“The real purpose of the scientific method is to make sure nature hasn’t misled you into thinking you know something you actually don’t know.” ― Robert M. Pirsig
My thoughts on how machine learning (ML) fits into science are shaped by the question of how simulation fits into science. In the past, I have made my views on that clear. Modeling and simulation does not change science in any fundamental way. It is just a tool to do science better. ML or AI are the same. Useful tools for better science, but science is unchanged.
The scientific method remains solid. This is a core message: science is unchanged. You just have new tools to conduct it. These new tools offer new, potentially better ways to do the same work. They offer new avenues for engaging and improving parts of it. You still have theory and observation as the base of science. Now one has more effective and more broadly applicable computational tools to navigate that space. These new tools can apply to vast datasets produced by observations or simulations. They offer new perspectives or uses of data that could improve science.
As I have said before, the key to navigating this properly is the habits and practices of verification and validation. I have argued that verification and validation are the scientific method structured for modeling and simulation. For ML and AI the same maxims apply here. For ML and AI, the details need to be sorted out differently. These techniques carry a different set of key technical practices and issues, and V&V should be adjusted accordingly. Most notably the role of theory and mathematics is fundamentally different. The math for ML-AI is vastly different and less rigorous than modeling and simulation. That is the topic I will take up in the following post in an expanded form.
A good starting point is the subject of my last post: Direct Numerical Simulation (DNS). DNS is often promoted as the gold standard of modeling and simulation. It is supposedly so good that it can replace experimental data, which would be amazing if we could actually do it. Current practice is not up to this end. The same issue is doubly true for ML-AI. Without a great deal of improvement and better quality these won’t be silver bullets.
The history of science, like the history of all human ideas, is a history of irresponsible dreams, of obstinacy, and of error. But science is one of the very few human activities — perhaps the only one — in which errors are systematically criticized and fairly often, in time, corrected. This is why we can say that, in science, we often learn from our mistakes, and why we can speak clearly and sensibly about making progress there.” ― Karl R. Popper
That means DNS should face a very high bar for success. As I wrote, the work usually does not clear that bar. A big part of clearing the bar is entering into the sudy with doubt and uncertainty. There is typically very little analysis of whether the model equations are appropriate. Next, on whether the simulations are numerically accurate. Error analysis is at the heart of science, and that heart is largely neglected in DNS practice. ML and AI are the next fields to commit these same sins. Science is largely the study of error. Without it, the claims of science are weak.
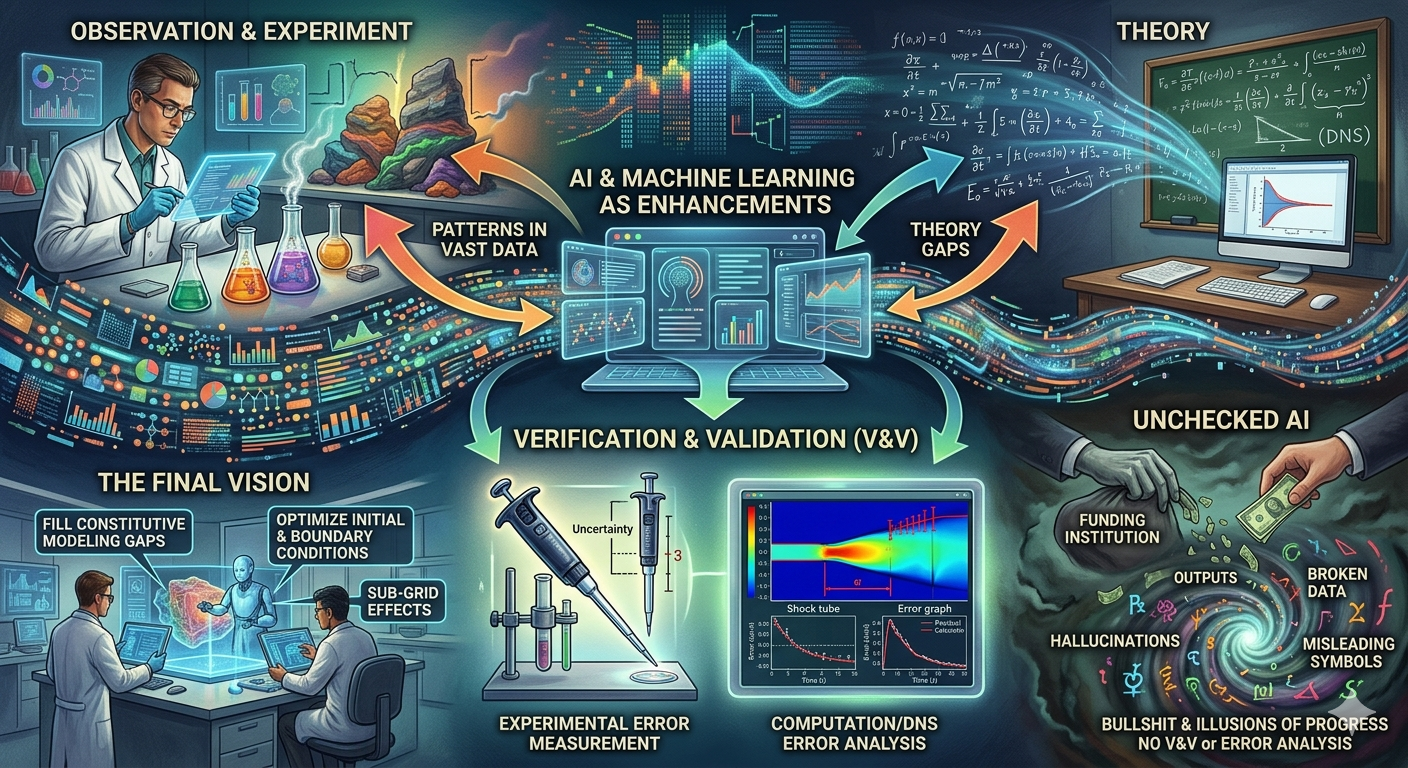
One key question about these new tools is whether they replace parts of science that already work. Experimental and observational science remain essential to everything. They connect to objective reality. This should remain central to everything. The theory of physics, and the use of mathematics to model it, is another area where science works well. We should recognize the shortcomings in both and shore them up with new techniques. Nothing points to discarding either. As a new numerical method, or instrument improves science, AI and ML can be the same. A better tool for engaging with the same science.
AI and machine learning rely on data, which can come from observations, experiments, or simulations. it is often available in vast quantities. More with each passing year. The lack of any characterization of error and uncertainty in these data sources is one of my most consistent complaints about current practice. In almost every example I have seen, error and uncertainty are ignored rather than treated as part of training or of using these tools for science. This should be completely unacceptable, yet I see little progress toward addressing the flaw. Moreover, we should know whether the processing or use of the data expands or contracts the errors.
“Essentially, all models are wrong, but some are useful.” – George Box
One thing that is consistently missing is a commitment to evidence. This holds even for experimental data. Error is often absent or buried from the view of the consumer. This is odd as error estimation in measurement or phenomenology is well defined and expected. The standard is simply not exercised. In computation, the practice is much worse. I pointed this out for DNS, but the same is true across the field. When this happens the implicit effect is to substitute a value of zero for a true analysis. Notably, the lack of analysis and disclosure means the smallest value is used. This is intrinsically dangerous.
One area where I focus a lot of energy is the quality of shock tube solutions. These solutions are exact and come with a precise error estimate. Yet the accepted practice across the community is to not display those errors. We are offered purely qualitative results. There is little reflection on this. It is simply what I call “Hello World” for the field. It is really a quiet sad state of affairs. The result is an unconscious stagnation, where we show qualitative results, give a thumbs up or thumbs down, and move on. No evidence is provided about the error or efficiency of the methods. It is common in other parts of computational science. We see the same trend in machine learning and AI.
“Science, my boy, is made up of mistakes, but they are mistakes which it is useful to make, because they lead little by little to the truth.” ― Jules Verne
Over my career, I watched the rise of V&V, driven by the promise of doing high-consequence work with the quality and evidence that supported its use. This spirit rose and fell in less than a decade. After that, I saw roughly a 20-year pullback, as the evidence was deemed too expensive, too difficult, and insufficiently positive to power the marketing our programs needed. Evidence and doubt are essential for science. They are anathema to marketing. Our institutions are mostly marketing with very little science.
That period coincided with V&V providing genuine assessments of techniques and science. Such assessments often highlight problems and areas for further work. This powers the advance of science. It is not the success message our programs seem to require in today’s untrusting environment. As a result, V&V has largely become a way to launder results and supply the positive messaging that supports funding. This is the only thing our management and institutions seem to care about today.
AL and ML are now being added to this toxic mixture. AI and machine learning need the spirit of quality and assessment far more than modeling and simulation do, even more than DNS does. Without it, the likely outcome is an endless parade of hallucinations and bullshit. These will be presented as silver bullets for every kind of problem, while amounting to nothing more than illusions of progress. For applications and decisions of high consequence this is a disaster waiting to unfold.
Right now, everyone is lined up at the trough of money around AI and ML. They are just wanting to feed. Very little proof is needed, and even less is desired. I fear this lack of appetite for V&V is a tell about how little faith people actually have in the work, and an implicit understanding that the evidence will not be positive. Not wanting V&V, or evidence of the error structure in science, is a clear sign that, deep down, people know they are engaged in bullshit. They know that at some level V&V will expose them as liars. They are offering the illusion of precision without being willing to put up the evidence that would demonstrate it.
“The first principle is that you must not fool yourself, and you are the easiest person to fool.” – Richard Feynman
So what should ML and AI do for science, and what should they not?
The way to decide is clear: look at these new tools through the lens of the structure of science. The structure that is invariant to the tools used.
We start with experimental and observational science, then move to theory, which is often mediated through modeling and simulation. ML offers fantastic ways to augment experimental and observational science by analyzing data. This is especially available in vast quantities gathered in new ways. This path also points toward how ML can affect theory. Most notably whether there are trends or aspects of the data that currently resist structured explanation. ML offers new ways to represent and navigage poorly understood aspects of vast datasets.
The same pattern holds for modeling. There are aspects of our world that our existing models do not capture, and these gaps in current theory are exactly where the new tools can reside. In the best case, these ML results will themselves be replaced by structural understanding as much as possible. If a standard structured theory is available, ML is surplus to requirements. That is the frontier we should push on. In the end, if we gain understanding through modeling, the need forML decreases. We will always have areas we do not understand, or that are not amenable to the modeling tools we currently have,. In that sense ML can augment our understanding.
The more controversial point is where these tools have no business playing at all. I have seen plenty of papers aimed at the well-structured, well-posed mathematical parts of a system that ML is trying to replace. That strikes me as utterly ludicrous. If something is well understood, well posed, and well constructed mathematically, ML has no business operating there. It should operate where our theory and methods fail, not where they succeed.
Conservation laws are essential, but they are not always precise, and this matters for machine learning. Conservation of mass, for example, is sacrosanct. As soon as you move to the momentum or energy equations, constitutive modeling starts to play a key role. This is where ML can start to engage, That is especially true in multi-phase flow, where constitutive modeling is woven into nearly every part of the methodology. Parallels exist across different modeling problems.
ML fits into the gaps around constitutive modeling and its variations. Another such area is the setting of initial and boundary conditions for calculations. Our current methods do not fully capture these impacts. Where there are substantial sub-grid effects below the macro scale, ML and AI can help fill those gaps and improve the performance of the methods we use today. The key is to recognize where tools have the potential to address poor aspects. It is also essential to avoid displacing places where the methodology is not improved by these new technologies. Right now, this discernment is lacking.
“The purpose of computing is insight, not numbers.” – R. W. Hamming