
Never attribute to malevolence what is merely due to incompetence
― Arthur C. Clarke
 A year ago, I sat in one of my manager’s office seething in anger. After Trump’s election victory, my emotions shifted from despair to anger seamlessly. At that particular moment, it was anger that I felt. How could the United States possibly have elected this awful man President? Was the United States so completely broken that Donald Trump was a remotely plausible candidate, much less victor.
A year ago, I sat in one of my manager’s office seething in anger. After Trump’s election victory, my emotions shifted from despair to anger seamlessly. At that particular moment, it was anger that I felt. How could the United States possibly have elected this awful man President? Was the United States so completely broken that Donald Trump was a remotely plausible candidate, much less victor.
Is ours a government of the people, by the people, for the people, or a kakistocracy rather, for the benefit of knaves at the cost of fools?
― Thomas Love Peacock
 Apparently, the answer is yes, the United States is that broken. I said something to the effect that we too are to blame for this horrible moment in history. I knew that both of us voted for Clinton, but felt that we played our own role in the election of our reigning moron-in-chief. Today a year into this national nightmare, the nature of our actions leading to this unfolding national and global tragedy is taking shape. We have grown to accept outright incompetence in many things, and now we have a genuinely incompetent manager as President. Lots of incompetence is accepted daily without even blinking, I see it every single day. We have a system that increasingly renders, the competent, incompetent by brutish compliance with directives born of broad-based societal dysfunction.
Apparently, the answer is yes, the United States is that broken. I said something to the effect that we too are to blame for this horrible moment in history. I knew that both of us voted for Clinton, but felt that we played our own role in the election of our reigning moron-in-chief. Today a year into this national nightmare, the nature of our actions leading to this unfolding national and global tragedy is taking shape. We have grown to accept outright incompetence in many things, and now we have a genuinely incompetent manager as President. Lots of incompetence is accepted daily without even blinking, I see it every single day. We have a system that increasingly renders, the competent, incompetent by brutish compliance with directives born of broad-based societal dysfunction.
In a hierarchy, every employee tends to rise to his level of incompetence.
― Laurence J. Peter
What does the “Peter Principle” say about the United States? The President is incompetent. Not just a little bit, he is utterly and completely unfit for the job he has. He is the living caricature of a leader, not actually one. His whole shtick is loudly and brashly sounding like what a large segment of the population thinks a leader should be. Under his leadership, our government has descended into the theatre of the absurd. He doesn’t remotely understand our system of government, economics, foreign policy,  science, or really anything other than marketing himself. His is an utterly self-absorbed anti-intellectual completely lacking empathy and the basic knowledge we should expect him to have. The societal destruction wrought by this buffoon-in-chief is profound. Our most important institutions are being savaged. Divisions in society are being magnified and we stand on the brink of disaster. The worst thing is that this disaster is virtually everyone’s fault whether you stand on the right or the left, you are to blame. The United States was in a weakened state and the Trump virus was poised to infect us. Our immune system was seriously compromised and failed to reject this harmful organism.
science, or really anything other than marketing himself. His is an utterly self-absorbed anti-intellectual completely lacking empathy and the basic knowledge we should expect him to have. The societal destruction wrought by this buffoon-in-chief is profound. Our most important institutions are being savaged. Divisions in society are being magnified and we stand on the brink of disaster. The worst thing is that this disaster is virtually everyone’s fault whether you stand on the right or the left, you are to blame. The United States was in a weakened state and the Trump virus was poised to infect us. Our immune system was seriously compromised and failed to reject this harmful organism.
I love the poorly educated.
– Donald Trump
Sorry losers and haters, but my I.Q. is one of the highest -and you all know it! Please don’t feel so stupid or insecure, it’s not your fault.
– Donald Trump
Trump is making everything worse. One of the keys to understanding the damage being done to the United States is seeing the poor condition of Democracy prior to the election. A country doesn’t just lurch toward such a catastrophic decision overnight, we were already damaged. In a sense, the body politic was already weakened and ripe for infection. We have gone through a period of more than 20 years of massive dysfunction led by the dismantling of government as a force for good in society. The Republican party is committed to small government, and part of their approach is to attack it. Government is viewed as an absolute evil. Part of the impact of this is the loss of competence in governing. Any governmental incompetence supports their  argument about the need to diminish it. The result has been a steady march toward dysfunction and poor performance along with deep seated mistrust, if not outright distain.
argument about the need to diminish it. The result has been a steady march toward dysfunction and poor performance along with deep seated mistrust, if not outright distain.
All of this stems from deeper wounds left in our history. The deepest wound is the Civil War and the original national sin of slavery. The perpetuation of institutional racism is one of the clearest forces driving our politics. We failed to heal the wounds of this war, and continue to wage a war against blacks. First through the scourge of Jim Crow laws, and now with the war on drugs with its mass incarceration. Our massive prison population is driven by our absurd and ineffective efforts to combat drug abuse. We actively avoid taking actions that would be effective in battling drug addiction. While it is a complete failure as a public health effort, it is a massively effective tool of racial oppression. More recent wounds were left by the combination of the Vietnam war and Civil rights movement in the 1960’s along with Watergate and Nixon’s corruption. The Reagan revolution and the GOP attacks on the Clinton’s were their revenge for progress. In a very real way the country has been simmering in action and reaction for the last 50 years. Trump’s election was the culmination of this legacy and our inability to keep the past as history.
Government exists to protect us from each other. Where government has gone beyond its limits is in deciding to protect us from ourselves.
― Ronald Reagan





Part of the hardest aspect of accepting what is going on comes in understanding how Trump’s opposition led to his victory. The entire body politic is ailing. The Republican party is completely inept at leading, unable to govern. This shouldn’t come as any surprise; the entire philosophy of the right is that government is bad. When your a priori assumption is that government is inherently bad, the nature of your governance is half-hearted. A natural outgrowth of this philosophy is rampant incompetence in governance. Couple this to a natural tendency toward greed as a core value, and you have the seeds of corruption. Corruption and incompetence is an apt description of the Republican party. The second part of this toxic stew is hate and fear. The party has spent decades stoking racial and religious hatred, and using fear of crime and terrorism to build their base. The result is a governing coalition that cannot govern at all. They are utterly incompetent, and no one more embodies their incompetence than the current President.
There is a cult of ignorance in the United States, and there has always been. The strain of anti-intellectualism has been a constant thread winding its way through our political and cultural life, nurtured by the false notion that democracy means that ‘my ignorance is just as good as your knowledge.
― Isaac Asimov
 The Democrats are no better other than some basic human capacity for empathy. For example, the Clintons were quite competent, but competence is something we as a nation don’t need any more, or even believe in. Americans chose the incompetent candidate for President over the competent one. At the same time the Democrats feed into the greedy and corrupt nature of modern governance with a fervor only exceeded by the Republicans. They are what my dad called “limousine liberals” and really cater to the rich and powerful first and foremost while appealing to some elements of compassion (it is still better than “limousine douchebags” on the right). As a result the Democratic party ends up being only slightly less corrupt than the Republican while offering none of the cultural red meat that drives the conservative culture warriors to the polls.
The Democrats are no better other than some basic human capacity for empathy. For example, the Clintons were quite competent, but competence is something we as a nation don’t need any more, or even believe in. Americans chose the incompetent candidate for President over the competent one. At the same time the Democrats feed into the greedy and corrupt nature of modern governance with a fervor only exceeded by the Republicans. They are what my dad called “limousine liberals” and really cater to the rich and powerful first and foremost while appealing to some elements of compassion (it is still better than “limousine douchebags” on the right). As a result the Democratic party ends up being only slightly less corrupt than the Republican while offering none of the cultural red meat that drives the conservative culture warriors to the polls.
In individuals, insanity is rare; but in groups, parties, nations and epochs, it is the rule.
― Friedrich Nietzsche
The thing that sets the Democratic party back is a complete lack unity or discipline. They are fractious union of special interests that can barely tolerate one another. They cannot unify to help each other, and each faction is single issue group that can’t be bothered to form an effective coalition. The result is a party that is losing despite holding a majority of the votes. Many of the Democratic voters can’t be bothered to even vote. This losing coalition has let GOP driven fear and hate win along with a systematic attack on our core values as a democratic republic (vast sums of money in politics, voter rights, voter suppression, and gerrymandering). They are countered by a Republican party that is unified and supporting of their factions. The different factions work together to form a winning coalition in large part through accepting each other’s extreme views as part of their rubric of beliefs.\
 While both parties cater to the greedy needs of the rich and powerful, the differences in the approach is completely seen in the approach to social issues. The Republicans appeal to traditional values along with enough fear and hate to bring the voters out. They stand in the way of scary progress and the future as the guardians of the past. They are the force that defends American values, which means white people and Christian values. With the Republicans, you can be sure that the Nation will treat those we fear and hate with violence and righteous anger without regard to effectiveness. We will have a criminal justice system that exacts vengeance on the guilty, but does nothing to reform or treat criminals. The same forces provide just enough racially biased policy to make the racists in the Republican ranks happy.
While both parties cater to the greedy needs of the rich and powerful, the differences in the approach is completely seen in the approach to social issues. The Republicans appeal to traditional values along with enough fear and hate to bring the voters out. They stand in the way of scary progress and the future as the guardians of the past. They are the force that defends American values, which means white people and Christian values. With the Republicans, you can be sure that the Nation will treat those we fear and hate with violence and righteous anger without regard to effectiveness. We will have a criminal justice system that exacts vengeance on the guilty, but does nothing to reform or treat criminals. The same forces provide just enough racially biased policy to make the racists in the Republican ranks happy.
The Democrats stand for a progressive and empathic future that is represented by many different groups each with their own specific grievances. One of the biggest problems on both sides is intolerance. This might be expected on the right, after all white supremacy is hardly a tolerant world view. The left helps the right out by being even less tolerant. The left’s factions cannot tolerate any dissent, on any topic. We hear endless whining about micro-aggressions, and cultural appropriation along with demands for political correctness. They are indeed “snowflakes” who are incapable of debate and standing up for their beliefs. When they don’t like what someone has to say, they attack them and completely oppose the right to speak. The lack of tolerance on the left is one of the forces that powered Trump to the White House. It did this through a loss of any moral high ground, and the production of a divided and ineffective liberal movement. The left has science, progress, empathy and basic human decency on their side yet continue to lose. A big part of their losing strategy is the failure to support each other, and engage in an active dialog on the issues they care so much about.
correctness. They are indeed “snowflakes” who are incapable of debate and standing up for their beliefs. When they don’t like what someone has to say, they attack them and completely oppose the right to speak. The lack of tolerance on the left is one of the forces that powered Trump to the White House. It did this through a loss of any moral high ground, and the production of a divided and ineffective liberal movement. The left has science, progress, empathy and basic human decency on their side yet continue to lose. A big part of their losing strategy is the failure to support each other, and engage in an active dialog on the issues they care so much about.
A dying culture invariably exhibits personal rudeness. Bad manners. Lack of consideration for others in minor matters. A loss of politeness, of gentle manners, is more significant than is a riot.
― Robert A. Heinlein
The biggest element in Trump’s ascension to the Presidency is our acceptance of incompetence in our leaders. We accept incompetence too easily; incompetence is promoted across society. We have lost the ability to value and reward expertise and competence. Part of this can be blamed on the current culture where marketing is more important than substance. Trump is pure marketing. His entire brand is himself, sold to people who have lost the ability to smell the con. A big part of the appeal of Trump was the incompetence of governing that permeates the Republican view.
This is where the incompetence and blame comes to work. Success at work depends little on technical success because technical success can be faked. What has become essential at work is compliance with rules and control of our actions. Work is not managed, our compliance with rules is managed. Increasingly the incompetence of the government is breeding incompetence at my work. The government agency that primarily runs my Lab is a complete disaster. We have no leadership either management or science. Both are wrought by the destructive tendency of the Republican party that makes governing impossible. They are a party of destruction, not creation. When Republicans are put in power they can’t do anything, their entire being is devoted to taking things apart. The Democrats are no better because of their devotion to compliance, regulation and compulsive rule following without thought. This tendency is paired with the liberal’s inability to tolerate any discussion or debate over a litany of politically correct talking points.
science. Both are wrought by the destructive tendency of the Republican party that makes governing impossible. They are a party of destruction, not creation. When Republicans are put in power they can’t do anything, their entire being is devoted to taking things apart. The Democrats are no better because of their devotion to compliance, regulation and compulsive rule following without thought. This tendency is paired with the liberal’s inability to tolerate any discussion or debate over a litany of politically correct talking points.
The management incompetence has been brewing for years. Our entire management construct is based lack of trust. The Lab itself is not to be trusted. The employees are not to be trusted. We are not trusted by the left or the right albeit for different reasons. The net result of all of this lack of trust is competence being subservient to lack-of-trust-based compliance with oversight. We are made to comply and heel to the will of the government. This is the will of a government that is increasingly completely incompetent and unfit to run anything, much less a nuclear weapons enterprise! The management of the Lab is mostly there to launder money and drive the workforce into a state of compliance with all directives. The actual accomplishment of high quality technical work is the least important thing we do. Compliance is the main thing. We want to be managed to never ever fuck up, ever. I f you are doing anything of real substance and performing at a high level, fuck ups are inevitable. The real key to the operation is the ability of technical competence to be faked. Our false confidence in the competent execution of our work is a localized harbinger of “fake news”.
f you are doing anything of real substance and performing at a high level, fuck ups are inevitable. The real key to the operation is the ability of technical competence to be faked. Our false confidence in the competent execution of our work is a localized harbinger of “fake news”.
Fox treats me well, it’s that Fox is the most accurate.
– Donald Trump
We have non-existent peer review and this leads to slack standards. Our agency tells us that we cannot fail (really, we effectively have to succeed 100% of the time). The way to not fail is lower our standards, which we have done in response. We aid our lower standards by castrating the peer review we ought to depend on. We now have Labs that cannot stand to have an honest critical peer review because of the consequences. In addition, we have adopted foolish financial incentives for executive management to compound problems. Since the executive bonuses are predicated on successful review, reviews have become laughable. Reviewers don’t dare raise difficult issues unless they never want to be invited back. We are now graded on a scale where everyone gets an “A” without regard to actual performance. Our excellence has become a local version of “fake news”.
At the very time that we need to raise our standards, we are allowing them to plummet lower and lower. Our reviews have become focused on spin and marketing of the work. Rather than show good work, provide challenges, and receive honest feedback, we form a message focused on “everything is great, and there is nothing to worry about”. Let’s be clear, the task of caring for nuclear weapons without testing them is incredibly challenging. To do this task correctly we need to be focused on raising our level of excellence across the board in science and engineering. Our technical standards should be higher than ever because of the difficulty and importance of this enterprise. Requiring 100% success might seem to be a way to do this, but it isn’t.
on raising our level of excellence across the board in science and engineering. Our technical standards should be higher than ever because of the difficulty and importance of this enterprise. Requiring 100% success might seem to be a way to do this, but it isn’t.
If you are succeeding 100% of the time, you are not applying yourself. When one is working at a place where you are mostly succeeding, but occasionally failing (and learning/growing), the outcomes are optimal. This is true in sports, business, science and engineering. Organizations are no different to do the best work possible, you need to fail and be working on the edge of failure. Ideally, we should be doing our work in a mode where we succeed 70-80% of the time. Our incompetent governance and leadership does not understand how badly they are undermining the performance of this vital enterprise. So, the opposite has happened, and the people leading us in the government are too fucking stupid to realize it. Our national leadership has become more obsessed with appearances than substance. All they see is the 100% scores and they conclude everything is awesome while our technical superiority is crumbling. Greatness in America today is defined by declaring greatness and refusing to accept evidence to the contrary.
Look at the F-35 as an example of our current ability to execute a big program. This aircraft is a completely corrupt massive shit storm. It is a giant, hyper-expensive fuckup. Rather than a working aircraft the F-35 was a delivery vehicle for pork barrel spending. God knows how much bullshitting went into the greenlighting of the program over the years. The bottom line is that the F-35 costs a huge amount of money, while being a complete failure as a weapon’s system. My concern that the F-35 is an excellent representative of our current technical capability. If it is, we are in deep trouble. We are expensive, corrupt and incompetent (sounds like a description of the President!). I’m very glad that we never ask our weapon’s lab to fly. Given our actual ability, we can guess the result.
 This is the place where we get to the core of the accent of Trump. When we lower our standards on leadership we get someone like Trump. The lowering of standards has taken place across the breadth of society. This is not simply National leadership, but corporate and social leadership. Greedy, corrupt and incompetent leaders are increasingly tolerated at all levels of society. At the Labs where I work, the leadership has to say yes to the government, no matter how moronic the direction is. If you don’t say yes, you are removed and punished. We now have leadership that is incapable of engaging in active discussion about how to succeed in our enterprise. The result are labs that simply take the money and execute whatever work they are given without regard for the wisdom of the direction. We now have the blind leading the spineless, and the blind are walking us right over the cliff. Our dysfunctional political system has finally shit the bed and put a moron in the White House. Everyone knows it, and yet a large portion of the population is completely fooled (or simply to foolish or naïve to understand how bad the situations is).
This is the place where we get to the core of the accent of Trump. When we lower our standards on leadership we get someone like Trump. The lowering of standards has taken place across the breadth of society. This is not simply National leadership, but corporate and social leadership. Greedy, corrupt and incompetent leaders are increasingly tolerated at all levels of society. At the Labs where I work, the leadership has to say yes to the government, no matter how moronic the direction is. If you don’t say yes, you are removed and punished. We now have leadership that is incapable of engaging in active discussion about how to succeed in our enterprise. The result are labs that simply take the money and execute whatever work they are given without regard for the wisdom of the direction. We now have the blind leading the spineless, and the blind are walking us right over the cliff. Our dysfunctional political system has finally shit the bed and put a moron in the White House. Everyone knows it, and yet a large portion of the population is completely fooled (or simply to foolish or naïve to understand how bad the situations is).
We are a paper tiger; a real opponent may simply destroy us. Our national superiority militarily and technically may already be gone. We are vastly confident of our outright superiority. This superiority requires our nation to continually bring their best to the table. We have almost systematically undermined our ability to apply our best to anything. We’ve already been attacked and defeated in the cyber-realm by Russia. Our society and democracy was assaulted by the Russians, and we were routed. Our incompetent governance has done virtually nothing. The seeds of our defeat have been sown for years all across our society. We are too incompetent to even realize how vulnerable we are.
I will admit that this whole line of thought might be wrong. The Labs where I work might be local hotbeds of incompetent management. What we see locally is not indicative of broader national trends. This seems very unlikely. What is more terrifying is the prospect that the places where I work are well managed comparatively. If this is true then it is completely plausible for us to have an incompetent President. So, the reality we have is stark incompetence across society that has set the stage for national tragedy. Our institutions and broad societal norms are under siege. Every single day of the Trump administration lessens the United States’ prestige. The World had counted on the United States for decades, but cannot any longer. We have made a decision as a nation that disqualifies us from a position of leadership. The Republican party has the greatest responsibility for this, but the Democrats are not blameless. Our institutional leadership shares the blame too. Places like the Labs where I work are being destroyed one incompetent step at a time. All of us need to fix this.
administration lessens the United States’ prestige. The World had counted on the United States for decades, but cannot any longer. We have made a decision as a nation that disqualifies us from a position of leadership. The Republican party has the greatest responsibility for this, but the Democrats are not blameless. Our institutional leadership shares the blame too. Places like the Labs where I work are being destroyed one incompetent step at a time. All of us need to fix this.
We have a walking, talking, tweeting example of our incompetence leading us, and it is everyone’s fault. We all let this happen. We are all responsible. We own this.
Ask not what your country can do for you; ask what you can do for your country.
― John F. Kennedy
 computer, the better the science and discovery. As an added bonus the visualizations of the results are stunning almost Hollywood-quality and special effect appealing. It provides the perfect sales pitch for the acquisition of the new supercomputer and everything that goes with it. With a faster computer, we can just turn it loose and let the understanding flow like water bursting through a dam. With the power of DNS, the secrets of the universe will simply submit to our mastery!
computer, the better the science and discovery. As an added bonus the visualizations of the results are stunning almost Hollywood-quality and special effect appealing. It provides the perfect sales pitch for the acquisition of the new supercomputer and everything that goes with it. With a faster computer, we can just turn it loose and let the understanding flow like water bursting through a dam. With the power of DNS, the secrets of the universe will simply submit to our mastery! The saddest thing about DNS is the tendency for scientist’s brains to almost audibly click into the off position when its invoked. All one has to say is that their calculation is a DNS and almost any question or doubt leaves the room. No need to look deeper, or think about the results, we are solving the fundamental laws of physics with stunning accuracy! It must be right! They will assert, “this is a first principles” calculation, and predictive at that. Simply marvel at the truths waiting to be unveiled in the sea of bits. Add a bit of machine learning, or artificial intelligence to navigate the massive dataset produced by DNS, (the datasets are so fucking massive, they must have something good! Right?) and you have the recipe for the perfect bullshit sandwich. How dare some infidel cast doubt, or uncertainty on the results! Current DNS practice is a religion within the scientific community, and brings an intellectual rot into the core computational science. DNS reflects some of the worst wishful thinking in the field where the desire for truth, and understanding overwhelms good sense. A more damning assessment would be a tendency to submit to intellectual laziness when pressed by expediency, or difficulty in progress.
The saddest thing about DNS is the tendency for scientist’s brains to almost audibly click into the off position when its invoked. All one has to say is that their calculation is a DNS and almost any question or doubt leaves the room. No need to look deeper, or think about the results, we are solving the fundamental laws of physics with stunning accuracy! It must be right! They will assert, “this is a first principles” calculation, and predictive at that. Simply marvel at the truths waiting to be unveiled in the sea of bits. Add a bit of machine learning, or artificial intelligence to navigate the massive dataset produced by DNS, (the datasets are so fucking massive, they must have something good! Right?) and you have the recipe for the perfect bullshit sandwich. How dare some infidel cast doubt, or uncertainty on the results! Current DNS practice is a religion within the scientific community, and brings an intellectual rot into the core computational science. DNS reflects some of the worst wishful thinking in the field where the desire for truth, and understanding overwhelms good sense. A more damning assessment would be a tendency to submit to intellectual laziness when pressed by expediency, or difficulty in progress. Let’s unpack this issue a bit and get to the core of the problems. First, I will submit that DNS is an unambiguously valuable scientific tool. A large body of work valuable to a broad swath of science can benefit from DNS. We can study our understanding of the universe in myriad ways at phenomenal detail. On the other hand, DNS is not ever a substitute for observations. We do not know the fundamental laws of the universe with such certainty that the solutions provide an absolute truth. The laws we know are models plain and simple. They will always be models. As models, they are approximate and incomplete by their basic nature. This is how science works, we have a theory that explains the universe, and we test that theory (i.e., model) against what we observe. If the model produces the observations with high precision, the model is confirmed. This model confirmation is always tentative and subject to being tested with new or more accurate observations. Solving a model does not replace observations, ever, and some uses of DNS are masking laziness or limitations in observational (experimental) science.
Let’s unpack this issue a bit and get to the core of the problems. First, I will submit that DNS is an unambiguously valuable scientific tool. A large body of work valuable to a broad swath of science can benefit from DNS. We can study our understanding of the universe in myriad ways at phenomenal detail. On the other hand, DNS is not ever a substitute for observations. We do not know the fundamental laws of the universe with such certainty that the solutions provide an absolute truth. The laws we know are models plain and simple. They will always be models. As models, they are approximate and incomplete by their basic nature. This is how science works, we have a theory that explains the universe, and we test that theory (i.e., model) against what we observe. If the model produces the observations with high precision, the model is confirmed. This model confirmation is always tentative and subject to being tested with new or more accurate observations. Solving a model does not replace observations, ever, and some uses of DNS are masking laziness or limitations in observational (experimental) science. This does not say that DNS is not useful. DNS can produce scientific results that may be used in a variety of ways where experimental or observational results are not available. This is a way of overcoming a limitation of what we can tease out of nature. Realizing this limitation should always come with the proviso that this is expedient, and used in the absence of observational data. Observational evidence should always be sought and the models should always be subjected to tests of validity. The results come from assuming the model is very good and provides value, but cannot be used to validate the model. DNS is always second best to observation. Turbulence is a core example of this principle, we do not understand turbulence; it is an unsolved problem. DNS as a model has not yielded understanding sufficient to unveil the secrets of the universe. They are still shrouded. Part of the issue is the limitations of the model itself. In turbulence DNS almost always utilizes an unphysical model to describe fluid dynamics with a lack of thermodynamics and infinitely fast acoustic waves. Being unphysical in its fundamental character, how can we possibly consider it a replacement for reality? Yet in a violation of common sense driven by frustration of lack of progress, we do this all the time.
This does not say that DNS is not useful. DNS can produce scientific results that may be used in a variety of ways where experimental or observational results are not available. This is a way of overcoming a limitation of what we can tease out of nature. Realizing this limitation should always come with the proviso that this is expedient, and used in the absence of observational data. Observational evidence should always be sought and the models should always be subjected to tests of validity. The results come from assuming the model is very good and provides value, but cannot be used to validate the model. DNS is always second best to observation. Turbulence is a core example of this principle, we do not understand turbulence; it is an unsolved problem. DNS as a model has not yielded understanding sufficient to unveil the secrets of the universe. They are still shrouded. Part of the issue is the limitations of the model itself. In turbulence DNS almost always utilizes an unphysical model to describe fluid dynamics with a lack of thermodynamics and infinitely fast acoustic waves. Being unphysical in its fundamental character, how can we possibly consider it a replacement for reality? Yet in a violation of common sense driven by frustration of lack of progress, we do this all the time.

 approximate. The approximate solution is never free of numerical error. In DNS, the estimate of the magnitude of approximation error is almost universally lacking from results.
approximate. The approximate solution is never free of numerical error. In DNS, the estimate of the magnitude of approximation error is almost universally lacking from results. Unfortunately, we also need to address an even more deplorable DNS practice. Sometimes people simply declare that their calculation is a DNS without any evidence to support this assertion. Usually this means the calculation is really, really, really, super fucking huge and produces some spectacular graphics with movies and color (rendered in super groovy ways). Sometimes the models being solved are themselves extremely crude or approximate. For example, the Euler equations are being solved with or without turbulence models instead of Navier-Stokes in cases where turbulence is certainly present. This practice is so abominable as to be almost a cartoon of credibility. This is the use of proof by overwhelming force. Claims of DNS should always be taken with a grain of salt. When the claims take the form of marketing they should be met with extreme doubt since it is a form of bullshitting that tarnishes those working to practice scientific integrity.
Unfortunately, we also need to address an even more deplorable DNS practice. Sometimes people simply declare that their calculation is a DNS without any evidence to support this assertion. Usually this means the calculation is really, really, really, super fucking huge and produces some spectacular graphics with movies and color (rendered in super groovy ways). Sometimes the models being solved are themselves extremely crude or approximate. For example, the Euler equations are being solved with or without turbulence models instead of Navier-Stokes in cases where turbulence is certainly present. This practice is so abominable as to be almost a cartoon of credibility. This is the use of proof by overwhelming force. Claims of DNS should always be taken with a grain of salt. When the claims take the form of marketing they should be met with extreme doubt since it is a form of bullshitting that tarnishes those working to practice scientific integrity. The standards of practice in verification of computer codes and applied calculations are generally appalling. Most of the time when I encounter work, I’m just happy to see anything at all done to verify a code. Put differently, most of the published literature accepts a slip shod practice in terms of verification. In some areas like shock physics, the viewgraph norm still reigns supreme. It actually rules supreme in a far broader swath of science, but you talk about what you know. The missing element in most of the literature is the lack of quantitative analysis of results. Even when the work is better and includes detailed quantitative analysis, the work usually lacks a deep connection with numerical analysis results. The typical best practice in verification only includes the comparison of the observed rate of convergence with the theoretical rate of convergence. Worse yet, the result is asymptotic and codes are rarely practically used with asymptotic meshes. Thus, standard practice is largely superficial, and only scratches the surface of the connections with numerical analysis.
The standards of practice in verification of computer codes and applied calculations are generally appalling. Most of the time when I encounter work, I’m just happy to see anything at all done to verify a code. Put differently, most of the published literature accepts a slip shod practice in terms of verification. In some areas like shock physics, the viewgraph norm still reigns supreme. It actually rules supreme in a far broader swath of science, but you talk about what you know. The missing element in most of the literature is the lack of quantitative analysis of results. Even when the work is better and includes detailed quantitative analysis, the work usually lacks a deep connection with numerical analysis results. The typical best practice in verification only includes the comparison of the observed rate of convergence with the theoretical rate of convergence. Worse yet, the result is asymptotic and codes are rarely practically used with asymptotic meshes. Thus, standard practice is largely superficial, and only scratches the surface of the connections with numerical analysis. One of things to understand is that code verification also contains a complete accounting of the numerical error. This error can be used to compare methods with “identical” orders of accuracy for levels of numerical error, which can be useful in making decisions about code options. By the same token solution verification provides information about the observed order of accuracy. Because the applied problems are not analytical or smooth enough, they generally can’t be expected to provide the theoretical order of convergence. The rate of convergence is then an auxiliary result of the solution verification exercise just as the error is an auxiliary result for code verification. It contains useful information on the solution, but it is subservient to the error estimate. Conversely, the error provided in code verification is subservient to the order of accuracy. Nonetheless, the current practice simply scratches the surface of what could be done via verification and its unambiguous ties to numerical analysis.
One of things to understand is that code verification also contains a complete accounting of the numerical error. This error can be used to compare methods with “identical” orders of accuracy for levels of numerical error, which can be useful in making decisions about code options. By the same token solution verification provides information about the observed order of accuracy. Because the applied problems are not analytical or smooth enough, they generally can’t be expected to provide the theoretical order of convergence. The rate of convergence is then an auxiliary result of the solution verification exercise just as the error is an auxiliary result for code verification. It contains useful information on the solution, but it is subservient to the error estimate. Conversely, the error provided in code verification is subservient to the order of accuracy. Nonetheless, the current practice simply scratches the surface of what could be done via verification and its unambiguous ties to numerical analysis.
 , the error is
, the error is  . We can now estimate the error for any step size and analytically estimate the convergence rate we would observe in practice. If we employ the relatively standard practice of mesh halving for verification, we get the estimate of the rate of convergence,
. We can now estimate the error for any step size and analytically estimate the convergence rate we would observe in practice. If we employ the relatively standard practice of mesh halving for verification, we get the estimate of the rate of convergence, ![n(h) = \log\left[E(h)/E(h/2)\right]/\log(2)](https://s0.wp.com/latex.php?latex=n%28h%29+%3D+%5Clog%5Cleft%5BE%28h%29%2FE%28h%2F2%29%5Cright%5D%2F%5Clog%282%29&bg=ffffff&fg=000&s=0&c=20201002) . A key point to remember is that the solution with the halved time step takes twice the number of steps. Using this methodology, we can easily see the impact of finite resolution. For the forward Euler method, we can see that steps larger than zero raise the rate of convergence above the theoretical value of one. This is exactly what we see in practice.
. A key point to remember is that the solution with the halved time step takes twice the number of steps. Using this methodology, we can easily see the impact of finite resolution. For the forward Euler method, we can see that steps larger than zero raise the rate of convergence above the theoretical value of one. This is exactly what we see in practice.

 ted in the shadows for years and years as one of Hollywood’s worst kept secrets. Weinstein preyed on women with virtual impunity with his power and prestige acting to keep his actions in the dark. The promise and threat of his power in that industry gave him virtual license to act. The silence of the myriad of insiders who knew about the pattern of abuse allowed the crimes to continue unabated. Only after the abuse came to light broadly and outside the movie industry did the unacceptability arise. When the abuse stayed in the shadows, and its knowledge limited to industry insiders, it continued.
ted in the shadows for years and years as one of Hollywood’s worst kept secrets. Weinstein preyed on women with virtual impunity with his power and prestige acting to keep his actions in the dark. The promise and threat of his power in that industry gave him virtual license to act. The silence of the myriad of insiders who knew about the pattern of abuse allowed the crimes to continue unabated. Only after the abuse came to light broadly and outside the movie industry did the unacceptability arise. When the abuse stayed in the shadows, and its knowledge limited to industry insiders, it continued. Our current President is serial abuser of power whether it be the legal system, women, business associates or the American people, his entire life is constructed around abuse of power and the privileges of wealth. Many people are his enablers, and nothing enables it more than silence. Like Weinstein, his sexual misconducts are many and well known, yet routinely go unpunished. Others either remain silence or ignore and excuse the abuse a being completely normal.
Our current President is serial abuser of power whether it be the legal system, women, business associates or the American people, his entire life is constructed around abuse of power and the privileges of wealth. Many people are his enablers, and nothing enables it more than silence. Like Weinstein, his sexual misconducts are many and well known, yet routinely go unpunished. Others either remain silence or ignore and excuse the abuse a being completely normal. ower and ability to abuse it. They are an entire collection of champion power abusers. Like all abusers, they maintain their power through the cowering masses below them. When we are silent their power is maintained. They are moving the squash all resistance. My training was pointed at the inside of the institutions and instruments of government where they can use “legal” threats to shut us up. They have waged an all-out assault against the news media. Anything they don’t like is labeled as “fake news” and attacked. The legitimacy of facts has been destroyed, providing the foundation for their power. We are now being threatened to cut off the supply of facts to base resistance upon. This training was the act of people wanting to rule like dictators in an authoritarian manner.
ower and ability to abuse it. They are an entire collection of champion power abusers. Like all abusers, they maintain their power through the cowering masses below them. When we are silent their power is maintained. They are moving the squash all resistance. My training was pointed at the inside of the institutions and instruments of government where they can use “legal” threats to shut us up. They have waged an all-out assault against the news media. Anything they don’t like is labeled as “fake news” and attacked. The legitimacy of facts has been destroyed, providing the foundation for their power. We are now being threatened to cut off the supply of facts to base resistance upon. This training was the act of people wanting to rule like dictators in an authoritarian manner. the set-up is perfect. They are the wolves and we, the sheep, are primed for slaughter. Recent years have witnessed an explosion in the amount of information deemed classified or sensitive. Much of this information is controlled because it is embarrassing or uncomfortable for those in power. Increasingly, information is simply hidden based on non-existent standards. This is a situation that is primed for abuse of power. People is positions of power can hide anything they don’t like. For example, something bad or embarrassing can be deemed to be proprietary or business-sensitive, and buried from view. Here the threats come in handy to make sure that everyone keeps their mouths shut. Various abuses of power can now run free within the system without risk of exposure. Add a weakened free press and you’ve created the perfect storm.
the set-up is perfect. They are the wolves and we, the sheep, are primed for slaughter. Recent years have witnessed an explosion in the amount of information deemed classified or sensitive. Much of this information is controlled because it is embarrassing or uncomfortable for those in power. Increasingly, information is simply hidden based on non-existent standards. This is a situation that is primed for abuse of power. People is positions of power can hide anything they don’t like. For example, something bad or embarrassing can be deemed to be proprietary or business-sensitive, and buried from view. Here the threats come in handy to make sure that everyone keeps their mouths shut. Various abuses of power can now run free within the system without risk of exposure. Add a weakened free press and you’ve created the perfect storm. him. No one even asks the question, and the abuse of power goes unchecked. Worse yet, it becomes the “way things are done”. This takes us full circle to the whole Harvey Weinstein scandal. It is a textbook example of unchecked power, and the “way we do things”.
him. No one even asks the question, and the abuse of power goes unchecked. Worse yet, it becomes the “way things are done”. This takes us full circle to the whole Harvey Weinstein scandal. It is a textbook example of unchecked power, and the “way we do things”.






 oo often we make the case that their misdeeds are acceptable because of the power they grant to your causes through their position. This is exactly the bargain Trump makes with the right wing, and Weinstein made with the left.
oo often we make the case that their misdeeds are acceptable because of the power they grant to your causes through their position. This is exactly the bargain Trump makes with the right wing, and Weinstein made with the left. I’d like to be independent empowered and passionate about work, and I definitely used to be. Instead I find that I’m generally disempowered compliant and despondent these days. The actions that manage us have this effect; sending the clear message that we are not in control; we are to be controlled, and our destiny is determined by our subservience. With the National environment headed in this direction, institutions like our National Labs cannot serve their important purpose. The situation is getting steadily worse, but as I’ve seen there is always somewhere worse. By the standards of most people I still have a good job with lots of perks and benefits. Most might tell me that I’ve got it good, and I do, but I’ve never been satisfied with such mediocrity. The standard of “it could be worse” is simply an appalling way to live. The truth is that I’m in a velvet cage. This is said with the stark realization that the same forces are dragging all of us down. Just because I’m relatively fortunate doesn’t mean that the situation is tolerable. The quip that things could be worse is simply a way of accepting the intolerable.
I’d like to be independent empowered and passionate about work, and I definitely used to be. Instead I find that I’m generally disempowered compliant and despondent these days. The actions that manage us have this effect; sending the clear message that we are not in control; we are to be controlled, and our destiny is determined by our subservience. With the National environment headed in this direction, institutions like our National Labs cannot serve their important purpose. The situation is getting steadily worse, but as I’ve seen there is always somewhere worse. By the standards of most people I still have a good job with lots of perks and benefits. Most might tell me that I’ve got it good, and I do, but I’ve never been satisfied with such mediocrity. The standard of “it could be worse” is simply an appalling way to live. The truth is that I’m in a velvet cage. This is said with the stark realization that the same forces are dragging all of us down. Just because I’m relatively fortunate doesn’t mean that the situation is tolerable. The quip that things could be worse is simply a way of accepting the intolerable. beings (people) into a hive where their basic humanity and individuality is lost. Everything is controlled and managed for the good of the collective. Science Fiction is an allegory for society, and the forces of depersonalized control embodied by the Borg have only intensified in our world. Even people working in my chosen profession are under the thrall of a mindless collective. Most of the time it is my maturity and experience as an adult that is called upon. My expertise and knowledge should be my most valuable commodity as a professional, yet they go unused and languishing. They come to play in an almost haphazard catch-what-catch-can manner. Most of the time it happens when I engage with someone external. It is never planned or systematic. My management is much more concerned about me being up on my compliance training than productively employing my talents. The end result is the loss of identity and sense of purpose, so that now I am simply the ninth member of the bottom unit of the collective, 9 of 13.
beings (people) into a hive where their basic humanity and individuality is lost. Everything is controlled and managed for the good of the collective. Science Fiction is an allegory for society, and the forces of depersonalized control embodied by the Borg have only intensified in our world. Even people working in my chosen profession are under the thrall of a mindless collective. Most of the time it is my maturity and experience as an adult that is called upon. My expertise and knowledge should be my most valuable commodity as a professional, yet they go unused and languishing. They come to play in an almost haphazard catch-what-catch-can manner. Most of the time it happens when I engage with someone external. It is never planned or systematic. My management is much more concerned about me being up on my compliance training than productively employing my talents. The end result is the loss of identity and sense of purpose, so that now I am simply the ninth member of the bottom unit of the collective, 9 of 13.
 actually manage the work going on and the people doing the work. They are managing our compliance and control, not the work; the work we do is mere afterthought that increasingly does not need me any competent person would do. At one time work felt good and important with a deep sense of personal value and accomplishment. Slowly and surely this sense is being under-mined. We have gone on a long slow march away from being empowered and valued as contributing individuals. Today we are simply ever-replicable cogs in a machine that cannot tolerate a hint of individuality or personality.
actually manage the work going on and the people doing the work. They are managing our compliance and control, not the work; the work we do is mere afterthought that increasingly does not need me any competent person would do. At one time work felt good and important with a deep sense of personal value and accomplishment. Slowly and surely this sense is being under-mined. We have gone on a long slow march away from being empowered and valued as contributing individuals. Today we are simply ever-replicable cogs in a machine that cannot tolerate a hint of individuality or personality. great, and I believe in it. Management should be the art of enabling and working to get the most out of employees. If the system was working properly this would happen. For some reason society has removed its trust for people. Our systems are driven and motivated by fear. The systems are strongly motivated to make sure that people don’t fuck up. A large part of the overhead and lack of empowerment is designed to keep people from making mistakes. A big part of the issue is the punishment meted out for any fuck ups. Our institutions are mercilessly punished for any mistakes. Honest mistakes and failures are met with negative outcomes and a lack of tolerance. The result is a system that tries to defend itself through caution, training and control of people. Our innate potential is insufficient justification for risking the reaction a fuck up might generate. The result is an increasingly meek and subdued workforce unwilling to take risks because failure is such a grim prospect.
great, and I believe in it. Management should be the art of enabling and working to get the most out of employees. If the system was working properly this would happen. For some reason society has removed its trust for people. Our systems are driven and motivated by fear. The systems are strongly motivated to make sure that people don’t fuck up. A large part of the overhead and lack of empowerment is designed to keep people from making mistakes. A big part of the issue is the punishment meted out for any fuck ups. Our institutions are mercilessly punished for any mistakes. Honest mistakes and failures are met with negative outcomes and a lack of tolerance. The result is a system that tries to defend itself through caution, training and control of people. Our innate potential is insufficient justification for risking the reaction a fuck up might generate. The result is an increasingly meek and subdued workforce unwilling to take risks because failure is such a grim prospect.
 The same thing is happening to our work. Fear and risk is dominating our decision-making. Human potential, talent, productivity, and lives of value are sacrificed at the altar of fear. Caution has replaced boldness. Compliance has replaced value. Control has replaced empowerment. In the process work has lost meaning and the ability for an individual to make a difference has disappeared. Resistance is futile, you will be assimilated.
The same thing is happening to our work. Fear and risk is dominating our decision-making. Human potential, talent, productivity, and lives of value are sacrificed at the altar of fear. Caution has replaced boldness. Compliance has replaced value. Control has replaced empowerment. In the process work has lost meaning and the ability for an individual to make a difference has disappeared. Resistance is futile, you will be assimilated.  . For almost every control volume code these terms are dissipative in shock waves, thus providing additional stability to the codes in this dangerous configuration. The opposing reaction in expansions can go unnoticed because any imperfections in the solution are modulated by the physics of the problem. For this reason, the failing has gone completely unnoticed for decades. A reasonable question to explore is whether codes based on different design principles exhibit the same problems, or produce solutions that satisfy the second law of thermodynamics more uniformly.
. For almost every control volume code these terms are dissipative in shock waves, thus providing additional stability to the codes in this dangerous configuration. The opposing reaction in expansions can go unnoticed because any imperfections in the solution are modulated by the physics of the problem. For this reason, the failing has gone completely unnoticed for decades. A reasonable question to explore is whether codes based on different design principles exhibit the same problems, or produce solutions that satisfy the second law of thermodynamics more uniformly.![f(u_l,u_r) = \frac{1}{2} \left[ f_l + f_r \right]](https://s0.wp.com/latex.php?latex=f%28u_l%2Cu_r%29+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Cleft%5B+f_l+%2B+f_r+%5Cright%5D%C2%A0+%C2%A0&bg=ffffff&fg=000&s=0&c=20201002)
 $ ( u_r – u_l ) $. The quantity
$ ( u_r – u_l ) $. The quantity  is the nonlinear flux,
is the nonlinear flux,  are the states to the left and right of the interface. The dissipation is defined by the eigen-decomposition of the flux Jacobian,
are the states to the left and right of the interface. The dissipation is defined by the eigen-decomposition of the flux Jacobian,  . This decomposition is contained of the right and left eigenvectors and the eigenvalues,
. This decomposition is contained of the right and left eigenvectors and the eigenvalues,  . These eigenvalues are the characteristic velocities, which for gas dynamics are
. These eigenvalues are the characteristic velocities, which for gas dynamics are  being the velocities and the sound speeds,
being the velocities and the sound speeds,  . This basic decomposition is the basis of flux splitting techniques.
. This basic decomposition is the basis of flux splitting techniques. . One was to do this is choose a velocity,
. One was to do this is choose a velocity,  , and create contributions where
, and create contributions where ![f(u)^+ = \frac{1}{2} \left[ f(u) + \alpha u\right]](https://s0.wp.com/latex.php?latex=f%28u%29%5E%2B+%3D+%5Cfrac%7B1%7D%7B2%7D+%5Cleft%5B+f%28u%29+%2B+%5Calpha+u%5Cright%5D+&bg=ffffff&fg=000&s=0&c=20201002) and
and ![f(u)^- = \frac{1}{2}\left[ f(u) - \alpha u\right]](https://s0.wp.com/latex.php?latex=f%28u%29%5E-+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cleft%5B+f%28u%29+-+%5Calpha+u%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) . A simple choice of
. A simple choice of  creates the Lax-Friedrichs flux, the simplest (and most dissipative) Riemann solver. For the general linearized Riemann solver the flux splitting is
creates the Lax-Friedrichs flux, the simplest (and most dissipative) Riemann solver. For the general linearized Riemann solver the flux splitting is ![f(u)^+ = \frac{1}{2}\left[ f(u) + R |\lambda | L u\right]](https://s0.wp.com/latex.php?latex=f%28u%29%5E%2B+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cleft%5B+f%28u%29+%2B+R+%7C%5Clambda+%7C+L+u%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) and
and ![f(u)^- = \frac{1}{2}\left[ f(u) - R | \lambda | L u\right]](https://s0.wp.com/latex.php?latex=f%28u%29%5E-+%3D+%5Cfrac%7B1%7D%7B2%7D%5Cleft%5B+f%28u%29+-+R%C2%A0+%7C+%5Clambda+%7C+L+u%5Cright%5D&bg=ffffff&fg=000&s=0&c=20201002) . The choice of the left and right states to evaluate the flux Jacobian defines the flux splitting. For example, if the states are evaluated using Roe’s recipe, we get the Roe flux splitting. If we evaluate the eigenvalues in a bounding fashion we can get the local Lax-Friedrichs method.
. The choice of the left and right states to evaluate the flux Jacobian defines the flux splitting. For example, if the states are evaluated using Roe’s recipe, we get the Roe flux splitting. If we evaluate the eigenvalues in a bounding fashion we can get the local Lax-Friedrichs method. and $ f^- = \frac{1}{2} ( f – R \mbox{sign(\lambda) L ) f$. We not in passing that the smooth or soft version of the sign function might be extremely useful in this type of splitting and introducing a continuously differentiable function (
and $ f^- = \frac{1}{2} ( f – R \mbox{sign(\lambda) L ) f$. We not in passing that the smooth or soft version of the sign function might be extremely useful in this type of splitting and introducing a continuously differentiable function ( is the smallest wave speed and needs to be bounded at zero (i.e., it is negative). The right most wave speed is
is the smallest wave speed and needs to be bounded at zero (i.e., it is negative). The right most wave speed is 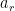 and is bounded below by zero. The HLL flux has the benefit of reducing to simple upwind flux for the system if all the wave speeds are either negative or positive. For a flux splitting we need to take this apart into negative and positive moving pieces for the purposes of splitting nearby fluxes as we did with the Roe, or flavors of Lax-Friedrichs.
and is bounded below by zero. The HLL flux has the benefit of reducing to simple upwind flux for the system if all the wave speeds are either negative or positive. For a flux splitting we need to take this apart into negative and positive moving pieces for the purposes of splitting nearby fluxes as we did with the Roe, or flavors of Lax-Friedrichs. . If we desire a flux splitting, it needs to be defined in terms of these variables. The trick in this endeavor is choosing an algebraic structure to help produce a workable flux splitting technique. We build upon the experience of the HLL flux partially because we can incorporate the knowledge arising from the exact solution into the algebraic structure to good effect. In particular, the nature of the one-sided differencing can be reproduced effectively. This requires the wave speed bounds to use the interior states of the solution.
. If we desire a flux splitting, it needs to be defined in terms of these variables. The trick in this endeavor is choosing an algebraic structure to help produce a workable flux splitting technique. We build upon the experience of the HLL flux partially because we can incorporate the knowledge arising from the exact solution into the algebraic structure to good effect. In particular, the nature of the one-sided differencing can be reproduced effectively. This requires the wave speed bounds to use the interior states of the solution. our work will be done. The positive flux is $ f^+ = (a_r f + D u) / (a_r – a_l})$. The negative flux is $ f^- = (- a_l f – D u) / (a_r – a_l) $. Now we just have a little bit of algebra to arrive at our final expression. The math is nice and straightforward, $ D = (a_r f_l – a_l f_r – (a_r – a_l) f_{lr} ) / (u_r – u_l) $. A couple comments are needed at this point. When the states become equal, the solver becomes ill defined,
our work will be done. The positive flux is $ f^+ = (a_r f + D u) / (a_r – a_l})$. The negative flux is $ f^- = (- a_l f – D u) / (a_r – a_l) $. Now we just have a little bit of algebra to arrive at our final expression. The math is nice and straightforward, $ D = (a_r f_l – a_l f_r – (a_r – a_l) f_{lr} ) / (u_r – u_l) $. A couple comments are needed at this point. When the states become equal, the solver becomes ill defined,  . Fortunately, this is exactly where the linearized flux splitting approaches or HLL would be ideal.
. Fortunately, this is exactly where the linearized flux splitting approaches or HLL would be ideal. (
( being in the audience. Giving talks is pretty low on the list of reasons, but not in the mind of our overlords, which starts to get at the problems I’ll discuss below. Given the track record of this meeting my expectations were sky-high, and the lack of inspiring ideas left me slightly despondent.
being in the audience. Giving talks is pretty low on the list of reasons, but not in the mind of our overlords, which starts to get at the problems I’ll discuss below. Given the track record of this meeting my expectations were sky-high, and the lack of inspiring ideas left me slightly despondent.



 This outcome is conflated with the general lack of intellectual vigor in any public discourse. The same lack of intellectual vigor has put this foolish exascale program in place. Ideas are viewed as counter-productive today in virtually every public square. Alarmingly, science is now suffering from the same ill. Experts and the intellectual elite are viewed unfavorably and their views held in suspicion. Their work is not supported, nor is projects and programs dependent on deep thinking, ideas or intellectual labor. The fingerprints of this systematic dumbing down of our work have reached computational science, and reaping a harvest of poisoned fruit. Another sign of the problem is the lack of engagement of our top scientists in driving new directions in research. Today, managers who do not have any active research define new directions. Every year our manager’s work gets further from any technical content. We have the blind leading the sighted and telling them to trust them, they can see where we are going. This problem highlights the core of the issue; the only thing that matters today is money. What we spend the money on, and the value of that work to advance science is essentially meaningless.
This outcome is conflated with the general lack of intellectual vigor in any public discourse. The same lack of intellectual vigor has put this foolish exascale program in place. Ideas are viewed as counter-productive today in virtually every public square. Alarmingly, science is now suffering from the same ill. Experts and the intellectual elite are viewed unfavorably and their views held in suspicion. Their work is not supported, nor is projects and programs dependent on deep thinking, ideas or intellectual labor. The fingerprints of this systematic dumbing down of our work have reached computational science, and reaping a harvest of poisoned fruit. Another sign of the problem is the lack of engagement of our top scientists in driving new directions in research. Today, managers who do not have any active research define new directions. Every year our manager’s work gets further from any technical content. We have the blind leading the sighted and telling them to trust them, they can see where we are going. This problem highlights the core of the issue; the only thing that matters today is money. What we spend the money on, and the value of that work to advance science is essentially meaningless. Effectively we are seeing the crisis that has infested our broader public sphere moving into science. The lack of intellectual thought and vitality pushing our public discourse to the lowest common denominator is now attacking science. Rather than integrate the best in scientific judgment into our decisions on research direction, it is ignored. The experts are simply told to get in line with the right answer or be silent. In addition, the programs defined through this process then feed back to the scientific community savaging the expertise further. The fact that this science is intimately connected to national and international security should provide a sharper point on the topic. We are caught in a vicious cycle and we are seeing the evidence in the hollowing out of good work at this conference. If one is looking for a poster child for bad research directions, the exascale programs are a good place to look. I’m sure other areas of science are suffering through similar ills. This global effort is genuinely poorly thought through and lacks any sort of intellectual curiosity.
Effectively we are seeing the crisis that has infested our broader public sphere moving into science. The lack of intellectual thought and vitality pushing our public discourse to the lowest common denominator is now attacking science. Rather than integrate the best in scientific judgment into our decisions on research direction, it is ignored. The experts are simply told to get in line with the right answer or be silent. In addition, the programs defined through this process then feed back to the scientific community savaging the expertise further. The fact that this science is intimately connected to national and international security should provide a sharper point on the topic. We are caught in a vicious cycle and we are seeing the evidence in the hollowing out of good work at this conference. If one is looking for a poster child for bad research directions, the exascale programs are a good place to look. I’m sure other areas of science are suffering through similar ills. This global effort is genuinely poorly thought through and lacks any sort of intellectual curiosity. Priority is placed on our existing codes working on the new super expensive computers. The up front cost of these computers is the tip of the proverbial cost iceberg. The explicit cost of the computers is their purchase price, their massive electrical bill and the cost of using these monstrosities. The computers are not the computers we want to use, they are the ones we are forced to use. As such the cost of developing codes on these computers is extreme. These new computers are immensely unproductive environments. They are a huge tax on everyone’s efforts. This sucks the creative air from the room and leads to a reduction in the ability to do anything else. Since all the things being suffocated by exascale are more useful for modeling and simulation, the ability to actually improve our computational modeling is hurt. The only things that benefit from the exascale program are trivial and already exist as well-defined modeling efforts.
Priority is placed on our existing codes working on the new super expensive computers. The up front cost of these computers is the tip of the proverbial cost iceberg. The explicit cost of the computers is their purchase price, their massive electrical bill and the cost of using these monstrosities. The computers are not the computers we want to use, they are the ones we are forced to use. As such the cost of developing codes on these computers is extreme. These new computers are immensely unproductive environments. They are a huge tax on everyone’s efforts. This sucks the creative air from the room and leads to a reduction in the ability to do anything else. Since all the things being suffocated by exascale are more useful for modeling and simulation, the ability to actually improve our computational modeling is hurt. The only things that benefit from the exascale program are trivial and already exist as well-defined modeling efforts.





 rse. Most of the activity for working scientists is at the boundaries of our knowledge working to push back our current limits on what is known. The scientific method is there to provide structure and order to the expansion of knowledge. We have well chosen and understood ways to test proposed knowledge. A method of using and testing our theoretical knowledge in science is computational simulation. Within computational work the use of verification, validation with uncertainty quantification is basically the scientific method in action (
rse. Most of the activity for working scientists is at the boundaries of our knowledge working to push back our current limits on what is known. The scientific method is there to provide structure and order to the expansion of knowledge. We have well chosen and understood ways to test proposed knowledge. A method of using and testing our theoretical knowledge in science is computational simulation. Within computational work the use of verification, validation with uncertainty quantification is basically the scientific method in action ( If the uncertainty is irreducible and unavoidable, the problem with not assessing uncertainty and taking an implied value of ZERO for uncertainty becomes truly dangerous (
If the uncertainty is irreducible and unavoidable, the problem with not assessing uncertainty and taking an implied value of ZERO for uncertainty becomes truly dangerous ( may prove deadly in rather commonly encountered situations. As systems become more complex and energetic, chaotic character becomes more acute and common. This chaotic character leads to solutions that have natural variability. Understanding this natural variability is essential to understanding the system. Building this knowledge is the first step in moving to a capability to control and engineer it, and perhaps if wise, reduce it. If one does not possess the understanding of what the variability is, such variability cannot be addressed via systematic engineering or accommodation.
may prove deadly in rather commonly encountered situations. As systems become more complex and energetic, chaotic character becomes more acute and common. This chaotic character leads to solutions that have natural variability. Understanding this natural variability is essential to understanding the system. Building this knowledge is the first step in moving to a capability to control and engineer it, and perhaps if wise, reduce it. If one does not possess the understanding of what the variability is, such variability cannot be addressed via systematic engineering or accommodation.
 systematically is an ever-growing limit for science. We have a major scientific gap open in front of us and we are failing to acknowledge and attack it with our scientific tools. It is simply ignored almost by fiat. Changing our perspective would make a huge difference in experimental and theoretical science, and remove our collective heads from the sand about this matter.
systematically is an ever-growing limit for science. We have a major scientific gap open in front of us and we are failing to acknowledge and attack it with our scientific tools. It is simply ignored almost by fiat. Changing our perspective would make a huge difference in experimental and theoretical science, and remove our collective heads from the sand about this matter.

 willful uncertainty ignorance. Probably the most common uncertainty to be willfully ignorant of is numerical error. The key numerical error is discretization error that arises from the need to make a continuous problem, discrete and computable. The basic premise of computing is that more discrete degrees of freedom should produce a more accurate answer. Through examining the rate that this happens, the magnitude of the error can be estimated. Other estimates can be had though making some assumptions about the solution and relating the error the nature of the solution (like the magnitude of estimated derivatives). Other generally smaller numerical errors arise from solving systems of equations to a specified tolerance, parallel consistency error and round-off error. In most circumstances these are much smaller than discretization error, but are still non-zero.
willful uncertainty ignorance. Probably the most common uncertainty to be willfully ignorant of is numerical error. The key numerical error is discretization error that arises from the need to make a continuous problem, discrete and computable. The basic premise of computing is that more discrete degrees of freedom should produce a more accurate answer. Through examining the rate that this happens, the magnitude of the error can be estimated. Other estimates can be had though making some assumptions about the solution and relating the error the nature of the solution (like the magnitude of estimated derivatives). Other generally smaller numerical errors arise from solving systems of equations to a specified tolerance, parallel consistency error and round-off error. In most circumstances these are much smaller than discretization error, but are still non-zero. The last area of uncertainty is the modeling uncertainty. In the vast majority of cases this will be the largest source of uncertainty, but of course there will be exceptions. It has three major components, the choice of the overall discrete model, the choice of models or equations themselves, and the coefficients defining the specific model. The first two areas are usually the largest part of the uncertainty, and unfortunately the most commonly ignored in assessments. The last area is the most commonly addressed because it is amenable to automatic evaluation. Even in this case the work is generally incomplete and lacks full disclosure of the uncertainty.
The last area of uncertainty is the modeling uncertainty. In the vast majority of cases this will be the largest source of uncertainty, but of course there will be exceptions. It has three major components, the choice of the overall discrete model, the choice of models or equations themselves, and the coefficients defining the specific model. The first two areas are usually the largest part of the uncertainty, and unfortunately the most commonly ignored in assessments. The last area is the most commonly addressed because it is amenable to automatic evaluation. Even in this case the work is generally incomplete and lacks full disclosure of the uncertainty. repeated using values drawn to efficiently sample the probability space of the calculation and produce the uncertainty. This sampling is done for a very highly dimensional space, and carries significant errors. More often than not the degree of error associated with the under sampling is not included in the results. It most certainly should be.
repeated using values drawn to efficiently sample the probability space of the calculation and produce the uncertainty. This sampling is done for a very highly dimensional space, and carries significant errors. More often than not the degree of error associated with the under sampling is not included in the results. It most certainly should be. Every September my wife and I attend the local TeDx event here in Albuquerque. It is a marvelous way to spend the day, and leaves a lasting impression on us. We immerse ourselves in inspiring, fresh ideas surrounded by like-minded people. It is empowering and wonderful to see the local community of progressive people together at once listening, interacting and absorbing a selection of some of the best ideas in our community. This year’s event was great and as always several talks stood out particularly including Jannell MacAulay (Lt.
Every September my wife and I attend the local TeDx event here in Albuquerque. It is a marvelous way to spend the day, and leaves a lasting impression on us. We immerse ourselves in inspiring, fresh ideas surrounded by like-minded people. It is empowering and wonderful to see the local community of progressive people together at once listening, interacting and absorbing a selection of some of the best ideas in our community. This year’s event was great and as always several talks stood out particularly including Jannell MacAulay (Lt. Col USAF) talking about applying mindfulness to work and life, or Olivia Gatwood inspiring poetry about the seeming mundane aspects of life that speaks to far deeper issues in society. The smallest details are illustrative of the biggest concerns. Both of these talks made me want to think deeply about applying these lessons in some fashion to myself and improving my life consequentially.
Col USAF) talking about applying mindfulness to work and life, or Olivia Gatwood inspiring poetry about the seeming mundane aspects of life that speaks to far deeper issues in society. The smallest details are illustrative of the biggest concerns. Both of these talks made me want to think deeply about applying these lessons in some fashion to myself and improving my life consequentially.
 We have transitioned from an animal fighting for survival during brief violent lives, to beings capable of higher thought and aspiration during unnaturally long and productive lives. We can think and invent new things instead of simply fighting to feed us and reproduce a new generation of humans to struggle in an identical manner. We also can produce work whose only value is beauty and wonder. TeD provides a beacon for human’s best characteristics along with a hopeful forward-looking community committed to positive common values. It is a powerful message that I’d like to take with me every day. I’d like to live out this promise with my actions, but the reality of work and life comes up short.
We have transitioned from an animal fighting for survival during brief violent lives, to beings capable of higher thought and aspiration during unnaturally long and productive lives. We can think and invent new things instead of simply fighting to feed us and reproduce a new generation of humans to struggle in an identical manner. We also can produce work whose only value is beauty and wonder. TeD provides a beacon for human’s best characteristics along with a hopeful forward-looking community committed to positive common values. It is a powerful message that I’d like to take with me every day. I’d like to live out this promise with my actions, but the reality of work and life comes up short. TeD talks are often the focus of criticism for their approach and general marketing nature strongly associated with the performance art nature. These critiques are valid and worth considering including the often-superficial nature of how difficult topics are covered. In many ways where research papers can be criticized increasingly as merely being the marketing of the actual work, TeD talks are simply the 30-second mass market advertisement of big ideas for big problems. Still the talks provide a deeply inspiring pitch for big ideas that one can follow up on and provide the entry to something much better. I find the talk is a perfect opening to learning or thinking more about a topic, or merely being exposed to something new.
TeD talks are often the focus of criticism for their approach and general marketing nature strongly associated with the performance art nature. These critiques are valid and worth considering including the often-superficial nature of how difficult topics are covered. In many ways where research papers can be criticized increasingly as merely being the marketing of the actual work, TeD talks are simply the 30-second mass market advertisement of big ideas for big problems. Still the talks provide a deeply inspiring pitch for big ideas that one can follow up on and provide the entry to something much better. I find the talk is a perfect opening to learning or thinking more about a topic, or merely being exposed to something new. not identify a single thing recommended in Pink’s book that made it to the workplace. It seemed to me that the book simply inspired the management to a set of ideals that could not be realized. The managers aren’t really in charge; they are simply managing the corporate compliance instead of managing in a way that maximizes the performance of its people. The Lab isn’t about progress any more; it is about everything, but progress. Compliance and subservience has become the raison d’etre.
not identify a single thing recommended in Pink’s book that made it to the workplace. It seemed to me that the book simply inspired the management to a set of ideals that could not be realized. The managers aren’t really in charge; they are simply managing the corporate compliance instead of managing in a way that maximizes the performance of its people. The Lab isn’t about progress any more; it is about everything, but progress. Compliance and subservience has become the raison d’etre.
 is progressive in terms of the business world. The problem is that the status quo and central organizing principle today is anti-progressive. Progress is something everyone is afraid of, and the future appears to be terrifying and worth putting off for as long as possible. We see genuinely horrible lurch toward an embrace of the past along with all its anger, bigotry, violence and fear. Fear is the driving force for avoiding anything that looks progressive.
is progressive in terms of the business world. The problem is that the status quo and central organizing principle today is anti-progressive. Progress is something everyone is afraid of, and the future appears to be terrifying and worth putting off for as long as possible. We see genuinely horrible lurch toward an embrace of the past along with all its anger, bigotry, violence and fear. Fear is the driving force for avoiding anything that looks progressive. Still I can offer a set of TeD talks that have both inspired me and impacted my life for the better. They have either encouraged me to learn more, or make a change, or simply change perspective. I’ll start with a recent one where David Baron gave us an incredibly inspiring call to see the total eclipse in its totality (
Still I can offer a set of TeD talks that have both inspired me and impacted my life for the better. They have either encouraged me to learn more, or make a change, or simply change perspective. I’ll start with a recent one where David Baron gave us an incredibly inspiring call to see the total eclipse in its totality ( Durkee finding a wonderful community center with a lawn and watched it with 50 people from all over the local area plus a couple from Berlin! The totality of the eclipse lasted only two minutes. It was part of a 22-hour day of driving over 800 miles, and it was totally and completely worth every second! Seeing the totality was one of the greatest experiences I can remember. My life was better for it, and my life was better for watching that TeD talk.
Durkee finding a wonderful community center with a lawn and watched it with 50 people from all over the local area plus a couple from Berlin! The totality of the eclipse lasted only two minutes. It was part of a 22-hour day of driving over 800 miles, and it was totally and completely worth every second! Seeing the totality was one of the greatest experiences I can remember. My life was better for it, and my life was better for watching that TeD talk. Another recent talk really provoked me to think about my priorities. It is a deep consideration of what your priorities are in terms of your health. Are you better off going to the gym or going to party, or the bar? Conventional wisdom says the gym will extend your life the most, but perhaps not. Susan Pinker provides a compelling case that social connection is the key to longer life (
Another recent talk really provoked me to think about my priorities. It is a deep consideration of what your priorities are in terms of your health. Are you better off going to the gym or going to party, or the bar? Conventional wisdom says the gym will extend your life the most, but perhaps not. Susan Pinker provides a compelling case that social connection is the key to longer life (
 struggle is for good reasons, and knowing the reasons provides insight to solutions. Perel powerfully explains the problem and speaks to working toward solutions.
struggle is for good reasons, and knowing the reasons provides insight to solutions. Perel powerfully explains the problem and speaks to working toward solutions. other reason that I usually don’t. I will close by honoring the inspirational gift of Olivia Gatwood’s talk on poetry about seeking beauty and meaning in the mundane. I’ll write a narrative of a moment in my life that touched me deeply.
other reason that I usually don’t. I will close by honoring the inspirational gift of Olivia Gatwood’s talk on poetry about seeking beauty and meaning in the mundane. I’ll write a narrative of a moment in my life that touched me deeply. movie “Fight Club” again. This is my 300th blog post here. Its been an amazing experience thanks for reading.
movie “Fight Club” again. This is my 300th blog post here. Its been an amazing experience thanks for reading. McDonalds for my first job. I was a hard worker, and a kick ass grill man, opener, closer, and whatever else I did. I became a manager and ultimately the #2 man at a store. Still I was 100% replaceable and in no way essential, the store worked just fine without me. I was interchangeable with another hard working person. It isn’t really the best feeling; you’d like to be a person whose imprint on the World means something. This is an aspiration worth having, and when your work is truly creative, you add value in a way that no one else can replicate.
McDonalds for my first job. I was a hard worker, and a kick ass grill man, opener, closer, and whatever else I did. I became a manager and ultimately the #2 man at a store. Still I was 100% replaceable and in no way essential, the store worked just fine without me. I was interchangeable with another hard working person. It isn’t really the best feeling; you’d like to be a person whose imprint on the World means something. This is an aspiration worth having, and when your work is truly creative, you add value in a way that no one else can replicate. of an incubator for aspiring scientists. You were encouraged to think of the big picture, and the long term while learning and growing. The Lab was a warm and welcoming place where people were generous with knowledge, expertise and time. It was still hard work and incredibly demanding, but all in the spirit of service and work with value. I repaid the generosity through learning and growing as a professional. It was an amazing place to work, an incredible place to be, an environment to be treasured, and made me who I am today.
of an incubator for aspiring scientists. You were encouraged to think of the big picture, and the long term while learning and growing. The Lab was a warm and welcoming place where people were generous with knowledge, expertise and time. It was still hard work and incredibly demanding, but all in the spirit of service and work with value. I repaid the generosity through learning and growing as a professional. It was an amazing place to work, an incredible place to be, an environment to be treasured, and made me who I am today. e scientific culture there were relabeled as “butthead cowboys,” troublemakers, and failures. The culture that was generous, long term in thought, viewing the big picture and focused on National service was haphazardly dismantled. Empowerment was ripped away from the scientists and replaced with control. Caution replaced boldness, management removed generosity, all in the name of formality of operations that removes anything unforeseen in outcomes. The modern world wants assured performance. Today Los Alamos is mere shadow of itself, stumbling forward toward the abyss of mediocrity. Witnessing this happen was one of the greatest tragedies of my life.
e scientific culture there were relabeled as “butthead cowboys,” troublemakers, and failures. The culture that was generous, long term in thought, viewing the big picture and focused on National service was haphazardly dismantled. Empowerment was ripped away from the scientists and replaced with control. Caution replaced boldness, management removed generosity, all in the name of formality of operations that removes anything unforeseen in outcomes. The modern world wants assured performance. Today Los Alamos is mere shadow of itself, stumbling forward toward the abyss of mediocrity. Witnessing this happen was one of the greatest tragedies of my life. importance. Everything is process today and anything bad can be managed out of existence. No one looks at the downside to this, and the downside is sinister to the quality of the workplace.
importance. Everything is process today and anything bad can be managed out of existence. No one looks at the downside to this, and the downside is sinister to the quality of the workplace. Instead of encouraging and empowering our people to take risks while tolerating and learning from failure, we do the opposite. We steer people away from doing risky work, punish failure and discourage lesson learning. It is as if we had suddenly become believers in the “free lunch”. True achievement is extremely difficult, and true achievement is powered by the ability to try to do risky almost impossible things. If failure is not used as an opportunity to learn, people will become disempowered and avoid the risks. This in turn will kill achievement before it can even be thought of. The entire system would seem to be designed to disempower people, and lower their potential for achievement.
Instead of encouraging and empowering our people to take risks while tolerating and learning from failure, we do the opposite. We steer people away from doing risky work, punish failure and discourage lesson learning. It is as if we had suddenly become believers in the “free lunch”. True achievement is extremely difficult, and true achievement is powered by the ability to try to do risky almost impossible things. If failure is not used as an opportunity to learn, people will become disempowered and avoid the risks. This in turn will kill achievement before it can even be thought of. The entire system would seem to be designed to disempower people, and lower their potential for achievement. the knowledge necessary to mentor others. This was a key aspect of my early career experience at Los Alamos. At that time the Lab was teeming with experts who were generous with their time and knowledge. All you had to do was reach out and ask, and people helped you. The experts were eager to share their experience and knowledge with others in a spirit of collective generosity. Today we are managed to completely avoid this with managed time and managed focus. We are trained to not be generous because that generosity would rob our “customers” of our effort and time. The flywheel of the experts of today helping to create the experts of tomorrow is being undone. People are trained to neither ask, nor provide expertise freely.
the knowledge necessary to mentor others. This was a key aspect of my early career experience at Los Alamos. At that time the Lab was teeming with experts who were generous with their time and knowledge. All you had to do was reach out and ask, and people helped you. The experts were eager to share their experience and knowledge with others in a spirit of collective generosity. Today we are managed to completely avoid this with managed time and managed focus. We are trained to not be generous because that generosity would rob our “customers” of our effort and time. The flywheel of the experts of today helping to create the experts of tomorrow is being undone. People are trained to neither ask, nor provide expertise freely. It is where we find ourselves today. We also know that the state of affairs can be significantly better. How can we get there from here? The first step would be some sort of collective decision that the current system isn’t working. From my perspective, the malaise and lack effectiveness of our current system is so pervasive and evident that action to correct it is overdue. On the other hand, the current system serves the purposes of those in control quite well, and they are not predisposed to be agents of change. As such, the impetus for change is almost invariably external. It is usually extremely painful because the status quo does not want to be rooted out unless it is forced to. The circumstances need to demand performance that current system cannot produce, and as systems degrade this becomes ever more likely.
It is where we find ourselves today. We also know that the state of affairs can be significantly better. How can we get there from here? The first step would be some sort of collective decision that the current system isn’t working. From my perspective, the malaise and lack effectiveness of our current system is so pervasive and evident that action to correct it is overdue. On the other hand, the current system serves the purposes of those in control quite well, and they are not predisposed to be agents of change. As such, the impetus for change is almost invariably external. It is usually extremely painful because the status quo does not want to be rooted out unless it is forced to. The circumstances need to demand performance that current system cannot produce, and as systems degrade this becomes ever more likely. and not lose all the good things in the process. Bad things, bad outcomes and bad behavior happen, and perhaps need to happen to have all the good (in other words “shit happens”). Today we are gripped with a belief that negative outcomes can be managed away. In the process of managing away bad outcomes, we destroy the foundation of everything good. To put it differently we need to value the good and accept the bad as a necessary condition for enabling good outcomes. If one looks at failure as the engine of learning, we begin to realize that the bad is the foundation of the good. If we do not allow the bad things to happen, let people fuck things up, we can’t have really good things either. One requires the other and our attempts to control bad outcomes, removes a lot of good or even great outcomes at the same time.
and not lose all the good things in the process. Bad things, bad outcomes and bad behavior happen, and perhaps need to happen to have all the good (in other words “shit happens”). Today we are gripped with a belief that negative outcomes can be managed away. In the process of managing away bad outcomes, we destroy the foundation of everything good. To put it differently we need to value the good and accept the bad as a necessary condition for enabling good outcomes. If one looks at failure as the engine of learning, we begin to realize that the bad is the foundation of the good. If we do not allow the bad things to happen, let people fuck things up, we can’t have really good things either. One requires the other and our attempts to control bad outcomes, removes a lot of good or even great outcomes at the same time.