
Maturity, one discovers, has everything to do with the acceptance of ‘not knowing.
― Mark Z. Danielewski
U ncertainty quantification is a hot topic. It is growing in importance and practice, but people should be realistic about it. It is always incomplete. We hope that we have captured the major forms of uncertainty, but the truth is that our assumptions about simulation blind us to some degree. This is the impact of “unknown knowns” the assumptions we make without knowing we are making them. In most cases our uncertainty estimates are held hostage to the tools at our disposal. One way of thinking about this looks at codes as the tools, but the issue is far deeper actually being the basic foundation we base of modeling of reality upon.
ncertainty quantification is a hot topic. It is growing in importance and practice, but people should be realistic about it. It is always incomplete. We hope that we have captured the major forms of uncertainty, but the truth is that our assumptions about simulation blind us to some degree. This is the impact of “unknown knowns” the assumptions we make without knowing we are making them. In most cases our uncertainty estimates are held hostage to the tools at our disposal. One way of thinking about this looks at codes as the tools, but the issue is far deeper actually being the basic foundation we base of modeling of reality upon.
… Nature almost surely operates by combining chance with necessity, randomness with determinism…
― Eric Chaisson
 One of the really uplifting trends in computational simulations is the focus on uncertainty estimation as part of the solution. This work is serving the demands of decision makers who increasingly depend on simulation. The practice allows simulations to come with a multi-faceted “error” bar. Just like the simulations themselves the uncertainty is going to be imperfect, and typically far more imperfect than the simulations themselves. It is important to recognize the nature of imperfection and incompleteness inherent in uncertainty quantification. The uncertainty itself comes from a number of sources, some interchangeable.
One of the really uplifting trends in computational simulations is the focus on uncertainty estimation as part of the solution. This work is serving the demands of decision makers who increasingly depend on simulation. The practice allows simulations to come with a multi-faceted “error” bar. Just like the simulations themselves the uncertainty is going to be imperfect, and typically far more imperfect than the simulations themselves. It is important to recognize the nature of imperfection and incompleteness inherent in uncertainty quantification. The uncertainty itself comes from a number of sources, some interchangeable.
Sometimes the hardest pieces of a puzzle to assemble, are the ones missing from the box.
― Dixie Waters
Let’s explore the basic types of uncertainty we study:
Epistemic: This is the uncertainty that comes from lack of knowledge. This could be associated with our imperfect modeling of systems and phenomena, or materials. It could come from our lack of knowledge regarding the precise composition and configuration of the systems we study. It could come from the lack of modeling for physical processes or features of a system (e.g., neglecting radiation transport, or relativistic effects). Epistemic uncertainty is the dominant form of uncertainty reported because tools exist to estimate it, and it treats simulation codes like “black boxes”.
 Aleatory: This is uncertainty due to the variability of phenomena. This is the weather. The archetype of variability is turbulence, but also think about the detailed composition of every single device. They are all different in some small degree never mind their history after being built. To some extent aleatory uncertainty is associated with a breakdown of continuum hypothesis and is distinctly scale dependent. As things are simulated at smaller scales different assumptions must be made. Systems will vary at a range of length and time scales, and as scales come into focus their variation must be simulated. One might argue that this is epistemic, in that if we could measure things precisely enough then it could be precisely simulated (given the right equations, constitutive equation and boundary conditions). This point of view is rational and constructive only to a small degree. For many systems of interest chaos reigns and measurements will never be precise enough to matter. By and large this form of uncertainty is simply ignored because simulations can’t provide information.
Aleatory: This is uncertainty due to the variability of phenomena. This is the weather. The archetype of variability is turbulence, but also think about the detailed composition of every single device. They are all different in some small degree never mind their history after being built. To some extent aleatory uncertainty is associated with a breakdown of continuum hypothesis and is distinctly scale dependent. As things are simulated at smaller scales different assumptions must be made. Systems will vary at a range of length and time scales, and as scales come into focus their variation must be simulated. One might argue that this is epistemic, in that if we could measure things precisely enough then it could be precisely simulated (given the right equations, constitutive equation and boundary conditions). This point of view is rational and constructive only to a small degree. For many systems of interest chaos reigns and measurements will never be precise enough to matter. By and large this form of uncertainty is simply ignored because simulations can’t provide information.
Numerical: Simulations involve taking a “continuous” system and cutting them up into discrete pieces. Insofar as the equations describe reality the solutions should approach a correct solution as these pieces get more numerous (and smaller). This is the essence of mesh refinement. Computational simulation is predicated upon this notion to an increasingly ridiculous degree. Regardless of the viability of the notion, the approximations made numerically are a source of error to be included in any error bar. Too often these errors are ignored, wrongly assumed to be small, or incorrectly estimated. There is no excuse for this today.
bar. Too often these errors are ignored, wrongly assumed to be small, or incorrectly estimated. There is no excuse for this today.
Users: the last sources of uncertainty examined are the people who use codes and construct models to be solved. As problem complexity grows the decisions in modeling become more subtle and prone to variability. Quite often modelers of equal skill will come up with distinctly different answers or uncertainties. Usually a problem is only modeled once, so this form of uncertainty (or the requisite uncertainty on the uncertainty) is completely hidden from view. Unless there is an understanding of how the problem definition and solution choices impact the solution, the uncertainty will be unquantified. Knowledge of this uncertainty is almost always larger for complex problems where it is less likely for the simulations to be conducted by independent teams. Studies have shown this to be as large or larger than other sources! Almost the only place this has received any systematic attention is nuclear reactor safety analysis.
As far as the laws of mathematics refer to reality, they are not certain; and as far as they are certain, they do not refer to reality.
― Albert Einstein
One has to acknowledge that the line between epistemic and aleatory is necessarily fuzzy. In a sense the balance is tipped toward epistemic because of the tools exist to study it. At some level this is a completely unsatisfactory state of affairs. Some features of systems arise from the random behavior of the constituent parts of the system. Systems and their circumstances are just a little different, and these differences yield differences (sometimes slight) in the response. Sometimes these small differences create huge changes in the outcomes. It is these huge changes that drive a great deal of worry in decision-making. Addressing these issue is a huge challenge for computational modeling and simulation; a challenge that we simply aren’t addressing at all today.
Why?
The assumption of an absolute determinism is the essential foundation of every scientific enquiry.
― Max Planck
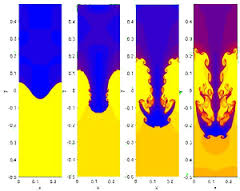 A large part of the reason for failing to address these matters is the implicit, but slavish devotion to determinism. Simulations are almost always viewed as the solution to a deterministic problem. This means there is AN answer. Answers are almost never sought in the sense of a probability distribution. Even probabilistic methods like Monte Carlo are trying to approach the deterministic solution. Reality is almost never AN answer and almost always a distribution. What we end up solving is the mean expected response of a system to the average circumstance. What is actually observed is a distribution of responses to a distribution of circumstances. Often the real question to answer in any study (with or without simulation) is what’s the worse that can reasonably happen? A level of confidence that says 95% or 99% of the responses will be less than some bad level usually defines the desired result. This sort of question is best thought of as aleatory, and our current simulation capability doesn’t begin to address it.
A large part of the reason for failing to address these matters is the implicit, but slavish devotion to determinism. Simulations are almost always viewed as the solution to a deterministic problem. This means there is AN answer. Answers are almost never sought in the sense of a probability distribution. Even probabilistic methods like Monte Carlo are trying to approach the deterministic solution. Reality is almost never AN answer and almost always a distribution. What we end up solving is the mean expected response of a system to the average circumstance. What is actually observed is a distribution of responses to a distribution of circumstances. Often the real question to answer in any study (with or without simulation) is what’s the worse that can reasonably happen? A level of confidence that says 95% or 99% of the responses will be less than some bad level usually defines the desired result. This sort of question is best thought of as aleatory, and our current simulation capability doesn’t begin to address it.
When your ideas shatter established thought, expect blowback.
― Tim Fargo
The key aspect of this entire problem is a slavish devotion to determinism in modeling. Almost every modeling discipline sees the solution being sought as being utterly deterministic. This is lo gical if the conditions being modeled are known with exceeding precision. The problem is that such precision is virtually impossible for any circumstance. This is the core of the problem with simulating the aleatory uncertainty that so frequently remains untreated. It is almost completely ignored by a host of fundamental assumption in modeling that is inherited by simulations. These assumptions are holding back real progress in a host of fields of major importance.
gical if the conditions being modeled are known with exceeding precision. The problem is that such precision is virtually impossible for any circumstance. This is the core of the problem with simulating the aleatory uncertainty that so frequently remains untreated. It is almost completely ignored by a host of fundamental assumption in modeling that is inherited by simulations. These assumptions are holding back real progress in a host of fields of major importance.
Finally we must combine all these uncertainties to get our putative “error bar”. There are a number of ways to go about this combination with varying properties. The most popular knee-jerk approach is to use the root mean square of the contributions (square root of the sum of the squares). The sum of the absolute values would be a better and safer choice, since it is always larger (hence more conservative) than the sum of squares. If you’re feeling cavalier and want to play it dangerous, just use the largest uncertainty. Each of these choices is related to probabilistic assumptions, which in the case of sum of squares is assuming a normal distribution.
It is impossible to trap modern physics into predicting anything with perfect determinism because it deals with probabilities from the outset.
― Arthur Stanley Eddington
One of the most pernicious and deepening issues associated with uncertainty quantification is “black box” thinking. In many cases the simulation code is viewed as being a black box where the user knows very about its workings beyond a purely functional level. This often results in generic and generally uninformed decisions being made on uncertainty. The expectations of the models and numerical methods are understood only superficially, and this results in a superficial uncertainty estimate. Often the black box thinking extends to the tool used to get uncertainty too. We then get the result from a superposition of two black boxes. Not a lot light bets shed on reality in the process. Numerical errors are ignored, or simply misdiagnosed. Black box users often simply do a mesh sensitivity study, and assume that small changes under mesh variation are indicative of convergence and small errors. They may or may not be such evidence. Without doing a more formal analysis this sort of conclusion is not justified. If code and problem is not converging, the small changes may be indicative of very large numerical errors or even divergence and a complete lack of control.
methods are understood only superficially, and this results in a superficial uncertainty estimate. Often the black box thinking extends to the tool used to get uncertainty too. We then get the result from a superposition of two black boxes. Not a lot light bets shed on reality in the process. Numerical errors are ignored, or simply misdiagnosed. Black box users often simply do a mesh sensitivity study, and assume that small changes under mesh variation are indicative of convergence and small errors. They may or may not be such evidence. Without doing a more formal analysis this sort of conclusion is not justified. If code and problem is not converging, the small changes may be indicative of very large numerical errors or even divergence and a complete lack of control.
Whether or not it is clear to you,
no doubt the universe is unfolding
as it should.
― Max Ehrmann
The answer to this problem is deceptively simple make things “white box” testing. The problem is that making our black boxes into white boxes is far from simple. Perhaps the hardest thing about this is having people doing the modeling and simulation with sufficient expertise to treat the tools as white boxes. A more reasonable step forward is for people to simply realize the dangers inherent in black box testing mentality.
Science is a way of thinking much more than it is a body of knowledge.
― Carl Sagan
In many respects uncertainty quantification is in its infancy. The techniques are immature and terribly incomplete. Beyond this character, we are deeply tied to modeling philosophies that hold us back from progress. The whole field needs to mature and throw off the shackles imposed by the legacy of Newton and the entire rule of determinism that still holds much of science under its spell.
The riskiest thing we can do is just maintain the status quo.
― Bob Iger

“The techniques are immature and terribly incomplete.” I think this statement misses the point, and it may or may not be valid. Most of the mathematical techniques are anywhere from 50 to 5000 years old. Their application, implementation, and interpretation in the context of “uncertainty quantification” is the part that’s immature. In my experience working with modelers, they usually cannot precisely define “uncertainty” in their application. If they could write down a precise mathematical definition of their uncertainty, then we could discuss available techniques to estimate that quantity. Or I could determine that the precise quantity they want to compute is not computable to sufficient accuracy in any reasonable computational budget (e.g., computing variance as a high dimensional integral).
Again, in my experience, broad classifications of uncertainty types (e.g., epistemic versus aleatory) do little to help the modelers define their application’s uncertainty as a precise mathematical statement (e.g., an integral or a density function or a derivative). They also do little to help the methods person, since there is no concrete map from uncertainty type to computational method (e.g., epistemic to numerical quadrature). Some such maps have manifested in practice (e.g., the precise relationship between epistemic versus aleatory in Dakota), but, in my opinion, these maps are a result of pressures for computable “error bars” more than careful consideration and definition of uncertainty in a particular application.
Broadly speaking, the UQ community has neglected the voice and experience of statisticians, who’ve been modeling uncertainty for a hundred years. Flipping the coin, however, the statisticians don’t understand the complexities (in particular, the assumptions) of the physicists/engineers trying to model “reality” with math (e.g., conservation laws). Nor do they appreciate centuries of the asymptotic statements from numerical analysts and approximation theorists studying discrete approximations of continuous models. The statisticians have data, models, parameters, and noise—all precisely defined terms—but numerical simulation of physical systems doesn’t always fit nicely into those terms.
Paul, I’m gratified by getting a response like this. Viva the debate! I really strongly agree with the statistics disconnect and general neglect. One of my main points is that the point of view in modeling is really focused on deterministic “mean field” solutions, and increasingly questions are associated with what is going on in the tails of the PDFs. Generally black box thinking will make NO progress on such questions, but such questions are central to the future impact of modeling and simulation.