent, and unethical behaviors to exist. Worse still, it is seemingly encouraged or, at a minimum, generally tolerated. What you do not see is management that is oriented towards cultivating excellence or competent execution of the mission. You recognize that excellence is difficult and hard to manage. Working on marketing and bullshit is cheap and easy. Increasingly, it is the easy route that management has taken.
The declaration of being world-class before anyone has done anything to deserve that is merely the sort of grade inflation common today. It is a common complaint lodged against elite institutions such as Harvard. Everybody gets an A. Everyone is world-class. This is the same kind of weak-willed leadership that we’ve come to expect as a nation. The USA sits behind its chief rival, China, in the accomplishment of science and technology. This sort of pathetic leadership is completely unpatriotic. It only serves to deepen our deficits and give comfort to our enemies.
Being the age that I am, I don’t have the luxury or the time to wait for things to improve. I need to move on, live, and express myself while I still have the energy and power to do so. I have many interests where I believe continued innovation and progress is necessary. I see the current expansion of AI into our lives as an enormous promise as well as a threat. I have an immense amount of interest in working on contributing to its proper use. That said, I have very little hope in the current system actually finding the best use for it. The current system will not produce a technology that meets its potential for good.
I’ve seen far too many irresponsible, incompetent, and unethical actions by managers at Sandia. They are engaged in abuse of power routinely. To believe that they will actually produce good, viable, positive solutions to any of these huge challenges is folly. The toxic positivity that inhabits their narratives is the opposite of genuine positivity. It is actually an active and mindful approach to avoiding problems. This avoidance means avoiding solutions, innovations, and progress of all sorts. AI is one of the biggest challenges we’ve had, perhaps since the advent of nuclear weapons! Our leadership is arrayed against meeting these challenges well. The cost to society could be huge. Done properly, AI could be a boon for the future. Done wrong, AI could be a catastrophe. Current leadership tilts the balance toward disaster.
I retired because I had nothing left to contribute at Sandia. It is not that I have nothing I could contribute. I was unable to contribute to the environment present. In a more functional place, I would have a great deal more to contribute. A great deal of it, I believe, to be essential to success., Those contributions would not be accepted and had no outlet. So, to put it differently, the meaningful contributions that I could provide are not acceptable to those in charge. This is because those in charge are irresponsible and have other values and principles that they are adhering to. The impediments at Sandia also reflect society more broadly.
The Events That Prompted My Retirement
I will get to the original blog stoppage back in 2018 later in this essay. It is an echo of the recent events. As noted, my retirement was a direct consequence of losing my voice. Not simplythe voice the blog gives me; I lost any voice in the workplace. There is a lot to this, and all of it reflects poorly on my management, Sandia’s culture, and the Lab itself. To make matters worse, the silence was associated with topics where I was the Lab’s foremost expert. It reflected the complete rejection of expertise by the Lab. As a result, they are not stewarding essential responsibilities. All of this happens with the impunity of secrecy, and no sense of responsibility to citizens through the execution of the Lab’s mission.
“Shame corrodes the very part of us that believes we are capable of change.” ― Brene Brown,

To get to the bottom of this, we need to look at where this all started two years ago. I was assisting a coworker who was engaged in some mission work involving “shock physics”. The key computer code used for this sort of work by Sandia is the shock physics code, CTH. The results were mysteriously poor on an exceptionallyimportant problem. It is often characterized as the single most consequential thing we do, at least where shock physics is concerned. So you would think managers would take quality seriously. CTH is used for a host of other important applications at Sandia and other institutions. This isn’t a minor or idiosyncratic problem; it is fundamental to the code’s credibility.
My coworker engaged me as an expert in both shock physics, combined with verification and validation.. I am also an expert in the mission relevant applications. In brief, I was the correct subject matter expert to be involved. No one at Sandia knew more about these topics than me.

As part of the study he engaged in a verification exercise to determine whether the code was correct for strong shocks. There are two basic problems that are canonical for verification, Sedov and Noh. Both are analytical and involve infinitely strong shocks. The infinite shock fundamentally allows analytical solution. These problems are used by all three NNSA labs to verify their codes (as well as broadly in the international shock physics commuity). My coworker is relentless and competent. This work was executed in his usual sterling manner. The results were distressing. The code did not solve these problems correctly.
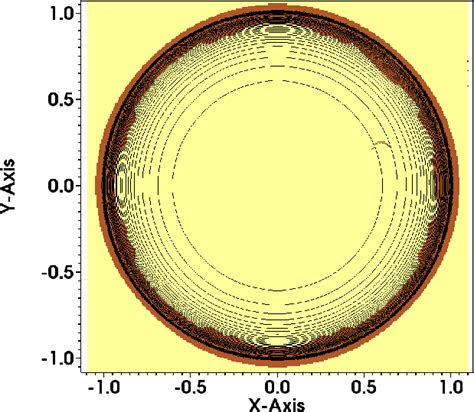
I will note that this wasn’t remotely unexpected by me. Knowing how CTH was writtenand implemented made the results exceedinglypredictable and theoreticallywell grounded. Knowing this isn’t enough; one needs to demonstrate it holds in reality. This is essential verification work, done correctly. Additionally, CTH also produced results consistent with the infamous carbuncle instability as well. This is another common affliction of CFD codes. It can produce serious errors in many applied problems. They can be remedied as well. One just needs a modicum of competence and effort. My colleague wrote a detailed report, made a presentation and approached me to review them. Basically, this is an exercise of best practices at this point.
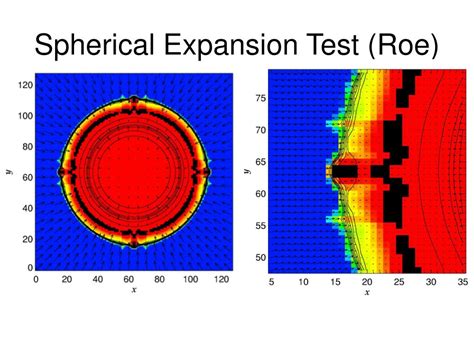
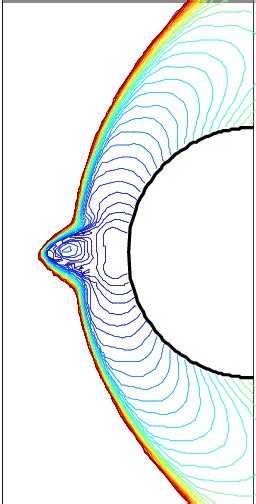
I reviewed it and provided detailed feedback. I had a large amount of feedback, but little need for corrections, just suggested expanded discussion. All of the work was top-notch save for a deeper analysis of its implications, and prospective cures. These measures are not really in his wheelhouse. Nonetheless, the work was solid and unassailable. The nature of the problems could indeed contribute to the poor results. The issues identified were serious and undermined the credibility of CTH. Lots of other things could produce bad results, too, but this was a “smoking gun.”
Then the shit hit the fan.
“People who try hard to do the right thing always seem mad.”
― Stephen King
The manager for the department that is responsible for CTH took actions to hide these results. He made my coworker pull his presentation from a conference, and demanded the report be pulled as well. In other words, he censored the work. He censored it because he didn’t like the results. These actions were indefensible technically and ethically. The work was excellent verification work. They were also completely unclassified, open research, not sensitive in any way. The only thing that was “sensitive” was the bad results. In other words, it was a cover-up.
To justify these actions, the manager made a bunch of naive, incompetent, and biased critiques that only showed how little he knew about shock physics. His comments should never been taken seriously. I will counter that the responsible reaction on his part would have been “this is bad, how do we fix the code?” I could have suggested several curative approaches. Instead, his response was completely unethical and irresponsible. A key thing was that my group leader decided to support this manager and not my coworker (who is in his group). They both ignored my review or position as an SME entirely, nor did they approach me for my comments. Expert knowledge of the topic had no bearing on their actions. The managers have clearly demonstrated their unethical, irresponsible, and incompetent nature.
At this juncture, it is useful to step back to define Sandia’s core mission and the principles surrounding it. Since the end of the Cold War and cessation of nuclear testing, it has engaged in stockpile stewardship. While nuclear testing is always the best answer, it comes with unacceptable consequences in foreign policy. This stewardship requires an unassailable technical foundation for all we continue to do. This means competent, responsible, and ethical work requiring attention to detail and commitment to quality. With testing taken off the table, every other element of the work needs to be of higher quality. Vibrant and focused V&V is a vehicle for high-quality work.
Part of this is hard-nosed peer review of the highest standard. The part I worked on is the modeling and simulation of our stockpile. I take it seriously as a sacred responsibility. Sadly, too many of the people leading the labs have abandoned the quality and standards needed for success. Worse yet, the Lab itself seems to have developed a tolerance for these appalling standards. I saw this clearly in this episode. Rather than steward the stockpile, my management was burying it in mediocrity.
My first response was annoyance, and to let the process play out. It did not play out, and the censorship threatened to become permanent. It became clear that the CTH manager intended for the report to be buried forever. I didn’t point out how incompetent his review was either. I tried to engage respectfully, but it became clear that his actions were not taken in good faith. Moreover, my position as a senior staff member and SME was meaningless to the proceedings. After 18 months of censorship had passed, I called it out.I asked why the report remained unpublished despite being technicallyhigh quality?
This action ended my career. Rather, the management’s reaction to this was the end. There was half-assed action on their part, but no mea culpa. We see managers who demand control and allow it to nullify all technical concerns. They show no responsibility to ably and ethically execute the Lab’s mission. The nation has trusted the Labs to do this. This trust is misplaced in our current system.

“It is impossible for someone to lie unless he thinks he knows the truth. Producing bullshit requires no such conviction.” ― Harry G. Frankfurt
I harbor a different, more dire analysis. My managers are bullshitters. As Frankfurt points out in “On Bullshit,” bullshit is worse than a lie. The bullshitter does not care about the truth. Their narrative is posedas a means to an end. This shifts the dial from incompetence to unethical. In other words, there is the likelihood that the attack on this work was completely cynical. Mediocrity and malice look very similar. It is simply some bullshit created to censor it; hide it, and keep it from view. The management cares nothing about the truth or the quality of work. They simply want the fastest, cheapest path to success. Like so many examples today, bullshit is merely a means to an end. The enemy of bullshit is the expert. In this case, that was me, and I needed to be silenced. Managers have lots of power to do this, and they exercised it.
After calling it out, I learned two things. First, their critiques remained the same (incompetent and naive). The management would publish the report, but under duress. It still sits unpublished. If it does get published, it will be semi-classified. What this means is it will be CUI (controlled unclassified information under the guise of export control. This is an absurd and unjustified category for the report. In other words, this is more bullshit. The document is purely unclassified. It is the results of unclassified analytical problems solved with an unclassified computer code. Nothing about the results is remotely sensitive. The only sensitivity is the bad results. It is corrupt on the face of it. I will note that CTH results that are closer to sensitive are regularly published. For example, this would be application work involving high-explosive modeling (a quick Google search can confirm this).
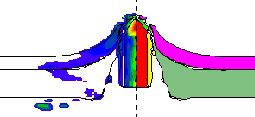
The only reason to make it CUI is to hide it. Make it as invisible as possible. This purpose is completely corrupt and underlies their unethical behavior. This sort ofcorruption is so commonplace today that no one notices it any longer. It is all part of the export control law (a completely stupid piece of shit law). All it really does is harm our national security in the name of protecting it. It is a way of hiding things from view that should be dealt with. Instead, they have an excuse for doing nothing. We make far too many decisions for purely superficial and/or corrupt reasons.
“Anti-intellectualism has been a constant thread winding its way through our political and cultural life, nurtured by the false notion that democracy means that ‘my ignorance is just as good as your knowledge.’”
― Isaac Asimov
The program that paid for the work and report was unhappy as well. They also decided that the issues exposed by the work needed no attention either. This is incredibly irresponsible. The problem for me is that the management decided that I was the problem, not the censorship or the lack of credibility. An important code with a fatal flaw could just be ignored. In the end, it mostly looks like reasons to doubt Sandia’s fitness for work like this. Not because they can’t do the right thing, but because they won’t.
Unfortunately, the other Lab working on the applied problem didn’t cover themselves with glory either. They withheld information from Sandia essential for proper modeling. Again, they have bullshit reasons for withholding the information. They can justify it in terms of bias and a self-serving reading of rules. It is also an internal conflict that only harms our National security. Sandia does the same thing to the other Labs too. Both Labs are acting in a manner our Nation’s enemies would approve of.
Why would I want to continue wasting my time with these useless people?
Time for Me to Go
At this point, I thought things were over and done. I went on vacation to Spain, easing my mind from this debacle. Then I found out what action management would take. They decided to come after me. Fortunately, I was warned. I took action to protect myself, but if management wants to hurt you, they will. Nothing stands in their way, and they have carte blanche. Worse yet, they know they have impunity. It was the moment of the warning that I decided to retire. I also took the blog down to lessen Sandia’s ability to hurt me. This didn’t stop them; it just lessened the degree of damage. I already had a sense of their malice toward me. If managers are incompetent, unethical, and irresponsible, nothing will stop them.
Soon I learned their first action. I had a written reprimand over a nothing post from Facebook (they made a nonsense claim about a policy). The comment was about a particularly incompetent and harmful cybersecurity measure. The policy announcement was an e-mail nowhere marked as sensitive in any way (catching on to a theme?). Given Sandia’s tendency to overclassify everything, this is notable. They mark things as CUI at the drop of a hat (see above). It was another bit of form over substance. They decided to make things “look” more secure all the while making it less secure in reality. There is a toxic symmetry in these events too.
To make matters worse, they gave me a really shitty performance review. I had already decided to be silent in all things at work for my remaining time. So these actions were just insult to injury. There was a lot to push back on as the review was complete bullshit. I had been restrained and respectful professionally with the issues around CTH. They instead had shown little or now respect for me. I was ignored as an SME. In a sense my review accused me of everything they were guilty of. The way they go after you is dripping with hypocrisy. Their accusations are actually admissions.
“I cannot and will not cut my conscience to fit this year’s fashions.” ― Lillian Hellman
A note of perspective about Sandia. In the context of the current USA, Sandia is a good place to work. Yes, I am damning with faint praise. If you’re the right kind of person, it is a super place. It was not a place I would ever fit into. I’ve known this for years and years, but thought I could overcome it. This was a fool’s errand. That said, these issues are not isolated at all. The USA is in serious trouble from this sort of governance. Sandia is just on local exemplar. Like Sandia, the USA are setting ourselves up for complete failure.
These events had a certain inevitability. As long as I held to my standards and values, a clash was certain. Unless I completely capitulated to their will, it would end up with me on the short end of it. Anyone like me is destined to lose.
“Life is rarely about what happened; it’s mostly about what we think happened.” ― Chuck Klosterman

The First Time I Stopped
“Threats are the last resort of a man with no vocabulary.” ― Tamora Pierce
I should have known better. Somehow, I still had faith in Sandia. That was so goddamn naive. In the recent episode, I realized that the problems with ethics and irresponsibility were far broader and more common. In a way, it moves from a condemnation of one person to a red flag about the entire organization. Other friends have lent me their stories of corruption, too. The Lab has a huge problem, and there is no sign they recognize it or are doing anything about it.I felt the first blog stoppage was localizedto the actions of one executive, instead of a pattern. The only solace in seeing this pattern is a modicum of redemption for one deceased manager, Scott. He was just part of a system that brought out the worst in him. It is probably the same with the managers I just tangled with.
I wrote the blog from 2013 to 2018 with regularity and passion. It still stands as the best thing I did at Sandia. Ultimately, my critique of the Exascale program became too much for management to take. I was softly encouraged to stop and didn’t get the message, so they stopped me by force. Management could have ordered me to stop, as in recent events. In that case, they chose the path of anonymity of an ethics investigation. An important thing to recognize is that corporate ethics is not ethical. Corporate policy defines what is ethical. Corporate ethics is there to protect the corporate interests. Fuck the employee, and actual ethics be damned.
When Ethics contacted me, I initially thought that it was related to my encounter with an appalling episode of terrible peer review. Again, I was naive. Sandia Corporate Ethics doesn’t give a fuck about peer review. It was about going after me. Their biggest concern revolved around whether I was making money off ads that WordPress added to posts. No, I wasn’t; the ads are the price of a free service. Take note of their interest in whether I was making money from this. It shows the mindset clearly. The fact that the blog was above board mattered not one iota. It had been done with permission and advertised in my official performance documents. I put links to the blog in my public presentations. The entire problem was the opinions I had that departed from my manager’s. They wanted to shut me up and punish me.
At the end, I got a written reprimand. I stopped the blog. I am convinced that an executive from Sandia reported me to ethics. I suspected my Director Scott was that person. Someone who could have just told me to stop. He chose to do this in a way that didn’t implicate himself. Other managers were the “bag men” giving me the reprimand. In the process, all the trust and confidence in those people were lost. The management showed absolutelyno loyalty to staff. They now believe that loyalty and trust is agreement on all things, or absolute silence about disagreements. Ironically, it is an environment that is completely antithetical to peer review. It is utterly damning.
“The greatest threat to freedom is the absence of criticism.” ― Wole Soyinka

Why Did I Start the Blog in the First Place
“Be yourself; everyone else is already taken.”
― Oscar Wilde
Back in 2013, I was engaged in my usual performance review with my manager, Randy. One of the things that had become frustrating at Sandia was defining my professional development path. To be blunt, almost nothing made sense. I rapidlyfound that Sandia already had little or no interest, or use for the expertise I already possessed. This theme is actually central and consistent for the entire period.
“Why fit in when you were born to stand out?”
― Dr. Seuss
This should strike everyone as being a bit insane. Sandia is a nuclear weapons Lab. The National Nuclear Weapons Stockpile is its prime mission. This was a key part of my expertise. I am an expert in computer codes used for the stewardship of the stockpile. My particular expertise is in shock physics for this mission. I am also an expert in how modeling and simulation are used for this mission broadly. I know a lot about the stockpile itself, too. Another part of this is expertise in verification and validation. How fitting is itis that the assemblage of all this expertise was the trigger for the end of my career! Sandia showed little or no interest or use for this expertise at any point in my employment.
The reason expertise is not valued is complex. Chief among the reasons is the complexity and technical depth of the knowledge. Solving problems is deeply technical and expensive. It is far faster and cheaper to shoot the messenger (you are far too critical!). Worse yet, solving problems takes time and money. Why solve a problem when you can bury it, or simplymessage your way around it? For the management today, the answer is bury the problem and simply lie about it. Rely upon the technical authority of your institution to paper over all problems. Trade the institution’s trust and reputation for the easy way out of things.
What was the point of learning anything new? What could I do to become a better professional or better scientist? Write! To become a better writer, one needs to write. It is a craft that is refined by practice. Moreover, writing is a way to think. I am a firm believer that I was on staff at the Lab to be a deep thinker about science and its application to National Security. I labored under the false belief that good quality thinking was valued. It is not!
What I decided was a process where I would write regularly. Writing is a skill. Writing well is also thinking clearly. The act of writing is a way of thinking deeply and then communicating that thought. I have found that a key part of writing is the habit of it. Another key is that you write to be read by others. The blog was a mechanism to do exactly that. Write to be read and understood by others.
“Living with integrity means: Not settling for less than what you know you deserve in your relationships. Asking for what you want and need from others. Speaking your truth, even though it might create conflict or tension. Behaving in ways that are in harmony with your personal values. Making choices based on what you believe, and not what others believe.”
–Barbara De Angelis
My blog posts were all work-related. Some of them were technical and “nerdy.” Some of them talked about our programs and science in general. This is part of the work. Nuclear weapons are and have always been political. In many respects, they are the most political technology. Talking about politics and our programs is a bit dangerous. It is also essential to do. My ideas are not always correct, but worth thinking about. In this dynamic are the seeds of the conflict that ended my working career.


A Perspective On Sandia
When I moved to Sandia 19 years ago, it was to a premier National institution that served the Nation. To some extent, this is exactly what I found. It was also in decline. All the Labs are. Los Alamos was in decline, too, and it has continued to be. That decline has been accelerating with each passing year. I have met and worked with many outstanding scientists and been able to contribute to the National security. Some of the best managers I’ve ever worked with were (are) at Sandia. Most of these people are wonderful. Many people’s friendships I treasure and have gained my respect. These people are exactly who I expected to meet and work with.
“Imaginary evil is romantic and varied; real evil is gloomy, monotonous, barren, boring. Imaginary good is boring; real good is always new, marvelous, intoxicating.”
― Simone Weil
I have also encountered some of the worst managers I’ve ever known. As I discussed, these managers are irresponsible and unethical. As managers and leaders, this renders them utterly incompetent. Given the responsibility that Sandia is given to the nation, this should horrify all of us. These managers also seem to act with impunity, and their irresponsible acts even lead to success at Sandia, instead of rejection. They are unfit to lead an institution this important or with these responsibilities.
Under these conditions, it is easy to see why American superiority in science and technology has faded and fallen. All ofthis is part of a broad enshitification of American institutions. I believethis enshitification is driven byfocus on money over all other concerns. That focus on money revolves around information control and the use of that information for profit and power. Unless we change our incentives, the declines will continue, if not accelerate.

When I took the blog down, it coincided with my decision to retire. A realization had set in about the dissonance of my values from Sandia leadership. I have believed that competent, responsible, and ethical technical-scientific effort support National security. My leadership believes and demonstrates none of these values. They have discovered that it is far more efficient, fast, and cost-effective to redefine the truth. Admitting and then solving problems is expensive and time-consuming. It also involves competence and responsible action that they cannot execute. In short, I did not want to be associated with Sandia any longer. I am happy to be gone. I am quite sad about how I left. I am sad for the capable and decent people left behind in this broken system.
A core concept in the current state of American life is transactional relationships. Everything is about quid pro quo. This is what gives Trump power. This is what my managers do. Money as the object makes all things transactional and crushes every other principle in its wake. Principles of correctness, equality, and actual patriotism are all swept aside. The transactional principle has become damning to the future of my institutions and my country itself. We live in an extraordinary time. It is a time of extraordinary promise and extraordinary danger. If we navigate this time with transactional principles instead of deeper, more positive principles distaster awaits us. It is time for us to recognize how damning these transactional principles are and turn away.
Postscript
I’ve asked myself over and over, “Did I do the right thing? Was it right to speak out? Or did I violate some norm?” The answer is, I did the right thing, and I did violate a norm. I paid the price for violating that norm. I could have just kept quiet and left without saying anything. Just voted with my feet. That would have allowed the norm violation that my managers were committing to go unopposed. I wouldn’t take a stand. So, I walk out with my head held high. I have a standard, and I adhered to it.
The truth is that management today works in a system that encourages them to do the wrong thing. Encourages them to simply paper over problems, ignore peer review, and go on as if this were success. They have no interest in solving problems. They do not have the resources to solve problems and don’t do what’s necessary to get the resources to solve problems. As such, the problems persist. Worse yet, the problems get worse and become problems you know about but do nothing about.
I think a great deal about the incentive system in place. The current system is full of terrible incentives that bring the worst out in people. They also bring out the worst in institutions. All of this is, in turn, bringing out the worst in the United States. I see it normalizing and encouraging the awful behavior I have witnessed. It is easy to see that the incentives have created something that I don’t want to be part of, but have no choice.
The decline in the scientific prowess of the United States can be tied to these same incentives. My career has seen a precipitous decline in American science and its key institutions. We have lost our superiority to the Chinese in science. The incentives are to blame and have undermined and destroyed all the advantages of our system. The sad thing is that it’s not the Chinese competence that has beaten us, but it is ourselves that have beaten us. This has been a series of “own goals,” as it were. These own goals started well before the current year and the damage done by the Trump administration. They have only accelerated a process that began decades ago.
This gets to what the norms of today are: that our leaders and managers are in control, and the best way to succeed as a worker is to become one of them. Instead of that, you follow directions, you follow the orders, no matter whether the orders and directions are good, ethical, or appropriate. Basically, you’re a drone. You have no free will, and success comes by simply following the will of your superiors. This is the norm of today, and this norm is corrosive. It destroys trust, it destroys competence, and ultimatelyrewards an appalling form of mediocrity that is now sprawling across our entire society.
“I have always felt that violence was the last refuge of the incompetent, and empty threats the last sanctuary of the terminally inept.” ― Neil Gaiman