
Mathematics is the door and key to the sciences.
— Roger Bacon
 It is time to return to great papers of the past. The past has clear lessons about how progress can be achieved. Here, I will discuss a trio of papers that came at a critical juncture in the history of numerically solving hyperbolic conservation laws. In a sense, these papers were nothing new, but provided a systematic explanation and skillful articulation of the progress at that time. In a deep sense these papers represent applied math at its zenith, providing a structural explanation along with proof to accompany progress made by others. These papers helped mark the transition of modern methods from heuristic ideas to broad adoption and common use. Interestingly, the depth of applied mathematics ended up paving the way for broader adoption in the engineering world. This episode also provides a cautionary lesson about what holds higher order methods back from broader acceptance, and the relatively limited progress since.
It is time to return to great papers of the past. The past has clear lessons about how progress can be achieved. Here, I will discuss a trio of papers that came at a critical juncture in the history of numerically solving hyperbolic conservation laws. In a sense, these papers were nothing new, but provided a systematic explanation and skillful articulation of the progress at that time. In a deep sense these papers represent applied math at its zenith, providing a structural explanation along with proof to accompany progress made by others. These papers helped mark the transition of modern methods from heuristic ideas to broad adoption and common use. Interestingly, the depth of applied mathematics ended up paving the way for broader adoption in the engineering world. This episode also provides a cautionary lesson about what holds higher order methods back from broader acceptance, and the relatively limited progress since.
The three papers I will focus on are:
Harten, Ami. “High resolution schemes for hyperbolic conservation laws.” Journal of computational physics 49, no. 3 (1983): 357-393.
Harten, Ami. “On a class of high resolution total-variation-stable finite-difference schemes.” SIAM Journal on Numerical Analysis 21, no. 1 (1984): 1-23.
Sweby, Peter K. “High resolution schemes using flux limiters for hyperbolic conservation laws.” SIAM journal on numerical analysis 21, no. 5 (1984): 995-1011.
The first two are by the late Ami Harten providing a proof of the monotone behavior seen with the heuristic methods existing at that time. The proofs provided some confidence to many that had been lacking from the truly innovative, but largely heuristic invention of the methods. The third paper by Peter Sweby provided a clear narrative and an important graphical tool for understanding these methods and displaying limiters, the nonlinear mechanism that produced the great results. The “Sweby diagram” was the reduction of these complex nonlinear methods to a nonlinear function. The limiter was then a switch between two commonly used classical methods. The diagram produced a simple way of seeing whether any given limiter was going to give second-order non-oscillatory results. Together these three papers paved the way for common adoption of these methods.
Mathematics is the art of giving the same name to different things.
– Henri Poincaré


In the 1970’s three researchers principally invented these nonlinear methods, Jay Boris, Bram Van Leer, and Vladimir Kolgan. Of these three Boris and Van Leer achieved fame and great professional success. The methods were developed heuristically and worked very well. Each of these methods explicitly worked to overcome Godunov’s barrier theorem that says a second-order linear method cannot be monotone. Both made the methods nonlinear through adapting the approximation based on the local structure of the solution. Interestingly Boris and Van Leer were physicists, Kolgan was an engineer (Van Leer went on to work extensively in engineering). Kolgan was a Russian in the Soviet Union and died before his discovery could take its rightful place next to Boris and Van Leer (Van Leer has gone to great effort to correct the official record).
[Mathematics] is security. Certainty. Truth. Beauty. Insight. Structure. Architecture. I see mathematics, the part of human knowledge that I call mathematics, as one thing—one great, glorious thing. Whether it is differential topology, or functional analysis, or homological algebra, it is all one thing. … They are intimately interconnected, they are all facets of the same thing. That interconnection, that architecture, is secure truth and is beauty. That’s what mathematics is to me.
― Paul R. Halmos
The problem with all these methods was a lack of mathematical certainty on the quality of results along with proofs and structured explanations of their success. This made the broader community a bit suspicious of the results. In a flux corrected transport (FCT, Boris’ invention) commemorative volume this suspicion is noted. At conferences, there were questions raised about the results that implied that the solutions were faked. The breakthrough with these new methods was that good, too good to be true. Then the explanations came and made a strong connection to theory. The behavior seen in the results had a strong justification in mathematics, and the trust in the methodology grew. Acceptance came on the heals of this trust and widespread adoption.
Harten and others continued to search for even better methods after introducing TVD schemes. The broad category of essentially non-oscillatory (ENO) methods was invented. It has been a broad research success, but never experienced the wide spread adoption that these other methods enjoyed. Broadly speaking, the TVD methods are used in virtually every production code for solving hyperbolic conservation laws. In the physics world, many use Van Leer’s approach and engineering uses Harten-Sweby’s formalism broadly. FCT is used somewhat in the physics world, but its adoption is far less common. Part of the reason for this disparity comes down to the power of mathematical proof and the faith it gives. The lack of success of follow-on methods to get adoption and have success comes from the lack of strong theory with its requisite confidence. Faith, confidence and systematic explanation are all provided by well executed applied mathematics.
What is TVD the theory and how does it work?
(Note: WordPress’ Latex capability continues to frustrate, I cannot get them to typeset so if you can read TeX the equations will make sense)
In a nutshell, TVD is a way of extending the behavior of monotone methods (upwind for the purposes of this discussion) to high-order nonlinear methods. Upwind methods have the benefit of positive coefficients in their stencil. If we write this down for a scalar advection equation, 



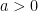
 What Sweby did was provide a wonderful narrative description of TVD methods, and a graphical manner to depict them. In the form that Sweby described, TVD methods were a nonlinear combination of classical methods: upwind, Lax-Wendroff and Beam Warming. The limiter was drawn out of the formulation and parameterized by the ratio of local finite differences. The limiter is a way to take an upwind method and modify it with some part of the selection of second-order methods and satisfy the inequalities needed to be TVD. This technical specification took the following form, $ C_{j-1/2} = \nu \left( 1 + 1/2\nu(1-\nu) \phi\ledt(r_{j-1/2}\right) \right) $ and
What Sweby did was provide a wonderful narrative description of TVD methods, and a graphical manner to depict them. In the form that Sweby described, TVD methods were a nonlinear combination of classical methods: upwind, Lax-Wendroff and Beam Warming. The limiter was drawn out of the formulation and parameterized by the ratio of local finite differences. The limiter is a way to take an upwind method and modify it with some part of the selection of second-order methods and satisfy the inequalities needed to be TVD. This technical specification took the following form, $ C_{j-1/2} = \nu \left( 1 + 1/2\nu(1-\nu) \phi\ledt(r_{j-1/2}\right) \right) $ and 
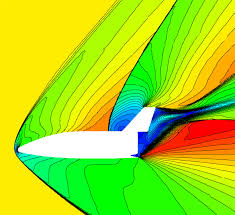
Beyond the power of applied mathematics, other aspects of the technical problem have contributed to the subsequent lack of progress. The biggest issue is the quantum leap in performance from first- to second-order accuracy. The second order methods produce results that seem turbulent because first-order methods produce a truncation error that laminarizes flows. The second-order method produces results for complex problems that have the look and feel of real flows (this may also be quantitatively true, but the jury is out). Important flows are turbulent, high energy with very large Reynolds numbers. First-order schemes cannot produce these realistically at all. Second-order methods can, and for this reason the new schemes unleashed utility upon the World. With these methods, the solutions took on the look, feel and nature of reality. For this reason, these schemes became essential for codes.
The second reason is the robustness of these methods. First-order monotone methods like upwind are terribly robust. These methods produce physically admissible solutions and do not fail often. Codes run problems to completion. The reason is their extremely dissipative nature. This makes them very attractive for difficult problems and almost guarantees a solution for the calculation. The same dissipation also destroys almost every structure in the solution and smears out all the details that matter. You get answer, but an answer that is fuzzy and inaccurate. These first order methods end up being as extremely expensive when accuracy is desired. Harten’s TVD methods provided a systematic connection of the new second-order methods to the old reliable first-order methods. The new methods were almost as reliable as the first-order methods, but got rid of much of the smearing dissipation that plagued them. Having a structured and expertly produced explanation for the behavior of these methods with clear connections to things people already knew produced rapid adoption by practitioners.
Mathematics is the cheapest science. Unlike physics or chemistry, it does not require any expensive equipment. All one needs for mathematics is a pencil and paper.
― George Pólya
The follow-on efforts with higher than second-order methods have lacked these clear wins. It is clear that going past second-order does not provide the same sort of quantum leap in results. The clear connection and expectations of robustness is also lacking. The problems do not stop there. The essentially non-oscillatory methods select the least oscillatory local approximation, which also happens to be quite dissipative by its very nature. Quite often the high-order method is actually not threatening oscillations at all yet a less accurate approximation is chosen needlessly reducing accuracy. Furthermore, the adaptive approximation selection can preferentially choose unstable approximation in an evolutionary sense, which can result in catastrophe. The tendency to produce the worst of both Worlds has doomed their success and broad adoption. Who wants dissipative and fragile? No one! No production code would make these choices, ever!
Recent efforts have sought to rectify this shortcoming. Weighted ENO methods (WENO) have provided far less intrinsically dissipative methods that also enhance the accuracy. These methods are still relatively dissipative compared to the best TVD methods and invoke their expensive approximations needlessly in regions of the solution where the nonlinear mechanisms are unnecessary. Efforts have produced positivity preserving methods that avoid the production of inherently unphysical results with high-order methods. These developments are certainly a step in the right direction. The current environment of producing new legacy codes is killing any other the energy to stewart these methods into broad adoption. The expense, overly dissipative nature and relatively small payoff all stand in the way.
What might help in making progress past second-order methods?
The first thing to note is that TVD methods are mixed in their order of accuracy. They are second-order in a very loose sense and only when one takes the most liberal norm for computations (L1 for you nerds out there). For the worst-case error, TVD methods are still first-order (L-infinity, and multiple dimensions). This is a pretty grim picture until one also realizes that for nonlinear PDEs with general solutions, first-order accuracy is all you get anyway unless you are willing to track all discontinuities. These same conditions hold for high-order methods we might like to adopt. The accuracy from the new methods is always quite limited and puts a severe constraint on the efficiency of the methods, and a challenge to development and progress. The effort that it takes to get full accuracy for nonlinear problems is quite large, and if this accuracy is not realized, the effort is not worth it. We do know that some basic elements of high-order methods yield substantial benefits, but these benefits are limited (an example are high-order edge values used in the piecewise parabolic method – PPM).
I asked myself, what worked so well for TVD? To me there is a clear and unambiguous connection to what worked in the past. The past was defined by the combination of upwind, Lax-Wendroff, and Beam-Warming methods. These methods along with largely ad hoc stabilization mechanisms provided the backbone of production codes preceding the introduction of these methods. Now TVD schemes form the backbone of production codes. It would seem that new higher order methods should preserve this sort of connection. ENO and WENO methods did not do this, which partially explains their lack of adoption. My suggestion would be a design of methods where one uses a high-order method that can be shown to be TVD, or the high-order method closest to a chosen TVD scheme. This selection would be high-order accurate by construction, but would also produce oscillations at third-order. This is not the design principle that ENO methods use where the unproven assertion is oscillations at the order of approximation. The tradeoff between these two principles is larger potential oscillations with less dissipation and a more unambiguous connection to the backbone TVD methods.
1. Everyone is entitled to their opinion about the things they read (or watch, or listen to, or taste, or whatever). They’re also entitled to express them online.
2. Sometimes those opinions will be ones you don’t like.
3. Sometimes those opinions won’t be very nice.
4. The people expressing those may be (but are not always) assholes.
5. However, if your solution to this “problem” is to vex, annoy, threaten or harrass them, you are almost certainlya bigger asshole.
6. You may also be twelve.
7. You are not responsible for anyone else’s actions or karma, but you are responsible for your own.
8. So leave them alone and go about your own life.
[Bad Reviews: I Can Handle Them, and So Should You(Blog post, July 17, 2012)]
― John Scalzi
 My own connection to this work is a nice way of rounding out this discussion. When I started looking at modern numerical methods, I started to look at the selection of approaches. FCT was the first thing I hit upon and tried. Compared to the classical methods I was using, it was clearly better, but its lack of theory was deeply unsatisfying. FCT would occasionally do weird things. TVD methods had the theory and this made is far more appealing to my technically immature mind. After the fact, I tried to project FCT methods onto the TVD theory. I wrote a paper documenting this effort. It was my first paper in the field. Unknowingly, I walked into a veritable mine field and complete shit show. All three of my reviewers were very well-known contributors to the field (I know it is supposed to be anonymous, and the shit show that unveiled itself, unveiled the reviewers too).
My own connection to this work is a nice way of rounding out this discussion. When I started looking at modern numerical methods, I started to look at the selection of approaches. FCT was the first thing I hit upon and tried. Compared to the classical methods I was using, it was clearly better, but its lack of theory was deeply unsatisfying. FCT would occasionally do weird things. TVD methods had the theory and this made is far more appealing to my technically immature mind. After the fact, I tried to project FCT methods onto the TVD theory. I wrote a paper documenting this effort. It was my first paper in the field. Unknowingly, I walked into a veritable mine field and complete shit show. All three of my reviewers were very well-known contributors to the field (I know it is supposed to be anonymous, and the shit show that unveiled itself, unveiled the reviewers too).
The end result was that the paper was never published. This decision occurred five years after it was submitted, and I had simply moved on. My first review was from Ami Harten who basically said this paper is awesome and publish it. He signed the review and sent me some lecture notes on the same topic. I was over the moon, and did call Ami and talk briefly. Six months later my second review came in. It was as different as possible from Ami’s. It didn’t say this exactly, but in a nutshell, it said the paper was a piece of shit. It still remains the nastiest and most visceral review I’ve ever gotten. It was technically flawless on one hand and thoroughly unprofessional in tone on the other. My third review came a year later and was largely editorial in nature. I revised the paper and resubmitted. While all this unfolded Ami died, and the journal it was submitted to descended into chaos partially due to the end of the cold war and its research largess. When it emerged from chaos, I decided to publish the work was largely pointless and not worth the effort.
Some commentary about why this shit show happened is worth explaining. It is all related to the holy war between two armed camps that arose via the invention of these methods and who gets the credit. The paper was attempting to bridge the FCT and TVD worlds, and stepped into the bitter fighting around previous publications. In retrospect, it is pretty clear that FCT was first, and others like Kolgan and Van Leer came after. Their methodologies and approaches were also fully independent, and the full similarity was not clear at the time. While the fullness of time sees these approaches are utterly complementary, at the time of development it was seen as a competition. It was definitely not a collaborative endeavor, and the professional disagreements were bitter. They poisoned the field and people took sides viewing the other side with vitriolic fury. A friend and associate editor of the Journal of Computational Physics quipped that this was one of the nastiest sub-communities in the Journal, and why did I insist on working in this area. It is also one of the most important areas in computational physics working on a very difficult problem. The whole field also hinges upon expert judgement and resists a firm quantitative standard of acceptance.
What an introduction to the field and its genuinely amazing that I continue to work in it at all. If I didn’t enjoy the technical content so much, and not appreciated the importance of the field, I would have run. Perhaps greater success professionally would have followed such a departure. In the long run this resistance and the rule of experts works to halt progress.
If you can’t solve a problem, then there is an easier problem you can solve: find it.
― George Pólya
Kolgan, V. P. “Application of the principle of minimum values of the derivative to the construction of finite-difference schemes for calculating discontinuous gasdynamics solutions.” TsAGI, Uchenye Zapiski 3, no. 6 (1972): 68-77.
Boris, Jay P., and David L. Book. “Flux-corrected transport. I. SHASTA, a fluid transport algorithm that works.” Journal of computational physics 11, no. 1 (1973): 38-69.
Van Leer, Bram. “Towards the ultimate conservative difference scheme. II. Monotonicity and conservation combined in a second-order scheme.” Journal of computational physics 14, no. 4 (1974): 361-370.\
Van Leer, Bram. “Towards the ultimate conservative difference scheme. V. A second-order sequel to Godunov’s method.” Journal of computational Physics 32, no. 1 (1979): 101-136.
Harten, Ami, Bjorn Engquist, Stanley Osher, and Sukumar R. Chakravarthy. “Uniformly high order accurate essentially non-oscillatory schemes, III.” Journal of computational physics 71, no. 2 (1987): 231-303.
Harten, Ami, and Stanley Osher. “Uniformly high-order accurate nonoscillatory schemes. I.” SIAM Journal on Numerical Analysis 24, no. 2 (1987): 279-309.
Harten, Amiram, James M. Hyman, Peter D. Lax, and Barbara Keyfitz. “On finite‐difference approximations and entropy conditions for shocks.” Communications on pure and applied mathematics 29, no. 3 (1976): 297-322.
 exaggeration to say that getting funding for science has replaced the conduct and value of that science today. This is broadly true, and particularly true in scientific computing where getting something funded has replaced funding what is needed or wise. The truth of the benefit of pursuing computer power above all else is decided upon a priori. The belief was that this sort of program could “make it rain” and produce funding because this sort of marketing had in the past. All results in the
exaggeration to say that getting funding for science has replaced the conduct and value of that science today. This is broadly true, and particularly true in scientific computing where getting something funded has replaced funding what is needed or wise. The truth of the benefit of pursuing computer power above all else is decided upon a priori. The belief was that this sort of program could “make it rain” and produce funding because this sort of marketing had in the past. All results in the program must bow to this maxim, and support its premise. All evidence to the contrary is rejected because it is politically incorrect and threatens the attainment of the cargo, the funding, the money. A large part of this utterly rotten core of modern science is the ascendency of the science manager as the apex of the enterprise. The accomplished scientist and expert is merely now a useful and necessary detail, the manager reigns as the peak of achievement.
program must bow to this maxim, and support its premise. All evidence to the contrary is rejected because it is politically incorrect and threatens the attainment of the cargo, the funding, the money. A large part of this utterly rotten core of modern science is the ascendency of the science manager as the apex of the enterprise. The accomplished scientist and expert is merely now a useful and necessary detail, the manager reigns as the peak of achievement. In this putrid environment, faster computers seem an obvious benefit to science. They are a benefit and pathway to progress, this is utterly undeniable. Unfortunately, it is an expensive and inefficient path to progress, and an incredibly bad investment in comparison to alternative. The numerous problems with the exascale program are subtle, nuanced, highly technical and pathological. As I’ve pointed out before the modern age is no place for subtlety or nuance, we live it an age of brutish simplicity where bullshit reigns and facts are optional. In such an age, exascale is an exemplar, it is a brutally simple approach tailor made for the ignorant and witless. If one is willing to cast away the cloak of ignorance and embrace subtlety and nuance, a host of investments can be described that would benefit scientific computing vastly more than the current program. If we followed a better balance of research, computing to contribute to science far more greatly and scale far greater heights than the current path provides.
In this putrid environment, faster computers seem an obvious benefit to science. They are a benefit and pathway to progress, this is utterly undeniable. Unfortunately, it is an expensive and inefficient path to progress, and an incredibly bad investment in comparison to alternative. The numerous problems with the exascale program are subtle, nuanced, highly technical and pathological. As I’ve pointed out before the modern age is no place for subtlety or nuance, we live it an age of brutish simplicity where bullshit reigns and facts are optional. In such an age, exascale is an exemplar, it is a brutally simple approach tailor made for the ignorant and witless. If one is willing to cast away the cloak of ignorance and embrace subtlety and nuance, a host of investments can be described that would benefit scientific computing vastly more than the current program. If we followed a better balance of research, computing to contribute to science far more greatly and scale far greater heights than the current path provides. Today supercomputing is completely at odds with the commercial industry. After decades of first pacing advances in computing hardware, then riding along with increases in computing power, supercomputing has become separate. The separation occurred when Moore’s law died at the chip level (in about 2007). The supercomputing world has become increasingly disparate to continue the free lunch, and tied to an outdated model for delivering results. Basically, supercomputing is still tied to the mainframe model of computing that died in the business World long ago. Supercomputing has failed to embrace modern computing with its pervasive and multiscale nature moving all the way from mobile to cloud.
Today supercomputing is completely at odds with the commercial industry. After decades of first pacing advances in computing hardware, then riding along with increases in computing power, supercomputing has become separate. The separation occurred when Moore’s law died at the chip level (in about 2007). The supercomputing world has become increasingly disparate to continue the free lunch, and tied to an outdated model for delivering results. Basically, supercomputing is still tied to the mainframe model of computing that died in the business World long ago. Supercomputing has failed to embrace modern computing with its pervasive and multiscale nature moving all the way from mobile to cloud.  Expansive uncertainty quantification – too many uncertainties are ignored rather than considered and addressed. Uncertainty is a big part V&V, a genuinely hot topic in computational circles, and practiced quite incompletely. Many view uncertainty quantification as only being a small set of activities that only address a small piece of the uncertainty question. Too much benefit is achieved by simply ignoring a real uncertainty because the value of zero that is implicitly assumed is not challenged. This is exacerbated significantly by a half funded and deemphasized V&V effort in scientific computing. Significant progress was made several decades ago, but the signs now point to regression. The result of this often willful ignorance is a lessening of impact of computing and limiting the true benefits.
Expansive uncertainty quantification – too many uncertainties are ignored rather than considered and addressed. Uncertainty is a big part V&V, a genuinely hot topic in computational circles, and practiced quite incompletely. Many view uncertainty quantification as only being a small set of activities that only address a small piece of the uncertainty question. Too much benefit is achieved by simply ignoring a real uncertainty because the value of zero that is implicitly assumed is not challenged. This is exacerbated significantly by a half funded and deemphasized V&V effort in scientific computing. Significant progress was made several decades ago, but the signs now point to regression. The result of this often willful ignorance is a lessening of impact of computing and limiting the true benefits.  progress are the computer codes. Old computer codes are still being used, and most of them use operator splitting. Back in the 1990’s a big deal was made regarding replacing legacy codes with new codes. The codes developed then are still in use, and no one is replacing them. The methods in these old codes are still being used and now we are told that the codes need to be preserved. The codes, the models, the methods and the algorithms all come along for the ride. We end up having no practical route to advancing the methods.
progress are the computer codes. Old computer codes are still being used, and most of them use operator splitting. Back in the 1990’s a big deal was made regarding replacing legacy codes with new codes. The codes developed then are still in use, and no one is replacing them. The methods in these old codes are still being used and now we are told that the codes need to be preserved. The codes, the models, the methods and the algorithms all come along for the ride. We end up having no practical route to advancing the methods.  Complete code refresh – we have produced and now we are maintaining a new generation of legacy codes. A code is a storage for vast stores of knowledge in modeling, numerical methods, algorithms, computer science and problem solving. When we fail to replace codes, we fail to replace knowledge. The knowledge comes directly from those who write the code and create the ability to solve useful problems with that code. Much of the methodology for problem solving is complex and problem specific. Ultimately a useful code becomes something that many people are deeply invested in. In addition, the people who originally write the code move on taking their expertise, history and knowledge with them. The code becomes an artifact for this knowledge, but it is also a deeply imperfect reflection of the knowledge. The code usually contains some techniques that are magical, and unexplained. These magic bits of code are often essential for success. If they get changed the code ceases to be useful. The result of this process is a deep loss of expertise and knowledge that arises from the process of creating a code that can solve real problems. If a legacy code continues to be used it also acts to block progress of all the things it contains starting with the model and its fundamental assumption. As a result, progress stops because even when there is research advances, it has no practical outlet. This is where we are today.
Complete code refresh – we have produced and now we are maintaining a new generation of legacy codes. A code is a storage for vast stores of knowledge in modeling, numerical methods, algorithms, computer science and problem solving. When we fail to replace codes, we fail to replace knowledge. The knowledge comes directly from those who write the code and create the ability to solve useful problems with that code. Much of the methodology for problem solving is complex and problem specific. Ultimately a useful code becomes something that many people are deeply invested in. In addition, the people who originally write the code move on taking their expertise, history and knowledge with them. The code becomes an artifact for this knowledge, but it is also a deeply imperfect reflection of the knowledge. The code usually contains some techniques that are magical, and unexplained. These magic bits of code are often essential for success. If they get changed the code ceases to be useful. The result of this process is a deep loss of expertise and knowledge that arises from the process of creating a code that can solve real problems. If a legacy code continues to be used it also acts to block progress of all the things it contains starting with the model and its fundamental assumption. As a result, progress stops because even when there is research advances, it has no practical outlet. This is where we are today.  Democratization of expertise – the manner in which codes are applied has a very large impact on solutions. The overall process is often called a workflow, encapsulating activities starting with problem conception, meshing, modeling choices, code input, code execution, data analysis, visualization. One of the problems that has arisen is the use of codes by non-experts. Increasingly code users are simply not sophisticated and treat codes like black boxes. Many refer to this as the democratization of the simulation capability, which is generally beneficial. On the other hand, we increasingly see calculations conducted by novices who are generally ignorant of vast swaths of the underlying science. This characteristic is keenly related to a lack of V&V focus and loose standards of acceptance for calculations. Calibration is becoming more prevalent again, and distinctions between calibration and validation are vanishing anew. The creation of broadly available simulation tools must be coupled to first rate practices and appropriate professional education. In both of these veins the current trends are completely in the wrong direction. V&V practices are in decline and recession. Professional education is systematically getting worse as the educational mission of universities is attacked, and diminished along with the role of elites in society.
Democratization of expertise – the manner in which codes are applied has a very large impact on solutions. The overall process is often called a workflow, encapsulating activities starting with problem conception, meshing, modeling choices, code input, code execution, data analysis, visualization. One of the problems that has arisen is the use of codes by non-experts. Increasingly code users are simply not sophisticated and treat codes like black boxes. Many refer to this as the democratization of the simulation capability, which is generally beneficial. On the other hand, we increasingly see calculations conducted by novices who are generally ignorant of vast swaths of the underlying science. This characteristic is keenly related to a lack of V&V focus and loose standards of acceptance for calculations. Calibration is becoming more prevalent again, and distinctions between calibration and validation are vanishing anew. The creation of broadly available simulation tools must be coupled to first rate practices and appropriate professional education. In both of these veins the current trends are completely in the wrong direction. V&V practices are in decline and recession. Professional education is systematically getting worse as the educational mission of universities is attacked, and diminished along with the role of elites in society. 
 Last week I tried to envision a better path forward for scientific computing. Unfortunately, a true better path flows invariably through a better path for science itself and the Nation as a whole. Ultimately scientific computing, and science more broadly is dependent on the health of society in the broadest sense. It also depends on leadership and courage, two other attributes we are lacking in almost every respect. Our society is not well, the problems we are confronting are deep and perhaps the most serious crisis since the Civil War. I believe that historians will look back to 2016-2018 and perhaps longer as the darkest period in American history since the Civil War. We can’t build anything great when the Nation is tearing itself apart. I hope and pray that it will be resolved before we plunge deeper into the abyss we find ourselves. We see the forces opposed to knowledge, progress and reason emboldened and running amok. The Nation is presently moving backward and embracing a deeply disturbing and abhorrent philosophy. In such an environment science cannot flourish, it can only survive. We all hope the darkness will lift and we can again move forward toward a better future; one with purpose and meaning where science can be a force for the betterment of society as a whole.
Last week I tried to envision a better path forward for scientific computing. Unfortunately, a true better path flows invariably through a better path for science itself and the Nation as a whole. Ultimately scientific computing, and science more broadly is dependent on the health of society in the broadest sense. It also depends on leadership and courage, two other attributes we are lacking in almost every respect. Our society is not well, the problems we are confronting are deep and perhaps the most serious crisis since the Civil War. I believe that historians will look back to 2016-2018 and perhaps longer as the darkest period in American history since the Civil War. We can’t build anything great when the Nation is tearing itself apart. I hope and pray that it will be resolved before we plunge deeper into the abyss we find ourselves. We see the forces opposed to knowledge, progress and reason emboldened and running amok. The Nation is presently moving backward and embracing a deeply disturbing and abhorrent philosophy. In such an environment science cannot flourish, it can only survive. We all hope the darkness will lift and we can again move forward toward a better future; one with purpose and meaning where science can be a force for the betterment of society as a whole. It would really be great to be starting 2018 feeling good about the work I do. Useful work that impacts important things would go a long way toward achieving this. I’ve put some thought into considering what might constitute work having these properties. This has two parts, what work would be useful and impactful in general, and what would be important to contribute to. As a necessary subtext to this conversation is a conclusion that most of the work we are doing in scientific computing today is neither useful, nor impactful and nothing important is at stake. This alone is a rather bold assertion. Simply put, as a Nation and society we are not doing anything aspirational, nothing big. This shows up in the lack of substance in the work we are paid to pursue. More deeply, I believe that if we did something big and aspirational, the utility and impact of our work would simply sort itself out as part of a natural order.
It would really be great to be starting 2018 feeling good about the work I do. Useful work that impacts important things would go a long way toward achieving this. I’ve put some thought into considering what might constitute work having these properties. This has two parts, what work would be useful and impactful in general, and what would be important to contribute to. As a necessary subtext to this conversation is a conclusion that most of the work we are doing in scientific computing today is neither useful, nor impactful and nothing important is at stake. This alone is a rather bold assertion. Simply put, as a Nation and society we are not doing anything aspirational, nothing big. This shows up in the lack of substance in the work we are paid to pursue. More deeply, I believe that if we did something big and aspirational, the utility and impact of our work would simply sort itself out as part of a natural order. The march of science is the 20th Century was deeply impacted by international events, several World Wars and a Cold (non) War that spurred National interests in supporting science and technology. The twin projects of the atom bomb and the nuclear arms race along with space exploration drove the creation of much of the science and technology today. These conflicts steeled resolve, purpose and granted resources needed for success. They were important enough that efforts were earnest. Risks were taken because risk is necessary for achievement. Today we don’t take risks because nothing important is a stake. We can basically fake results and market progress where little or none exists. Since nothing is really that essential bullshit reigns supreme.
The march of science is the 20th Century was deeply impacted by international events, several World Wars and a Cold (non) War that spurred National interests in supporting science and technology. The twin projects of the atom bomb and the nuclear arms race along with space exploration drove the creation of much of the science and technology today. These conflicts steeled resolve, purpose and granted resources needed for success. They were important enough that efforts were earnest. Risks were taken because risk is necessary for achievement. Today we don’t take risks because nothing important is a stake. We can basically fake results and market progress where little or none exists. Since nothing is really that essential bullshit reigns supreme. resistance was not real. Ironically the Soviets were ultimately defeated by bullshit. The Strategic Defense Initiative, or Star Wars bankrupted the Soviets. It was complete bullshit and never had a chance to succeed. This was a brutal harbinger of today’s World where reality is optional, and marketing is the coin of the realm. Today American power seems unassailable. This is partially true and partially over-confidence. We are not on our game at all, and far to much of our power is based on bullshit. As a result, we can basically just pretend to try, and actually not execute anything with substance and competence. This is where we are today; we are doing nothing important, and wasting lots of time and money in the process.
resistance was not real. Ironically the Soviets were ultimately defeated by bullshit. The Strategic Defense Initiative, or Star Wars bankrupted the Soviets. It was complete bullshit and never had a chance to succeed. This was a brutal harbinger of today’s World where reality is optional, and marketing is the coin of the realm. Today American power seems unassailable. This is partially true and partially over-confidence. We are not on our game at all, and far to much of our power is based on bullshit. As a result, we can basically just pretend to try, and actually not execute anything with substance and competence. This is where we are today; we are doing nothing important, and wasting lots of time and money in the process. The result of the current model is a research establishment that only goes through the motions and does little or nothing. We make lots of noise and produce little substance. Our nation deeply needs a purpose that is greater. There are plenty of worthier National goals. If war-making is needed, Russia and China are still worthy adversaries. For some reason, we have chosen to capitulate to Putin’s Russia simply because they are an ally against the non-viable threat of Islamic fundamentalism. This is a completely insane choice that is only rhetorically useful. If we want peaceful goals, there are challenges aplenty. Climate change and weather are worthy problems to tackle requiring both scientific understanding and societal transformation to conquer. Creating clean and renewable energy that does not create horrible environmental side-effects remains unsolved. Solving the international needs for food and prosperity for mankind is always there. Scientific exploration and particularly space remain unconquered frontiers. Medicine and genetics offer new vistas for scientific exploration. All of these areas could transform the Nation in broad ways socially and economically. All of these could meet broad societal needs. More to the point of my post, all need scientific computing in one form or another to fully succeed. Computing always works best as a useful tool employed to help achieve objectives in the real World. The real-World problems provide constraints and objectives that spur innovation and keep the enterprise honest.
The result of the current model is a research establishment that only goes through the motions and does little or nothing. We make lots of noise and produce little substance. Our nation deeply needs a purpose that is greater. There are plenty of worthier National goals. If war-making is needed, Russia and China are still worthy adversaries. For some reason, we have chosen to capitulate to Putin’s Russia simply because they are an ally against the non-viable threat of Islamic fundamentalism. This is a completely insane choice that is only rhetorically useful. If we want peaceful goals, there are challenges aplenty. Climate change and weather are worthy problems to tackle requiring both scientific understanding and societal transformation to conquer. Creating clean and renewable energy that does not create horrible environmental side-effects remains unsolved. Solving the international needs for food and prosperity for mankind is always there. Scientific exploration and particularly space remain unconquered frontiers. Medicine and genetics offer new vistas for scientific exploration. All of these areas could transform the Nation in broad ways socially and economically. All of these could meet broad societal needs. More to the point of my post, all need scientific computing in one form or another to fully succeed. Computing always works best as a useful tool employed to help achieve objectives in the real World. The real-World problems provide constraints and objectives that spur innovation and keep the enterprise honest. Instead our scientific computing is being applied as a shallow marketing ploy to shore up a vacuous program. Nothing really important or impactful is at stake. The applications for computing are mostly make believe and amount to nothing of significance. The marketing will tell you otherwise, but the lack of gravity for the work is clear and poisons the work. The result of this lack of gravity are phony goals and objectives that have the look and feel of impact, but contribute nothing toward an objective reality. This lack of contribution comes from the deeper malaise of purpose as a Nation, and science’s role as an engine of progress. With little or nothing at stake the tools used for success suffer, scientific computing is no different. The standards of success simply are not real, and lack teeth. Even stockpile stewardship is drifting into the realm of bullshit. It started as a worthy program, but over time it has been allowed to lose its substance. Political and financial goals have replaced science and fact, the goals of the program losing connection to objective reality.
Instead our scientific computing is being applied as a shallow marketing ploy to shore up a vacuous program. Nothing really important or impactful is at stake. The applications for computing are mostly make believe and amount to nothing of significance. The marketing will tell you otherwise, but the lack of gravity for the work is clear and poisons the work. The result of this lack of gravity are phony goals and objectives that have the look and feel of impact, but contribute nothing toward an objective reality. This lack of contribution comes from the deeper malaise of purpose as a Nation, and science’s role as an engine of progress. With little or nothing at stake the tools used for success suffer, scientific computing is no different. The standards of success simply are not real, and lack teeth. Even stockpile stewardship is drifting into the realm of bullshit. It started as a worthy program, but over time it has been allowed to lose its substance. Political and financial goals have replaced science and fact, the goals of the program losing connection to objective reality. We would still be chasing faster computers, but the faster computers would not be the primary focus. We would focus on using computing to solve problems that were important. We would focus on making computers that were useful first and foremost. We would want computers that were faster as long as they enabled progress on problem solving. As a result, efforts would be streamlined toward utility. We would not throw vast amounts of effort into making computers faster, just to make them faster (this is what is happening today there is no rhyme or reason to exascale other than, faster is like better, Duh!). Utility means that we would honestly look at what is limiting problem solving and putting our efforts into removing those limits. The effects of this dose of reality on our current efforts would be stunning; we would see a wholesale change in our emphasis and focus away from hardware. Computing hardware would take its proper role as an important tool for scientific computing and no longer be the driving force. The fact that hardware is a driving force for scientific computing is one of clearest indicators of how unhealthy the field is today.
We would still be chasing faster computers, but the faster computers would not be the primary focus. We would focus on using computing to solve problems that were important. We would focus on making computers that were useful first and foremost. We would want computers that were faster as long as they enabled progress on problem solving. As a result, efforts would be streamlined toward utility. We would not throw vast amounts of effort into making computers faster, just to make them faster (this is what is happening today there is no rhyme or reason to exascale other than, faster is like better, Duh!). Utility means that we would honestly look at what is limiting problem solving and putting our efforts into removing those limits. The effects of this dose of reality on our current efforts would be stunning; we would see a wholesale change in our emphasis and focus away from hardware. Computing hardware would take its proper role as an important tool for scientific computing and no longer be the driving force. The fact that hardware is a driving force for scientific computing is one of clearest indicators of how unhealthy the field is today. Current computing focus is only porting old codes to new computers, a process that keeps old models, methods and algorithms in place. This is one of the most corrosive elements in the current mix. The porting of old codes is the utter abdication of intellectual ownership. These old codes are scientific dinosaurs and act to freeze antiquated models, methods and algorithms in place while acting to squash progress. Worse yet, the skillsets necessary for improving the most valuable and important parts of modeling and simulation are allowed to languish. This is worse than simply choosing a less efficient road, this is going backwards. When we need to turn our attention to serious real work, our scientists will not be ready. These choices are dooming an entire generation that could have been making breakthroughs to simply become caretakers. To be proper stewards of our science we need to write new codes containing new models using new methods and algorithms. Porting codes turns our scientists into mindless monks simply transcribing sacred texts without any depth of understanding. It is a recipe for transforming our science into magic. It is the recipe for defeat and the passage away from the greatness we once had.
Current computing focus is only porting old codes to new computers, a process that keeps old models, methods and algorithms in place. This is one of the most corrosive elements in the current mix. The porting of old codes is the utter abdication of intellectual ownership. These old codes are scientific dinosaurs and act to freeze antiquated models, methods and algorithms in place while acting to squash progress. Worse yet, the skillsets necessary for improving the most valuable and important parts of modeling and simulation are allowed to languish. This is worse than simply choosing a less efficient road, this is going backwards. When we need to turn our attention to serious real work, our scientists will not be ready. These choices are dooming an entire generation that could have been making breakthroughs to simply become caretakers. To be proper stewards of our science we need to write new codes containing new models using new methods and algorithms. Porting codes turns our scientists into mindless monks simply transcribing sacred texts without any depth of understanding. It is a recipe for transforming our science into magic. It is the recipe for defeat and the passage away from the greatness we once had. My work day is full of useless bullshit. There is so much bullshit that it has choked out the room for inspiration and value. We are not so much managed as controlled. This control comes from a fundamental distrust of each other to a degree that any independent ideas are viewed as dangerous. This realization has come upon me in the past few years. It has also occurred to me that this could simply be a mid-life crisis manifesting itself, but the evidence might seem to indicate that it is something more significant (look at the bigger picture of the constant crisis my Nation is in). My mid-life attitudes are simply much less tolerant of time-wasting activities with little or no redeeming value. You realize that your time and energy is limited, why waste it on useless things.
My work day is full of useless bullshit. There is so much bullshit that it has choked out the room for inspiration and value. We are not so much managed as controlled. This control comes from a fundamental distrust of each other to a degree that any independent ideas are viewed as dangerous. This realization has come upon me in the past few years. It has also occurred to me that this could simply be a mid-life crisis manifesting itself, but the evidence might seem to indicate that it is something more significant (look at the bigger picture of the constant crisis my Nation is in). My mid-life attitudes are simply much less tolerant of time-wasting activities with little or no redeeming value. You realize that your time and energy is limited, why waste it on useless things. I read a book that had a big impact on my thinking, “The Subtle Art of Not Giving a Fuck” by Mark Manson . In a nutshell, the book says that you have a finite number of fucks to give in life and you should optimize your life by mindfully not giving a fuck about unimportant things. This gives you the time and energy to actually give a fuck about things that actually matter. The book isn’t about not caring, it is about caring about the right things and dismissing the wrong things. What I realized is that increasingly my work isn’t competing for my fucks, they just assume that I will spend my limited fucks on complete bullshit out of duty. It is actually extremely disrespectful of me and my limited time and effort. One conclusion is that the “bosses” (the Lab, the Department of Energy) not give enough of a fuck about me to treat my limited time and energy with respect and make sure my fucks actually matter.
I read a book that had a big impact on my thinking, “The Subtle Art of Not Giving a Fuck” by Mark Manson . In a nutshell, the book says that you have a finite number of fucks to give in life and you should optimize your life by mindfully not giving a fuck about unimportant things. This gives you the time and energy to actually give a fuck about things that actually matter. The book isn’t about not caring, it is about caring about the right things and dismissing the wrong things. What I realized is that increasingly my work isn’t competing for my fucks, they just assume that I will spend my limited fucks on complete bullshit out of duty. It is actually extremely disrespectful of me and my limited time and effort. One conclusion is that the “bosses” (the Lab, the Department of Energy) not give enough of a fuck about me to treat my limited time and energy with respect and make sure my fucks actually matter.








 If we look at work, it might seem that an inspired workforce would be a benefit worth creating. People would work hard and create wonderful things because of the depth of their commitment to a deeper purpose. An employer would benefit mightily from such an environment, and the employees could flourish brimming with satisfaction and growth. With all these benefits, we should expect the workplace to naturally create the conditions for inspiration. Yet this is not happening; the conditions are the complete opposite. The reason is that inspired employees are not entirely controlled. Creative people do things that are unexpected and unplanned. The job of managing a work place like this is much harder. In addition, mistakes and bad things happen too. Failure and mistakes are an inevitable consequence of hard working inspired people. This is the thing that our work places cannot tolerate. The lack of control and unintended consequences are unacceptable. Fundamentally this stems from a complete lack of trust. Our employers do not trust their employees at all. In turn, the employees do not trust the workplace. It is vicious cycles that drags inspiration under and smothers it. The entire environment is overflowing with micromanagement, control suspicion and doubt.
If we look at work, it might seem that an inspired workforce would be a benefit worth creating. People would work hard and create wonderful things because of the depth of their commitment to a deeper purpose. An employer would benefit mightily from such an environment, and the employees could flourish brimming with satisfaction and growth. With all these benefits, we should expect the workplace to naturally create the conditions for inspiration. Yet this is not happening; the conditions are the complete opposite. The reason is that inspired employees are not entirely controlled. Creative people do things that are unexpected and unplanned. The job of managing a work place like this is much harder. In addition, mistakes and bad things happen too. Failure and mistakes are an inevitable consequence of hard working inspired people. This is the thing that our work places cannot tolerate. The lack of control and unintended consequences are unacceptable. Fundamentally this stems from a complete lack of trust. Our employers do not trust their employees at all. In turn, the employees do not trust the workplace. It is vicious cycles that drags inspiration under and smothers it. The entire environment is overflowing with micromanagement, control suspicion and doubt. If we can’t say NO to all this useless stuff, we can’t say YES to things either. My work and time budget is completely stocked up with non-optional things that I should say NO to. They are largely useless and produce no value. Because I can’t say NO, I can’t say YES to something better. My employer is sending a message to me with very clear emphasis, we don’t trust you to make decisions. Your ideas are not worth working on. You are expected to implement other people’s ideas no matter how bad they are. You have no ability to steer the ideas to be better. Your expertise has absolutely no value. A huge part of this problem is the ascendency of the management class as the core of organizational value. We are living in the era of the manager; the employee is a cog and not valued. Organizations voice platitudes toward the employees, but they are hollow. The actions of the organization spell out their true intent. Employees are not to be trusted, they are to be controlled and they need to do what they are told to do. Inspired employees would do things that are not intended, and take organizations in new directions, focused on new things. This would mean losing control and changing plans. More importantly, the value of the organization would move away from the managers and move to the employees. Managers are much happier with employees that are “seen and not heard”.
If we can’t say NO to all this useless stuff, we can’t say YES to things either. My work and time budget is completely stocked up with non-optional things that I should say NO to. They are largely useless and produce no value. Because I can’t say NO, I can’t say YES to something better. My employer is sending a message to me with very clear emphasis, we don’t trust you to make decisions. Your ideas are not worth working on. You are expected to implement other people’s ideas no matter how bad they are. You have no ability to steer the ideas to be better. Your expertise has absolutely no value. A huge part of this problem is the ascendency of the management class as the core of organizational value. We are living in the era of the manager; the employee is a cog and not valued. Organizations voice platitudes toward the employees, but they are hollow. The actions of the organization spell out their true intent. Employees are not to be trusted, they are to be controlled and they need to do what they are told to do. Inspired employees would do things that are not intended, and take organizations in new directions, focused on new things. This would mean losing control and changing plans. More importantly, the value of the organization would move away from the managers and move to the employees. Managers are much happier with employees that are “seen and not heard”. As Mark Manson writes we only have so many fucks to give and my work is doing precious little to give them there. I have always focused on personal growth and increasingly personal growth is resisted by work instead of resonated with. It has become quite obvious that being the best “me” is not remotely a priority. The priority at work is to be compliant, take no risks, fail at nothing and help produce marketing material for success and achievement. We aren’t doing great work anymore, but pretend we are. My work could simply be awesome, but that would require giving me the freedom to set priorities, take risks, fail often, learn continually and actually produce wonderful things. If this happened the results would speak for themselves and the marketing would take care of itself. When the Labs I’ve worked at were actually great this is how it actually happened. The Labs were great because they achieved great things. The labs said NO to a lot of things, so they could say YES to the right things. Today, we simply don’t have this freedom.
As Mark Manson writes we only have so many fucks to give and my work is doing precious little to give them there. I have always focused on personal growth and increasingly personal growth is resisted by work instead of resonated with. It has become quite obvious that being the best “me” is not remotely a priority. The priority at work is to be compliant, take no risks, fail at nothing and help produce marketing material for success and achievement. We aren’t doing great work anymore, but pretend we are. My work could simply be awesome, but that would require giving me the freedom to set priorities, take risks, fail often, learn continually and actually produce wonderful things. If this happened the results would speak for themselves and the marketing would take care of itself. When the Labs I’ve worked at were actually great this is how it actually happened. The Labs were great because they achieved great things. The labs said NO to a lot of things, so they could say YES to the right things. Today, we simply don’t have this freedom. If we could say NO to the bullshit, and give our limited fucks a powerful YES, we might be able to achieve great things. Our Labs could stop trying to convince everyone that they were doing great things and actually do great things. The missing element at work today is trust. If the trust was there we could produce inspiring work that would generate genuine pride and accomplishment. Computing is a wonderful example of these principles in action. Scientific computing became a force in science and engineering contributing to genuine endeavors for massive societal goals. Computing helped win the Cold War and put a man on the moon. Weather and climate has been modeled successfully. More broadly, computers have reshaped business and now societally massively. All of these endeavors had computing contributing to solutions. Computing focused on computers was not the endeavor itself like it is today. The modern computing emphasis was originally part of a bigger program of using science to support the nuclear stockpile without testing. It was part of a focused scientific enterprise and objective. Today it is a goal unto itself, and not moored to anything larger. If we want to progress and advance science, we should focus on great things for society, not superficially put our effort into mere tools.
If we could say NO to the bullshit, and give our limited fucks a powerful YES, we might be able to achieve great things. Our Labs could stop trying to convince everyone that they were doing great things and actually do great things. The missing element at work today is trust. If the trust was there we could produce inspiring work that would generate genuine pride and accomplishment. Computing is a wonderful example of these principles in action. Scientific computing became a force in science and engineering contributing to genuine endeavors for massive societal goals. Computing helped win the Cold War and put a man on the moon. Weather and climate has been modeled successfully. More broadly, computers have reshaped business and now societally massively. All of these endeavors had computing contributing to solutions. Computing focused on computers was not the endeavor itself like it is today. The modern computing emphasis was originally part of a bigger program of using science to support the nuclear stockpile without testing. It was part of a focused scientific enterprise and objective. Today it is a goal unto itself, and not moored to anything larger. If we want to progress and advance science, we should focus on great things for society, not superficially put our effort into mere tools.







 In the conduct of predictive science, we should look to uncertainty as one of our primary outcomes. When V&V is conducted with high professional standards, uncertainty is unveiled and estimated in magnitude. With our highly over-promised mantra of predictive modeling enabled by high performance computing, uncertainty is almost always viewed negatively. This creates an environment where willful or casual ignorance of uncertainty is tolerated and even encouraged. Incomplete and haphazard V&V practice becomes accepted because it serves the narrative of predictive science. The truth and actual uncertainty is treated as bad news, and greeted with scorn instead of praise. It is simply so much easier to accept the comfort that the modeling has achieved a level of mastery. This comfort is usually offered without evidence.
In the conduct of predictive science, we should look to uncertainty as one of our primary outcomes. When V&V is conducted with high professional standards, uncertainty is unveiled and estimated in magnitude. With our highly over-promised mantra of predictive modeling enabled by high performance computing, uncertainty is almost always viewed negatively. This creates an environment where willful or casual ignorance of uncertainty is tolerated and even encouraged. Incomplete and haphazard V&V practice becomes accepted because it serves the narrative of predictive science. The truth and actual uncertainty is treated as bad news, and greeted with scorn instead of praise. It is simply so much easier to accept the comfort that the modeling has achieved a level of mastery. This comfort is usually offered without evidence. This last point gets at the problems with implementing a more professional V&V practice. If V&V finds that uncertainties are too large, the rational choice may be to not use modeling at all. This runs the risk of being politically incorrect. Programs are sold on predictive modeling, and the money might look like a waste! We might find that the uncertainties from numerical error are much smaller than other uncertainties, and the new super expensive, super-fast computer will not help make things any better. In other cases, we might find out that the model is not converging toward a (correct) solution. Again, the computer is not going to help. Actual V&V is likely to produce results that require changing programs and investments in reaction. Current management often looks to this as a negative and worries that the feedback will reflect poorly on previous investments. There is a deep-seated lack of trust between the source of the money and the work. The lack of trust is driving a lack of honesty in science. Any money spent on fruitless endeavors is viewed as a potential scandal. The money will simply be withdrawn instead of redirected more productively. No one trusts the scientific process to work effectively. The result is an unwillingness to engage in a frank and accurate dialog about how predictive we actually are.
This last point gets at the problems with implementing a more professional V&V practice. If V&V finds that uncertainties are too large, the rational choice may be to not use modeling at all. This runs the risk of being politically incorrect. Programs are sold on predictive modeling, and the money might look like a waste! We might find that the uncertainties from numerical error are much smaller than other uncertainties, and the new super expensive, super-fast computer will not help make things any better. In other cases, we might find out that the model is not converging toward a (correct) solution. Again, the computer is not going to help. Actual V&V is likely to produce results that require changing programs and investments in reaction. Current management often looks to this as a negative and worries that the feedback will reflect poorly on previous investments. There is a deep-seated lack of trust between the source of the money and the work. The lack of trust is driving a lack of honesty in science. Any money spent on fruitless endeavors is viewed as a potential scandal. The money will simply be withdrawn instead of redirected more productively. No one trusts the scientific process to work effectively. The result is an unwillingness to engage in a frank and accurate dialog about how predictive we actually are.
 Even worse than the irony is the price this approach is exacting on scientific computing. For example, the computing industry used to beat a path to scientific computing’s door, and now we have to basically bribe the industry to pay attention to us. A fair accounting of the role of government in computing is some combination of being a purely niche market, and partially pork barrel spending. Scientific computing used to be a driving force in the industry, and now lies as a cul-de-sac, or even pocket universe, divorced from the day-to-day reality of computing. Scientific computing is now a tiny and unimportant market to an industry that dominates the modern World. In the process, scientific computing has allowed itself to become disconnected from modernity, and hopelessly imbalanced. Rather than leverage the modern World and its technological wonders many of which are grounded in information science, it resists and fails to make best use of the opportunity. It robs scientific computing of impact in the broader World, and diminishes the draw of new talent to the field.
Even worse than the irony is the price this approach is exacting on scientific computing. For example, the computing industry used to beat a path to scientific computing’s door, and now we have to basically bribe the industry to pay attention to us. A fair accounting of the role of government in computing is some combination of being a purely niche market, and partially pork barrel spending. Scientific computing used to be a driving force in the industry, and now lies as a cul-de-sac, or even pocket universe, divorced from the day-to-day reality of computing. Scientific computing is now a tiny and unimportant market to an industry that dominates the modern World. In the process, scientific computing has allowed itself to become disconnected from modernity, and hopelessly imbalanced. Rather than leverage the modern World and its technological wonders many of which are grounded in information science, it resists and fails to make best use of the opportunity. It robs scientific computing of impact in the broader World, and diminishes the draw of new talent to the field. present imbalances. If one looks at the modern computing industry and its ascension to the top of the economic food chain, two things come to mind: mobile computing – cell phones – and the Internet. Mobile computing made connectivity and access ubiquitous with massive penetration into our lives. Networks and apps began to create new social connections in the real world and lubricated communications between people in a myriad of ways. The Internet became both a huge information repository, and commerce. but also an engine of social connection. In short order, the adoption and use of the internet and computing in the broader human World overtook and surpassed the use by scientists and business. Where once scientists used and knew computers better than anyone, now the World is full of people for whom computing is far more important than for science. Science once were in the lead, and now they are behind. Worse yet, science is not adapting to this new reality.
present imbalances. If one looks at the modern computing industry and its ascension to the top of the economic food chain, two things come to mind: mobile computing – cell phones – and the Internet. Mobile computing made connectivity and access ubiquitous with massive penetration into our lives. Networks and apps began to create new social connections in the real world and lubricated communications between people in a myriad of ways. The Internet became both a huge information repository, and commerce. but also an engine of social connection. In short order, the adoption and use of the internet and computing in the broader human World overtook and surpassed the use by scientists and business. Where once scientists used and knew computers better than anyone, now the World is full of people for whom computing is far more important than for science. Science once were in the lead, and now they are behind. Worse yet, science is not adapting to this new reality.









 that Google solved is firmly grounded in scientific computing and applied mathematics. It is easy to see how massive the impact of this solution is. Today we in scientific computing are getting further and further from relevance to society. This niche does scientific computing little good because it is swimming against a tide that is more like a tsunami. The result is a horribly expensive and marginally effective effort that will fail needlessly where it has the potential to provide phenomenal value.
that Google solved is firmly grounded in scientific computing and applied mathematics. It is easy to see how massive the impact of this solution is. Today we in scientific computing are getting further and further from relevance to society. This niche does scientific computing little good because it is swimming against a tide that is more like a tsunami. The result is a horribly expensive and marginally effective effort that will fail needlessly where it has the potential to provide phenomenal value.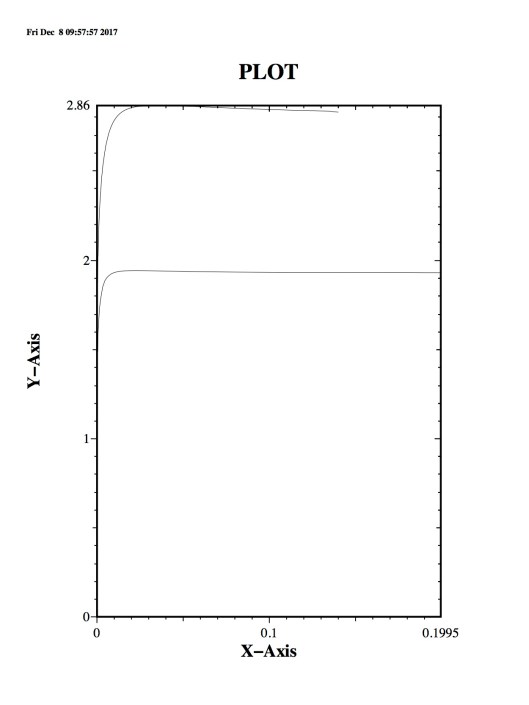
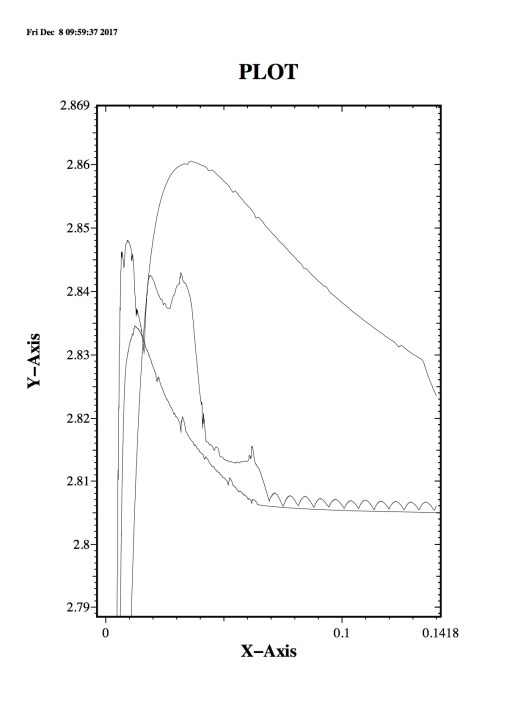
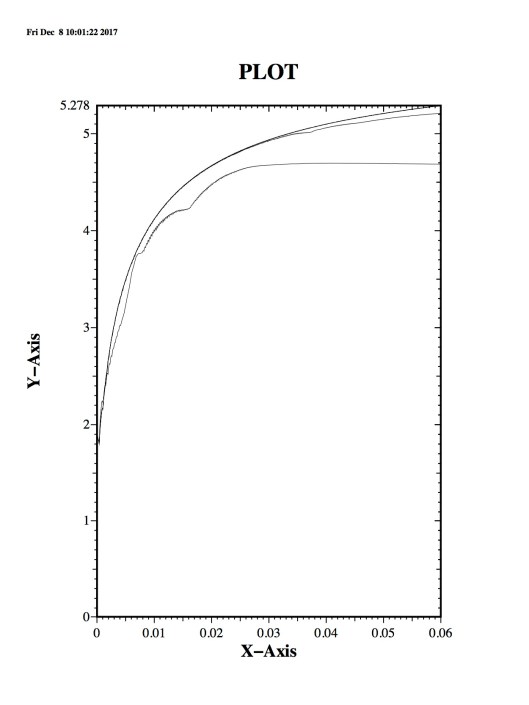
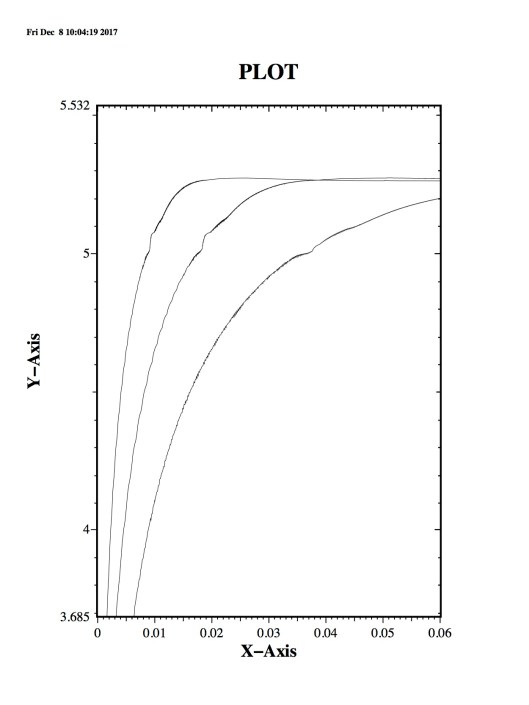
 Ideally, it should not be, but proving that ideal is a very high bar that is almost never met. A great deal of compelling evidence is needed to support an assertion that the code is not part of the model. The real difficulty is that the more complex the modeling problem is, the more the code is definitely and irreducibly part of the model. These complex models are the most important uses of modeling and simulation. The complex models of engineered things, or important physical systems have many submodels each essential to successful modeling. The code is often designed quite specifically to model a class of problems. The code then becomes are clear part of the definition of the problem. Even in the simplest cases, the code includes the recipe for the numerical solution of a model. This numerical solution leaves its fingerprints all over the solution of the model. The numerical solution is imperfect and contains errors that influence the solution. For a code, there is the mesh and geometric description plus boundary conditions, not to mention the various modeling options employed. Removing the specific details of the implementation of the model in the code from consideration as part of the model becomes increasingly intractable.
Ideally, it should not be, but proving that ideal is a very high bar that is almost never met. A great deal of compelling evidence is needed to support an assertion that the code is not part of the model. The real difficulty is that the more complex the modeling problem is, the more the code is definitely and irreducibly part of the model. These complex models are the most important uses of modeling and simulation. The complex models of engineered things, or important physical systems have many submodels each essential to successful modeling. The code is often designed quite specifically to model a class of problems. The code then becomes are clear part of the definition of the problem. Even in the simplest cases, the code includes the recipe for the numerical solution of a model. This numerical solution leaves its fingerprints all over the solution of the model. The numerical solution is imperfect and contains errors that influence the solution. For a code, there is the mesh and geometric description plus boundary conditions, not to mention the various modeling options employed. Removing the specific details of the implementation of the model in the code from consideration as part of the model becomes increasingly intractable. central to the conduct of science and engineering that it should be dealt with head on. It isn’t going away. We model our reality when we want to make sure we understand it. We engage in modeling when we have something in the Real World, we want to demonstrate an understand of. Sometimes this is for the purpose of understanding, but ultimately this gives way to manipulation, the essence of engineering. The Real World is complex and effective models are usually immune to analytical solution.
central to the conduct of science and engineering that it should be dealt with head on. It isn’t going away. We model our reality when we want to make sure we understand it. We engage in modeling when we have something in the Real World, we want to demonstrate an understand of. Sometimes this is for the purpose of understanding, but ultimately this gives way to manipulation, the essence of engineering. The Real World is complex and effective models are usually immune to analytical solution. are implemented in computer code, or “a computer code”. The details and correctness of the implementation become inseparable from the model itself. It becomes quite difficult to extract the model as any sort of pure mathematical construct; the code is part of it intimately.
are implemented in computer code, or “a computer code”. The details and correctness of the implementation become inseparable from the model itself. It becomes quite difficult to extract the model as any sort of pure mathematical construct; the code is part of it intimately. impact of numerical approximation. The numerical uncertainty needs to be accounted for to isolate the model. This uncertainty defines the level of approximation in the solution to the model, and a deviation from the mathematical idealization the model represents. In actual validation work, we see a stunning lack of this essential step from validation work presented. Another big part of the validation is recognizing the subtle differences between calibrated results and predictive simulation. Again, calibration is rarely elaborated in validation to the degree that it should.
impact of numerical approximation. The numerical uncertainty needs to be accounted for to isolate the model. This uncertainty defines the level of approximation in the solution to the model, and a deviation from the mathematical idealization the model represents. In actual validation work, we see a stunning lack of this essential step from validation work presented. Another big part of the validation is recognizing the subtle differences between calibrated results and predictive simulation. Again, calibration is rarely elaborated in validation to the degree that it should.



 strong function of the discretization and solver used in the code. The question of whether the code matters comes down to asking if another code used skillfully would produce a significantly different result. This is rarely, if ever, the case. To make matters worse, verification evidence tends to be flimsy and half-assed. Even if we could make this call and ignore the code, we rarely have evidence that this is a valid and defensible decision.
strong function of the discretization and solver used in the code. The question of whether the code matters comes down to asking if another code used skillfully would produce a significantly different result. This is rarely, if ever, the case. To make matters worse, verification evidence tends to be flimsy and half-assed. Even if we could make this call and ignore the code, we rarely have evidence that this is a valid and defensible decision. Another common thread to horribleness is the increasing tendency for science and engineering to be marketed. The press release has given way to the tweet, but the sentiment is the same. Science is marketed for the masses who have no taste for the details necessary for high quality work. A deep problem is that this lack of focus and detail is creeping back into science itself. Aspects of scientific and engineering work that used to be utterly essential are becoming increasingly optional. Much of this essential intellectual labor is associated with the hidden aspects of the investigation. Things related to mathematics, checking for correctness, assessment of error, preceding work, various doubts about results and alternative means of investigation. This sort of deep work has been crowded out by flashy graphics, movies and undisciplined demonstrations of vast computing power.
Another common thread to horribleness is the increasing tendency for science and engineering to be marketed. The press release has given way to the tweet, but the sentiment is the same. Science is marketed for the masses who have no taste for the details necessary for high quality work. A deep problem is that this lack of focus and detail is creeping back into science itself. Aspects of scientific and engineering work that used to be utterly essential are becoming increasingly optional. Much of this essential intellectual labor is associated with the hidden aspects of the investigation. Things related to mathematics, checking for correctness, assessment of error, preceding work, various doubts about results and alternative means of investigation. This sort of deep work has been crowded out by flashy graphics, movies and undisciplined demonstrations of vast computing power. ngineering. These terrible things would be awful with or without a computer being involved. Other things come from a lack of understanding of how to add computing to an investigation in a quality focused manner. The failure to recognize the multidisciplinary nature of computational science is often at the root of many of the awful things I will now describe.
ngineering. These terrible things would be awful with or without a computer being involved. Other things come from a lack of understanding of how to add computing to an investigation in a quality focused manner. The failure to recognize the multidisciplinary nature of computational science is often at the root of many of the awful things I will now describe. background work needed to create high quality results. A great deal of modeling is associated with bounding uncertainty or bounding the knowledge we possess. A single calculation is incapable of this sort of rigor and focus. If you see a single massive calculation as the sole evidence of work, you should smell and call “bullshit”. –
background work needed to create high quality results. A great deal of modeling is associated with bounding uncertainty or bounding the knowledge we possess. A single calculation is incapable of this sort of rigor and focus. If you see a single massive calculation as the sole evidence of work, you should smell and call “bullshit”. –  l error bars are an endangered species. We never see them in practice even though we know how to compute them. They should simply be a routine element of modern computing. They are almost never demanded by anyone, and their lack never precludes publication. It certainly never precludes a calculation being promoted as marketing for computing. If I was cynically minded, I might even day that error bars when used are opposed to marketing the calculation. The implicit message in the computing marketing is that the calculations are so accurate that they are basically exact, no error at all. If you don’t see error bars or some explicit discussion of uncertainty you should see the calculation as flawed, and potentially simply bullshit. –
l error bars are an endangered species. We never see them in practice even though we know how to compute them. They should simply be a routine element of modern computing. They are almost never demanded by anyone, and their lack never precludes publication. It certainly never precludes a calculation being promoted as marketing for computing. If I was cynically minded, I might even day that error bars when used are opposed to marketing the calculation. The implicit message in the computing marketing is that the calculations are so accurate that they are basically exact, no error at all. If you don’t see error bars or some explicit discussion of uncertainty you should see the calculation as flawed, and potentially simply bullshit. –  developments for solving hyperbolic PDEs in the 1980’s. For a long time this was one of the best methods available to solve the Euler equations. It still outperforms most of the methods in common use today. For astrophysics, it is the method of choice, and also made major inroads to the weather and climate modeling communities. In spite of having over 4000 citations, I can’t help but think that this paper wasn’t as influential as it could have been. This is saying a lot, but I think this is completely true. This partly due to its style, and relative difficulty as a read. In other words, the paper is not as pedagogically effective as it could have been. The most complex and difficult to understand version of the method is presented in the paper. The paper could have used a different approach to great effect by perhaps providing a simplified version to introduce the reader and deliver the more complex approach as a specific instance. Nonetheless, the paper was a massive milestone in the field.
developments for solving hyperbolic PDEs in the 1980’s. For a long time this was one of the best methods available to solve the Euler equations. It still outperforms most of the methods in common use today. For astrophysics, it is the method of choice, and also made major inroads to the weather and climate modeling communities. In spite of having over 4000 citations, I can’t help but think that this paper wasn’t as influential as it could have been. This is saying a lot, but I think this is completely true. This partly due to its style, and relative difficulty as a read. In other words, the paper is not as pedagogically effective as it could have been. The most complex and difficult to understand version of the method is presented in the paper. The paper could have used a different approach to great effect by perhaps providing a simplified version to introduce the reader and deliver the more complex approach as a specific instance. Nonetheless, the paper was a massive milestone in the field. Riemann solution. Advances that occurred later greatly simplified and clarified this presentation. This is a specific difficulty of being an early adopter of methods, the clarity of presentation and understanding is dimmed by purely narrative effects. Many of these shortcomings have been addressed in the recent literature discussed below.
Riemann solution. Advances that occurred later greatly simplified and clarified this presentation. This is a specific difficulty of being an early adopter of methods, the clarity of presentation and understanding is dimmed by purely narrative effects. Many of these shortcomings have been addressed in the recent literature discussed below.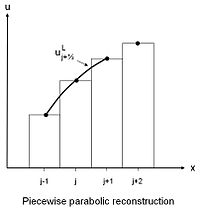
 elaborate ways of producing dissipation while achieving high quality. For very nonlinear problems this is not enough. The paper describes several ways of adding a little bit more, one of these is the shock flattening, and another is an artificial viscosity. Rather than use the classical Von Neumann-Richtmyer approach (that really is more like the Riemann solver), they add a small amount of viscosity using a technique developed by Lapidus appropriate for conservation form solvers. There are other techniques such as grid-jiggling that only really work with PPMLR and may not have any broader utility. Nonetheless, there may be aspects of the thought process that may be useful.
elaborate ways of producing dissipation while achieving high quality. For very nonlinear problems this is not enough. The paper describes several ways of adding a little bit more, one of these is the shock flattening, and another is an artificial viscosity. Rather than use the classical Von Neumann-Richtmyer approach (that really is more like the Riemann solver), they add a small amount of viscosity using a technique developed by Lapidus appropriate for conservation form solvers. There are other techniques such as grid-jiggling that only really work with PPMLR and may not have any broader utility. Nonetheless, there may be aspects of the thought process that may be useful. Riemann solvers with clarity and refinement hadn’t been developed by 1984. Nevertheless, the monolithic implementation of PPM has been a workhorse method for computational science. Through Paul Woodward’s efforts it is often the first real method to be applied to brand new supercomputers, and generates the first scientific results of note on them.
Riemann solvers with clarity and refinement hadn’t been developed by 1984. Nevertheless, the monolithic implementation of PPM has been a workhorse method for computational science. Through Paul Woodward’s efforts it is often the first real method to be applied to brand new supercomputers, and generates the first scientific results of note on them.





