
If you want a new tomorrow, then make new choices today.
― Tim Fargo
Ultimately the importance of what we compute is determined by how useful the results are. Are the results good at explaining something we see in nature, confirming an idea, providing concrete evidence of how a scenario might unfold, or helping create a better widget? The classical uses of scientific computing are solving initial value problems and large-scale data analysis each of which can play a role in the answering the above questions. How much have we moved bey  ond this classical view in the 70 or so years the field has existed?
ond this classical view in the 70 or so years the field has existed?
I think the answer is “not nearly enough,” and computing is failing to deliver on its full potential as a result.
Never attribute to malice that which can be adequately explained by stupidity.
― Robert Hanlon
 Scientific computing is still dominated by the same two big uses that existed at the beginning. Recently data analysis has reasserted itself as the big “new” thing. This is mostly the consequence of the deluge of data coming from the Internet, and the impending Internet of things. For mainstream science, the initial value problem still holds sway for a broader set of activities although data is big in astronomy, geophysics and social sciences.
Scientific computing is still dominated by the same two big uses that existed at the beginning. Recently data analysis has reasserted itself as the big “new” thing. This is mostly the consequence of the deluge of data coming from the Internet, and the impending Internet of things. For mainstream science, the initial value problem still holds sway for a broader set of activities although data is big in astronomy, geophysics and social sciences.
To change ourselves effectively, we first had to change our perceptions.
― Stephen R. Covey
 The problem is that bigger, better things are possible if we simply marshal our efforts properly. Computing has the potential to reshape our ability to design through combining our forward simulations with optimization. The same could be done with data analysis to power calibration of models. Another powerful would be a pervasive analysis of uncertainties in our modeling. Almost all of these cases have direct analogs in the World of data analysis. Together this array of untapped potential would contribute greatly to our understanding and mastery of nature.
The problem is that bigger, better things are possible if we simply marshal our efforts properly. Computing has the potential to reshape our ability to design through combining our forward simulations with optimization. The same could be done with data analysis to power calibration of models. Another powerful would be a pervasive analysis of uncertainties in our modeling. Almost all of these cases have direct analogs in the World of data analysis. Together this array of untapped potential would contribute greatly to our understanding and mastery of nature.
Engineers like to solve problems. If there are no problems handily available, they will create their own problems.
― Scott Adams
What is holding us back?
Probably the greatest issue holding us back is our absolute intolerance of risk. It is always less risky to incrementally improve what you are already doing. This has become the singular focus of science today. Making small improvements to something that is already deemed a success is a path to avoiding failure, “building on success”. Most progress looks like this, and today almost all progress looks like this. To get more out of computing, we need to risk doing something really new, and with that risk comes the possibility of failure. Without that risk the level of success that may be achieved is also much lower. I believe that this is the main driver behind not taking advantage of computing.
Evolution is more about adaptivity than adaptability.
― Raheel Farooq
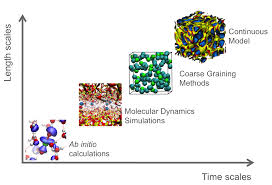 This modern pathology also creates a myriad of side effects. One of the engines of innovation is applied mathematics where the act of playing it safe is sapping the vitality from the field. Increasingly the applied math work is focused on ideal model problems, and eschews the difficult work of attacking real problems, or problems where the math is messy. Without a more applied and more daring approach to developing capabilities, the innovative energy will not be unleashed. Part of the innovation means simply trying new things whether or not it is amenable to analysis. Work is guided by importance and utility rather than tractability.
This modern pathology also creates a myriad of side effects. One of the engines of innovation is applied mathematics where the act of playing it safe is sapping the vitality from the field. Increasingly the applied math work is focused on ideal model problems, and eschews the difficult work of attacking real problems, or problems where the math is messy. Without a more applied and more daring approach to developing capabilities, the innovative energy will not be unleashed. Part of the innovation means simply trying new things whether or not it is amenable to analysis. Work is guided by importance and utility rather than tractability.
Life’s journey is built of crests and troughs, the movement is always going to be fast only towards the trough and the progress is bound to be slow towards the crest.
― Anuj Somany
 A good place to look at where analysis should be applied is to methods that work. The topic of compressed sensing is a great example. By the time compressed sensing was “invented” it had been in use for 30 years as a practical approach in several fields, but lacked theoretical support. When the theoretical support arrived from some of the best mathematicians alive today, the field exploded. New uses for this old methodology are discovered almost every day. It is an example of what a coherent theory can do for a field. Without the theory, the topic was stranded as a “trick” and its applicability was limited. With the theory the applications that could be attempted grew immensely (and continues to grow).
A good place to look at where analysis should be applied is to methods that work. The topic of compressed sensing is a great example. By the time compressed sensing was “invented” it had been in use for 30 years as a practical approach in several fields, but lacked theoretical support. When the theoretical support arrived from some of the best mathematicians alive today, the field exploded. New uses for this old methodology are discovered almost every day. It is an example of what a coherent theory can do for a field. Without the theory, the topic was stranded as a “trick” and its applicability was limited. With the theory the applications that could be attempted grew immensely (and continues to grow).
Our culture works hard to prevent change.
― Seth Godin
 Another place where we have systematically failed to advance appropriately is the simulation of stochastic or random phenomena. We are still devoted to solving almost everything in terms of a mean field theory. While the mean field view of the World has served us well, today many of our most important applications are driven by statistics. How often will something really good, or really bad happen? How much of a population of devices will fail in a certain may? How likely is a certain event? Today most of our simulation capability is ill suited to answering these questions. In many cases we try to answer these incorrectly by merely examining the uncertainty in the mean field solution (i.e., sampling uncertainty parametrically, which is not the same thing). Almost none of the simulation techniques are suitable for examining the variability of the systems being simulated.
Another place where we have systematically failed to advance appropriately is the simulation of stochastic or random phenomena. We are still devoted to solving almost everything in terms of a mean field theory. While the mean field view of the World has served us well, today many of our most important applications are driven by statistics. How often will something really good, or really bad happen? How much of a population of devices will fail in a certain may? How likely is a certain event? Today most of our simulation capability is ill suited to answering these questions. In many cases we try to answer these incorrectly by merely examining the uncertainty in the mean field solution (i.e., sampling uncertainty parametrically, which is not the same thing). Almost none of the simulation techniques are suitable for examining the variability of the systems being simulated.
If failure is not an option, then neither is success.
― Seth Godin
 The foundation of our limitations is not our intellectual abilities, but rather our taste for risk and change. With change and risk comes the potential for failure or unexpected outcomes. Lately, these sorts of things can’t be tolerated by our society. Without tolerance for bad things, our capacity to experience good things is undermined. Instead we are left to swim in an era of unmitigated mediocrity. It is sad that we’ve come to accept this as our mantra.
The foundation of our limitations is not our intellectual abilities, but rather our taste for risk and change. With change and risk comes the potential for failure or unexpected outcomes. Lately, these sorts of things can’t be tolerated by our society. Without tolerance for bad things, our capacity to experience good things is undermined. Instead we are left to swim in an era of unmitigated mediocrity. It is sad that we’ve come to accept this as our mantra.
Fear does that. We have become afraid of everything, and fearful of things we used to simply overcome.
I must not fear. Fear is the mind-killer. Fear is the little-death that brings total obliteration.
― Frank Herbert, Dune











 I don’t think software gets the support or respect it deserves particularly in scientific computing. It is simply too important to treat it the way we do. It should be regarded as an essential professional contribution and supported as such. Software shouldn’t be a one-time investment either; it requires upkeep and constant rebuilding to be healthy. Too often we pay for the first version of the code then do everything else on the cheap. The code decays and ultimately is overcome by technical debt. The final danger with code is the loss of the knowledge basis for the code itself. Too much scientific software is “magic” code that no one understands. If no one understands the code, the code is probably dangerous to use.
I don’t think software gets the support or respect it deserves particularly in scientific computing. It is simply too important to treat it the way we do. It should be regarded as an essential professional contribution and supported as such. Software shouldn’t be a one-time investment either; it requires upkeep and constant rebuilding to be healthy. Too often we pay for the first version of the code then do everything else on the cheap. The code decays and ultimately is overcome by technical debt. The final danger with code is the loss of the knowledge basis for the code itself. Too much scientific software is “magic” code that no one understands. If no one understands the code, the code is probably dangerous to use. computing. The connection to work of importance and value is essential to understand, and the lack of such understanding explains why our current trajectory is so problematic. Just to reiterate, the value of computing, or scientific computing is found in the real world. The real world is studied through the use of models in scientific computing that are most often differential equations. Using algorithms or methods we then solve these models. These models as interpreted by their solution methods or algorithms are expressed in computer code, which in turn runs on a computer.
computing. The connection to work of importance and value is essential to understand, and the lack of such understanding explains why our current trajectory is so problematic. Just to reiterate, the value of computing, or scientific computing is found in the real world. The real world is studied through the use of models in scientific computing that are most often differential equations. Using algorithms or methods we then solve these models. These models as interpreted by their solution methods or algorithms are expressed in computer code, which in turn runs on a computer.
 More importantly software often outlives the people responsible for the intellectual capital represented in it. A real danger is the loss of expertise in what the software is actually doing. There is a specific and real danger in using software that isn’t understood. Many times the software is used as a library and not explicitly understood by the user. The software is treated as a storehouse of ideas, but if those ideas are not fully understood there is danger. It is important that the ideas in software be alive and fully comprehended.
More importantly software often outlives the people responsible for the intellectual capital represented in it. A real danger is the loss of expertise in what the software is actually doing. There is a specific and real danger in using software that isn’t understood. Many times the software is used as a library and not explicitly understood by the user. The software is treated as a storehouse of ideas, but if those ideas are not fully understood there is danger. It is important that the ideas in software be alive and fully comprehended. 







 In watching the ongoing discussions regarding the National Exascale initiative many observations can be made. I happen to think the program is woefully out of balance, and focused on the wrong side of the value proposition for computing. In a nutshell it is stuck in the past.
In watching the ongoing discussions regarding the National Exascale initiative many observations can be made. I happen to think the program is woefully out of balance, and focused on the wrong side of the value proposition for computing. In a nutshell it is stuck in the past. to hardware. As the software gets closer to the application, the focus starts to drift. As the application gets closer and modeling is approached, the focus is non-existent. It is simply assumed that the modeling just needs a really huge computer and the waters will magically part and the path the promised land of predictive simulation will just appear. Science doesn’t work this way, or more correctly well functioning science doesn’t work like this. Science works with a push-pull relationship between theory, experiment and tools. Sometimes theory is pushing experiments to catch up. Sometimes tools are finding new things for theory to answer. Computing is such a tool, but it isn’t be allowed to push theory, or more properly theory should be changing to accommodate what the tools show us.
to hardware. As the software gets closer to the application, the focus starts to drift. As the application gets closer and modeling is approached, the focus is non-existent. It is simply assumed that the modeling just needs a really huge computer and the waters will magically part and the path the promised land of predictive simulation will just appear. Science doesn’t work this way, or more correctly well functioning science doesn’t work like this. Science works with a push-pull relationship between theory, experiment and tools. Sometimes theory is pushing experiments to catch up. Sometimes tools are finding new things for theory to answer. Computing is such a tool, but it isn’t be allowed to push theory, or more properly theory should be changing to accommodate what the tools show us.
 The question is whether there is some way to learn from everyone else. How can this centralized supercomputing be broken down in a way to help the productivity of the scientist. One of the things that happened when mainframes went away was an explosion of productivity. The centralized computing is quite unproductive and constrained. Computing today is the opposite, unconstrained and completely productive. It is completely integrated into the very fabric of our lives. Work and play are integrated too. Everything happens all the time at the same time. Instead of maintaining the old-fashioned model we should be looking into harvesting the best of modern computing to overthrow the old model.
The question is whether there is some way to learn from everyone else. How can this centralized supercomputing be broken down in a way to help the productivity of the scientist. One of the things that happened when mainframes went away was an explosion of productivity. The centralized computing is quite unproductive and constrained. Computing today is the opposite, unconstrained and completely productive. It is completely integrated into the very fabric of our lives. Work and play are integrated too. Everything happens all the time at the same time. Instead of maintaining the old-fashioned model we should be looking into harvesting the best of modern computing to overthrow the old model.
 drowning in data whether we are talking about the Internet in general, the coming “Internet of things” or the scientific use of computing. The future is going to be much worse and we are already overwhelmed. If we try to deal with every single detail, we are destined to fail.
drowning in data whether we are talking about the Internet in general, the coming “Internet of things” or the scientific use of computing. The future is going to be much worse and we are already overwhelmed. If we try to deal with every single detail, we are destined to fail.
 in all the noise and represent this importance compactly and optimally. This class of ideas will be important in managing the Tsunami of data that awaits us.
in all the noise and represent this importance compactly and optimally. This class of ideas will be important in managing the Tsunami of data that awaits us.
 be solved by exotic methods and algorithms. Ultimately, these methods and algorithms must be expressed as computer code before the computers can be turned loose on their approximate solution. These models are relics. The whole enterprise of describing the real world through these models arose from the efforts of intellectual giants starting with Newton and continuing with Leibnitz, Euler, and a host of brilliant 17th, 18th and 19th Century scientists. Eventually, if not almost immediately, models became virtually impossible to solve via available (analytical) methods except for a
be solved by exotic methods and algorithms. Ultimately, these methods and algorithms must be expressed as computer code before the computers can be turned loose on their approximate solution. These models are relics. The whole enterprise of describing the real world through these models arose from the efforts of intellectual giants starting with Newton and continuing with Leibnitz, Euler, and a host of brilliant 17th, 18th and 19th Century scientists. Eventually, if not almost immediately, models became virtually impossible to solve via available (analytical) methods except for a handful of special cases.
handful of special cases. When computing came into use in the middle of the 20th Century some of these limitations could be lifted. As computing matured fewer and fewer limitations remained, and the models of the past 300 years became accessible to solution albeit through approximate means. The success has been stunning as the combination of intellectual labor on methods and algorithms along with computer code, and massive gains in hardware capability have transformed our view of these models. Along the way new phenomena have been recognized including dynamical systems or chaos opening doors to understanding the World. Despite the progress I believe we have much more to achieve.
When computing came into use in the middle of the 20th Century some of these limitations could be lifted. As computing matured fewer and fewer limitations remained, and the models of the past 300 years became accessible to solution albeit through approximate means. The success has been stunning as the combination of intellectual labor on methods and algorithms along with computer code, and massive gains in hardware capability have transformed our view of these models. Along the way new phenomena have been recognized including dynamical systems or chaos opening doors to understanding the World. Despite the progress I believe we have much more to achieve. Today we are largely holding to the models of reality developed prior to the advent of computing as a means of solution. The availability of solution has not yielded the balanced examination of the models themselves. These models are
Today we are largely holding to the models of reality developed prior to the advent of computing as a means of solution. The availability of solution has not yielded the balanced examination of the models themselves. These models are effectively. This gets to the core of studying uncertainty in physical systems. We need to overhaul our approach of reality to really come to grips with this. Computers, code and algorithms are probably at or beyond the point where this can be tackled.
effectively. This gets to the core of studying uncertainty in physical systems. We need to overhaul our approach of reality to really come to grips with this. Computers, code and algorithms are probably at or beyond the point where this can be tackled. Here is the problem. Despite the need for this sort of modeling, the efforts in computing are focused at the opposite end of the spectrum. Current funding and focus is aimed at the computing hardware, and code with little effort being applied to algorithms, methods and models. The entire enterprise needs a serious injection of intellectual energy in the proper side of the value proposition.
Here is the problem. Despite the need for this sort of modeling, the efforts in computing are focused at the opposite end of the spectrum. Current funding and focus is aimed at the computing hardware, and code with little effort being applied to algorithms, methods and models. The entire enterprise needs a serious injection of intellectual energy in the proper side of the value proposition.
 For solution verification the problem is much worse. Even when solution verification is done we are missing important details. The biggest problem is the lack of solution verification for the application of scientific computing to problems. Usually the problem is simply computed and graphs are overlaid, and success is declared. The comparison looks good enough. No sense of whether the solution is accurate is given at least quantitatively. An error estimate for the solution shown, or better yet a convergence study would provide much enhanced faith in the results. In addition to the numerical error, the rate of convergence would also provide information on the tangible expectations for the solution for practical problems. Today such expectations are largely left to be guessed by the reader.
For solution verification the problem is much worse. Even when solution verification is done we are missing important details. The biggest problem is the lack of solution verification for the application of scientific computing to problems. Usually the problem is simply computed and graphs are overlaid, and success is declared. The comparison looks good enough. No sense of whether the solution is accurate is given at least quantitatively. An error estimate for the solution shown, or better yet a convergence study would provide much enhanced faith in the results. In addition to the numerical error, the rate of convergence would also provide information on the tangible expectations for the solution for practical problems. Today such expectations are largely left to be guessed by the reader.

 he
he  relative value and priority of each is different. A lot depends on what the pacing requirements for progress are, but the focus of the value proposition should be an imperitive.
relative value and priority of each is different. A lot depends on what the pacing requirements for progress are, but the focus of the value proposition should be an imperitive. The secondary fuel for this revolution is the model of interaction and the algorithms to efficiently deliver the value. The actual code and compute needs of this delivery needs to be competently executed, but beyond that offer nothing distinguishing to it. This is a massive lesson right in front of the scientific community, which seems to be not understood these observations as measured by its actions. Today’s computing for
The secondary fuel for this revolution is the model of interaction and the algorithms to efficiently deliver the value. The actual code and compute needs of this delivery needs to be competently executed, but beyond that offer nothing distinguishing to it. This is a massive lesson right in front of the scientific community, which seems to be not understood these observations as measured by its actions. Today’s computing for  science emphasis has completely inverted the value stream revolutionizing computing in the rest of the World.
science emphasis has completely inverted the value stream revolutionizing computing in the rest of the World.
 Modeling must always be improving. If we are doing our computing correctly the models we use should continually be coming up short. Instead, the models seem to be completely frozen in time. They aren’t advancing. For example, I believe we should be undoing the chains of determinism in simulation, but even today deterministic simulations are virtually all of the workload.
Modeling must always be improving. If we are doing our computing correctly the models we use should continually be coming up short. Instead, the models seem to be completely frozen in time. They aren’t advancing. For example, I believe we should be undoing the chains of determinism in simulation, but even today deterministic simulations are virtually all of the workload. foundation of value in scientific computing that is found foremost in models and their solution via algorithms and methods. The other aspect that has been systematically shortchanged is the value of the people who provide the ideas that form model, methods and algorithms. Ultimately, the innovation in scientific computing is the intellectual labor of talented individuals.
foundation of value in scientific computing that is found foremost in models and their solution via algorithms and methods. The other aspect that has been systematically shortchanged is the value of the people who provide the ideas that form model, methods and algorithms. Ultimately, the innovation in scientific computing is the intellectual labor of talented individuals.